






本爬虫代码能够爬取快手短视频的评论,并将获取的评论信息保存到Navicat数据库中。下面是具体的实现方法
找到对应的含有评论信息的内容。
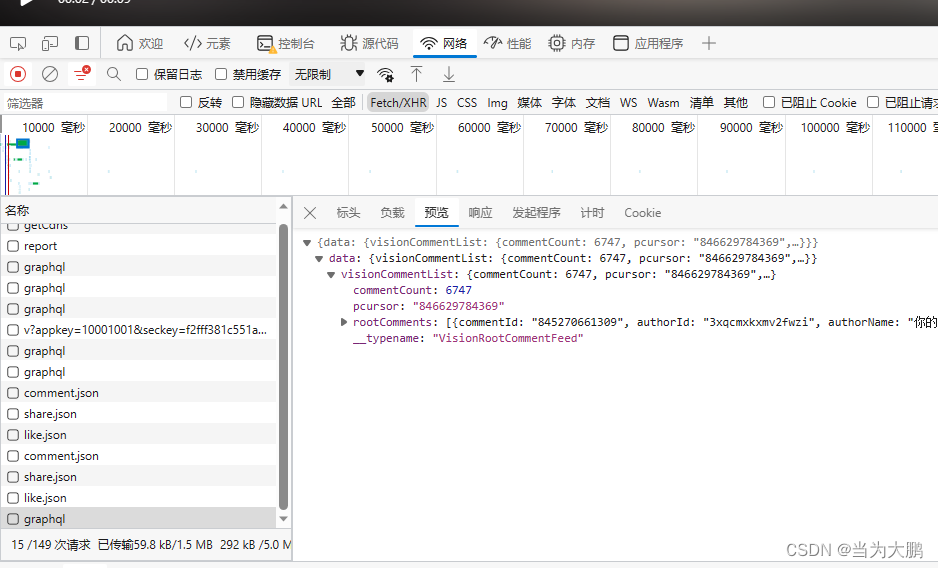
将请求头中的信息替换掉。user-agent替换成你的电脑上的就行,只需要替换一次,但是cookie则是每爬取一个视频就要替换一次,替换成对应视频的cookie。

