







目录
NLP学习笔记系列,欢迎收藏交流:
4.0 机器翻译
将一种自然语言(源语言)转换为另一种自然语言(目标语言)的过程,输入为源语言句子,输出为相应的目标语言的句子。口语中文平均句子长度:7.8个词,书写中文平均句子长度:22.5个词。
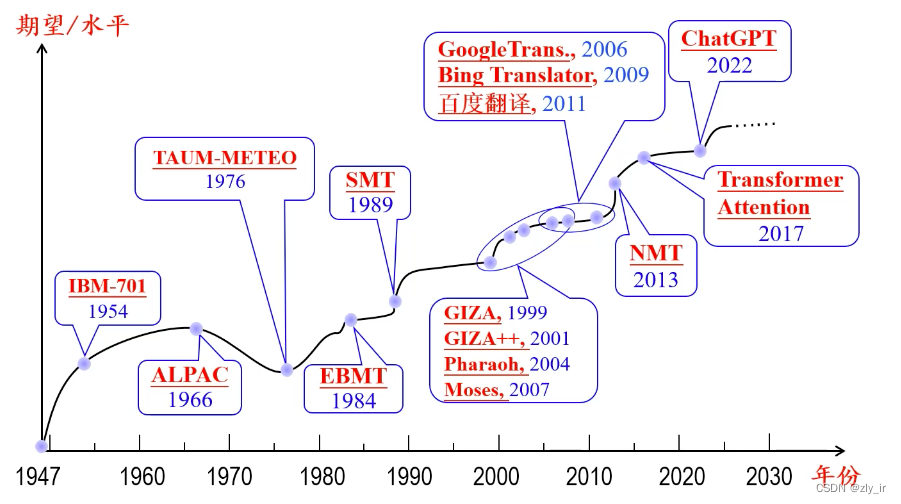
传统的机器翻译:
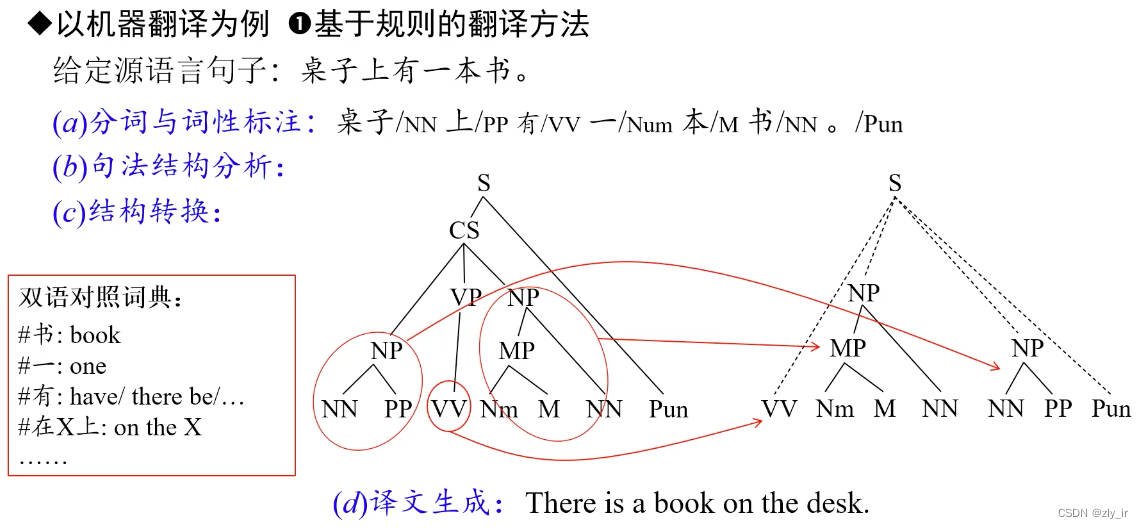



1、基于规则(句法分析,人工编写规则)、基于统计,比较简单,即给定源语言s,求目标语言t的条件概率p(t | s) (1.2 生成式模型中讲到的),效果和现在神经网络的方法相比差的比较多,有兴趣的可以参考:
Nirenburg S. Knowledge-based machine translation[J]. Machine Translation, 1989, 4: 5-24.
