







本学习笔记源自于B站up主【我是土堆】的视频教程:PyTorch深度学习快速入门教程(绝对通俗易懂!)【小土堆】
本博客是该视频教程中第23-33个视频的详细学习笔记,第1-11个视频、第12-22个视频的详细学习笔记链接如下:
PyTorch深度学习快速入门教程【小土堆】详细学习笔记(第1-11个视频笔记)
PyTorch深度学习快速入门教程【小土堆】详细学习笔记(第12-22个视频笔记)
目录
23、损失函数与反向传播
关于L1Loss和MSELoss函数的讲解:

关于CrossEntropyLoss函数的讲解:
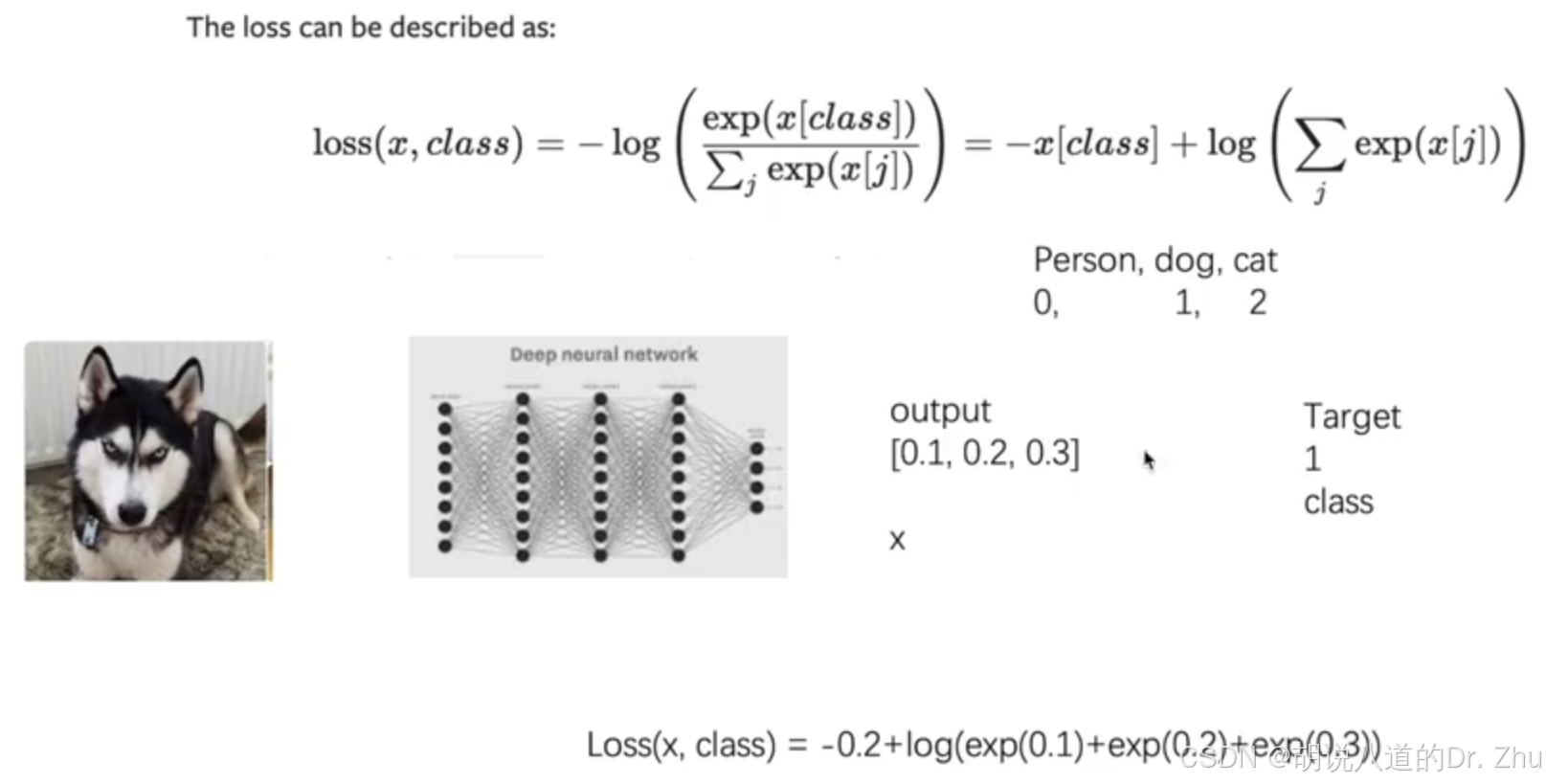
代码如下(建议复制到PyCharm中阅读):
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss(reduction='sum') # 计算 L1损失,并为其设置处理的方式为 “sum”,即将所有损失值加总。
result = loss(inputs, targets)
# 输出为:tensor(2.)
loss_mse = nn.MSELoss() # 计算均方误差损失。
result_mse = loss_mse(inputs, targets)
# 输出为:tensor(1.3333)
print(result)
print(result_mse)
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
x = torch.reshape(x, (1, 3))
loss_cross = nn.CrossEntropyLoss() # 计算交叉熵损失
result_cross = loss_cross(x, y)
print(result_cross)
# 输出为:tensor(1.1019)
接下来是在神经网络中使用损失函数的案例,代码如下(建议复制到PyCharm中阅读):
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./CIFAR10data", train=False, transform=torchvision.transforms.ToTensor(), download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets) # 计算模型输出与真实标签之间的交叉熵损失.
result_loss.backward() # 反向传播误差,计算梯度,以便更新模型参数。
print("ok")24、优化器
所有的优化器都集中在torch.optim里面(找不到torch.optim可以打开这个网址:https://pytorch.org/docs/stable/optim.html)。
使用优化器的简单示例:


代码如下(建议复制到PyCharm中阅读):
import torch
import torchvision
from torch import nn
from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
from torch.optim.lr_scheduler import StepLR
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("./CIFAR10data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Tudui(nn.Module):
def __init__(self):
super(Tudui, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
loss = nn.CrossEntropyLoss()
tudui = Tudui()
optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
# 定义一个随机梯度下降优化器(SGD),用于优化 tudui 的参数,学习率设置为 0.01。
scheduler = StepLR(optim, step_size=5, gamma=0.1)
# 定义学习率调度器,每 5 个 Epoch 将学习率乘以 0.1。
for epoch in range(20):
running_loss = 0.0
for data in dataloader:
imgs, targets = data
outputs = tudui(imgs)
result_loss = loss(outputs, targets)
optim.zero_grad() # 清空优化器中的梯度,以便进行新的反向传播。
result_loss.backward() # 进行反向传播,计算损失对网络参数的梯度。
scheduler.step() # 根据调度策略更新学习率。
running_loss = running_loss + result_loss
print(running_loss)25、现有网络模型的使用及修改
本节使用VGG模型讲解如何加载PyTorch官网中现有的神经网络模型,并修改加载后神经网络模型中的某一层参数(找不到VGG模型可以打开这个网址:)。
代码如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









