









模型评估和选择(一)
经验误差和过拟合
错误率(error rate):分类错误的样本数占总样本的比例
“精度”(accuracy):就是1-错误率。。。(为嘛不翻译成正确率)
误差(error ):实际预测输出和样本真实输出之间的差异
训练误差/经验误差(training error):学习器在训练集上的误差
泛化误差(generalization error):在新样本上的误差(就是实际测试的)
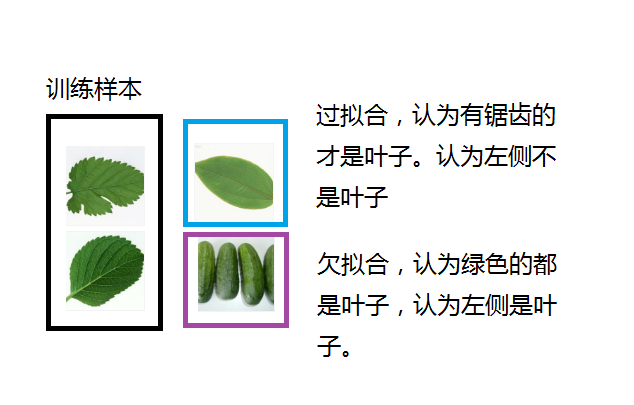
过拟合(overfitting):在训练时把训练误差弄到了最小,某种程度上在真实规律的基础上把训练样本一些自身的“特点”也融入了进来,会导致泛化能力降低(也就是说训练样本结果很好,测试结果不一定好)。
欠拟合(underfitting):和过拟合相反,对训练样本的一般性质没学好
过拟合的原因:最常见的是学习能力过于强大,把很多训练样本特有的属性也学习进来了(解决这个问题挺麻烦的,无法彻底避免,只能“缓解”)
欠拟合的原因:学习能力不行(解决方案:决策树中扩展分支,神经网络学习中增加训练轮数等。)
过拟合无法解决的一个解释:当前的机器学习问题一般都是NP问题甚至更难,如果能用经验误差最小化获得最优解,那么就构造性证明了“P=NP”;如果相信“P≠NP”,过拟合就不可避免。
P,NP概念解释地址:http://blog.csdn.net/zmdsjtu/article/details/52700872
一个过拟合和欠拟合直观的例子:
涉及的关键问题是如何选择模型,我们需要让泛化误差最小,但又不能获得泛化误差,等下回分解。

最后祝大家学习愉:)
















 7159
7159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