Och F J, Ney H. Discriminative training and maximum entropy models for statistical machine translation[C]//Proceedings of the 40th Annual meeting of the Association for Computational Linguistics. 2002: 295-302.
2、基于神经网络的:
最早利用RNN做机器翻译,但RNN的缺点是梯度爆炸无法记住很长的上文,且网络结构注定只能串行输入:
Kalchbrenner N, Blunsom P. Recurrent continuous translation models[C]//Proceedings of the 2013 conference on empirical methods in natural language processing. 2013: 1700-1709.
随后最有名的也是transformer的起源:
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
4.1 文本摘要
4.1.1 抽取式摘要
依据主题、查询词等,找出文章中最相关的n个句子,组成摘要。主题抽取的方式有很多,诸如LDA、KNN等,相关性计算的方式也有很多,可以参考3.0的内容。连贯性较差。
(1)Lead-3算法:一般来说,作者常常会在标题和文章开始就表明主题,因此最简单的方法就是抽取文章中的前几句作为摘要。常用的方法为 Lead-3,即抽取文章的前三句作为文章的摘要。
(2)TextRank:仿造PageRank(PageRank简介,跟不懂的同学们一起分享一下_pagerank中page的意思-CSDN博客)的一种算法,将句子作为节点,使用句子间相似度,构造无向有权边。使用边上的权值迭代更新节点值(PageRank的更新流程),最后选取 N 个得分最高的节点,作为摘要。句子间的相似度计算如下:
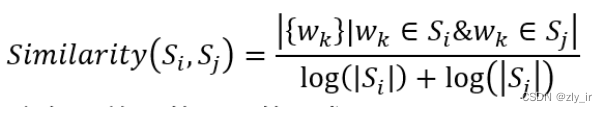
(3)聚类的方式:将文章中的句子视为一个点,按照聚类的方式完成摘要。例如可以对句子先进行向量化(参考第0章中的内容),然后利用K-means(需指定中心数量)对句子进行聚类,然后得到每一个类别距离中心最近的句子作为摘要句。
(4)序列标注的方法(句子分类模型):为原文中的每一个句子打一个二分类标签(0 或 1),0 代表该句不属于摘要,1 代表该句属于摘要。最终摘要由所有标签为 1 的句子构成。基本流程是:句子向量化->分类模型->得到是摘要的句子组成摘要。论文参考:
Nallapati R, Zhai F, Zhou B. Summarunner: A recurrent neural network based sequence model for extractive summarization of documents[C]//Proceedings of the AAAI conference on artificial intelligence. 2017, 31(1).
(5)排序式的摘要生成方法:将(4)中的打分和选择句子放在一个步骤进行,单向 GRU 记录已抽取的句子+双层 MLP打分,每一步训练选择使目标评价函数最大的的句子。
Zhou Q, Yang N, Wei F, et al. Neural document summarization by jointly learning to score and select sentences[J]. arXiv preprint arXiv:1807.02305, 2018.
4.2.2 生成式摘要
基于原文的上小文信息,重新生成m字数内的文章,出现的词不一定要在原文中出现过。
例如:
采用encoder-decoder的方式进行摘要生成,其模型基本部分为基于注意力机制的 Seq2Seq 模型,使用每一步解码的隐层状态与编码器的隐层状态计算权重,最终得到 context 向量,利用 context 向量和解码器隐层状态计算输出概率。
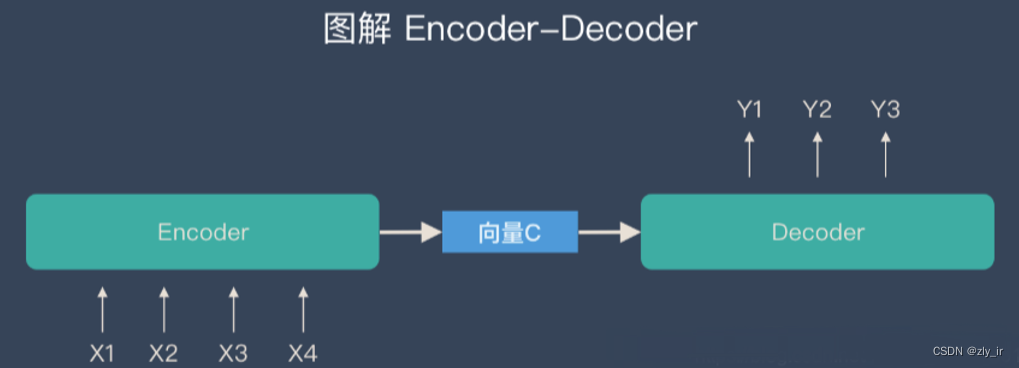
常见的方法有两类,一类是非transformer类型的:
1、Pointer-Generator指针生成器网络,基础模型是LSTM+ Attention,文本 -> embedding -> encoder -> decoder -> 获得概率 -> 映射词表,文献可参考:
See A, Liu P J, Manning C D. Get to the point: Summarization with pointer-generator networks[J]. arXiv preprint arXiv:1704.04368, 2017.