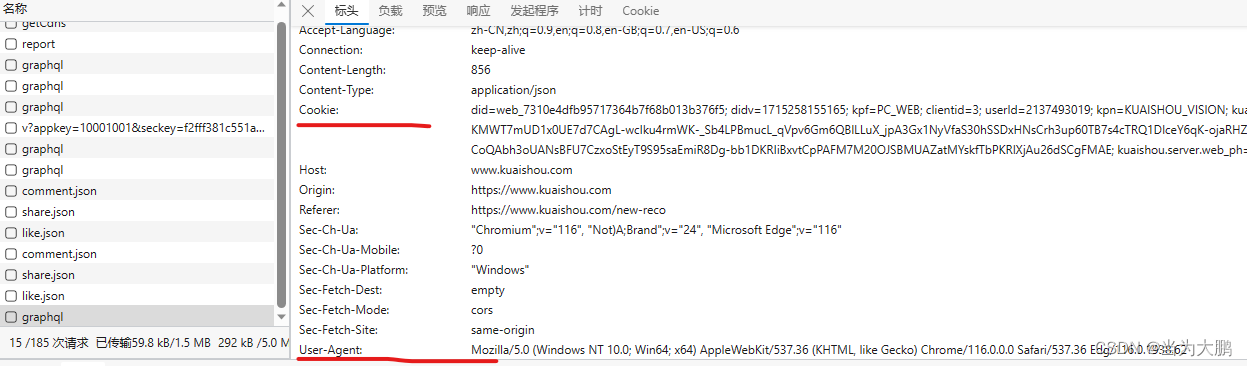
同时下面的内容也需要替换,每个视频都需要替换成对应的。

此部分代码可以删除,对内容没有影响,但需要删除代码中对应的相关内容。

因为爬虫中设置了计数器,可以根据自己的需要对计数器进行修改或者是删除。
# -*- coding: utf-8 -*-
import mysql.connector
import requests
from datetime import datetime
# 设置请求头和Cookie
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36 Edg/116.0.1938.62',
'Cookie': 'did=web_7310e4dfb95717364b7f68b013b376f5; didv=1715258155165; kpf=PC_WEB; clientid=3; userId=2137493019; kuaishou.server.web_st=ChZrdWFpc2hvdS5zZXJ2ZXIud2ViLnN0EqABK7i1EZ9EqUJgJqIYoj1EWt-drCgThaCDtsNOrzUWTs4ikqsOMP2FNjadanLOYiVmjlSIQcSCThAexsyTZpde-HfMHDo9rbSh_WYKX1m5lLcQE3WVXGuwgo72YrdGkvqeqK_8qoqW7mpB3MfFGOne7sqBS8IZ-SxjKi-vdbco7lmuSgkCxMARMLAAw982kRljkLbFyVDZomkt9nCzD9pQGBoSTdCMiCqspRXB3AhuFugv61B-IiBpjVOuTPgVirpFPI4aystNJ7_jgtEDeitYAs0TZUxA0ygFMAE; kuaishou.server.web_ph=ba01f1589ed7da94e3f30bb158534b6ca75b; kpn=KUAISHOU_VISION'
}
# 初始化游标,跟踪查询的游标
w = ''
# 初始化评论计数器
comment_count = 0
def fetch_comments(pcursor):
query = """
query commentListQuery($photoId: String, $pcursor: String) {
visionCommentList(photoId: $photoId, pcursor: $pcursor) {
commentCount
pcursor
rootComments {
commentId
authorName
content
timestamp
likedCount
realLikedCount
liked
subCommentCount
subComments {
commentId
authorName
content
timestamp
likedCount
realLikedCount
liked
}
}
}
}
"""
#variables和payload用来构建一个GraphQL请求,这些变量将作为参数传递给GraphQL服务器,用于查询特定的评论列表
variables = {"photoId": "3xw3mch59gkmkgg", "pcursor": pcursor}
# operationName, variables 和 query。它们一起构成了一个完整的GraphQL请求
payload = {"operationName": "commentListQuery", "variables": variables, "query": query}
try:
response = requests.post('https://www.kuaishou.com/graphql', headers=headers, json=payload)#向指定的url发送post请求
response.raise_for_status()#检查响应的状态码
return response.json()#返回响应的json内容
except requests.RequestException as e:
print(f"请求错误: {e}")
return None
def save_comments_to_database(comments):
global comment_count
# 连接到MySQL数据库
conn = mysql.connector.connect(
user='数据库名称',
password='数据库密码',
host='127.0.0.1',
database='comments'
)
cursor = conn.cursor()
# 插入评论到数据库
for comment in comments:
# 检查评论内容是否以“@”开头
if comment['content'].startswith("@"):
continue
# 将时间戳转换为日期时间格式
timestamp = datetime.fromtimestamp(comment['timestamp'] / 1000.0).strftime('%Y-%m-%d %H:%M:%S')
# 设置类别为“体育类”
category = "游戏类"
url = "https://www.kuaishou.com/short-video/3xfwcega6vgpy8q?authorId=3xyz6ihssxvgany&streamSource=search&searchKey=%E7%8E%8B%E8%80%85&area=searchxxnull"
title = "对抗路的细节"
# 构建SQL插入语句
insert_comment = (
"INSERT INTO cs2 (name, content, time, category, url, title) "
"VALUES (%s, %s, %s, %s, %s, %s)"
)
# 执行SQL语句,插入评论数据
cursor.execute(insert_comment,
(comment['authorName'], comment['content'], timestamp, category, url, title))
comment_count += 1 # 每插入一条评论,计数器加一
if comment_count >= 200: # 当评论数量达到200时,停止插入
break
# 提交事务
conn.commit()
# 关闭游标和连接
cursor.close()
conn.close()
# 主循环,直到没有新的评论或评论数量达到200为止
while comment_count < 200:
comments_data = fetch_comments(w)
if not comments_data:
break
comments = comments_data.get('data', {}).get('visionCommentList', {}).get('rootComments', [])
if not comments:
break
# 保存评论到数据库
save_comments_to_database(comments)
# 更新游标
w = comments[-1].get('commentId', '')


















 1078
1078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