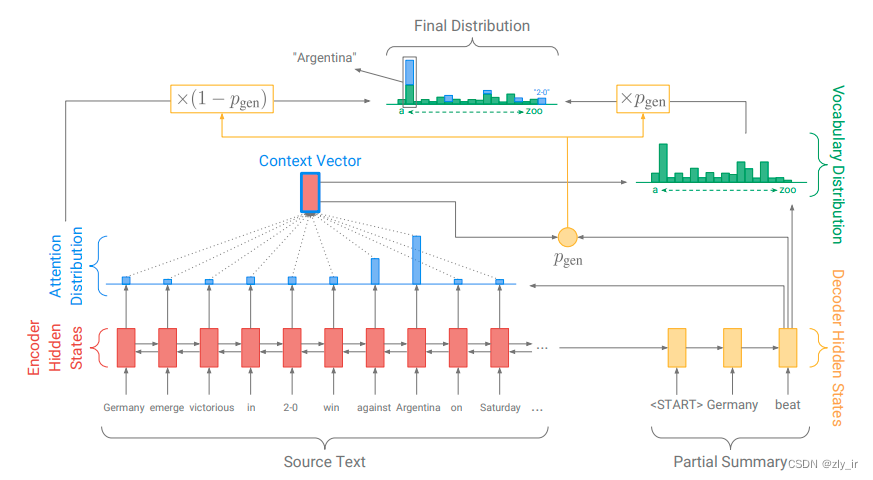
另一类是基于transformer的
1、对话式摘要:Automatic Dialogue Summary Generation for Customer Service
2、BART
3、Pegasus
4、T5(Text-To-Text Transfer Transformer)
5、GPT
4.3 对话系统、问答系统
1、检索式对话和问答系统。对答案进行建库(向量或者字符串),对问题进行特征提取(语义理解、向量化),从库中匹配问题相关的答案,排序,抽取相关答案中的关键词组成最终答案返回给用户。
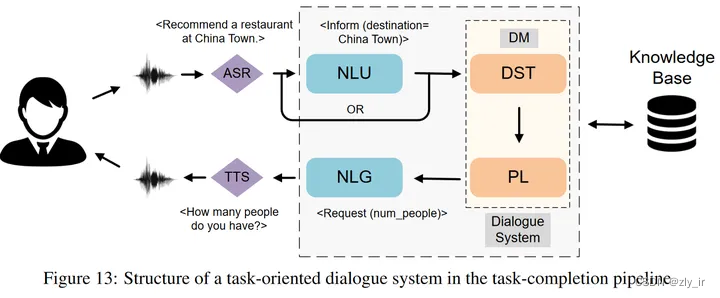
NLU需要完成三个任务,分别是域分类(判断用户的passage属于哪个域)、意图检测(判断用户的需求)和槽位填充(标注出有用的槽位信息)。
2、生成式对话和问答系统。典型的就是ChatGPT,网上有很多介绍的原理,感兴趣的可以参考这篇gpt3的原理介绍文章:The GPT-3 Architecture, on a Napkin















 3884
3884











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









