







欧氏距离:最为常见,可以理解为欧式空间里两点的直线距离。
两个点 A = (a[1],a[2],…,a[n]) 和 B = (b[1],b[2],…,b[n]) 之间的距离 ρ(A,B) 定义为下面的公式:
ρ(A,B) =√ [ ∑( a[i] - b[i] )^2 ] (i = 1,2,…,n)
汉明距离:两个字符串对应位置不一样的个数。
汉明距离是以理查德·卫斯里·汉明的名字命名的。在信息论中,两个等长字符串之间的汉明距离是两个字符串对应位置的不同字符的个数。换句话说,它就是将一个字符串变换成另外一个字符串所需要替换的字符个数。例如:
1011101 与 1001001 之间的汉明距离是 2。
2143896 与 2233796 之间的汉明距离是 3。
"toned" 与 "roses" 之间的汉明距离是 3。马氏距离:表示数据的协方差距离。计算两个样本集相似度的距离
对于一个均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为sqrt( (x-μ)'Σ^(-1)(x-μ) )。--------------------------参考自:地址-------------------------
对于马氏距离,本人研究了一下,虽然看上去公式很简单的,但是其中存在很多模糊的东西,例如有很多教科书以及网络上的简要说明,下面以维基百科作为引用:
马氏距离是由印度统计学家马哈拉诺比斯(P. C. Mahalanobis)提出的,表示数据的协方差距离。它是一种有效的计算两个未知样本集的相似度的方法。与欧氏距离不同的是它考虑到各种特性之间的联系(例如:一条关于身高的信息会带来一条关于体重的信息,因为两者是有关联的)并且是尺度无关的(scale-invariant),即独立于测量尺度。 对于一个均值为,协方差矩阵为Σ的多变量矢量,其马氏距离为
- 马氏距离也可以定义为两个服从同一分布并且其协方差矩阵为Σ的随机变量与的差异程度:
如果协方差矩阵为单位矩阵,马氏距离就简化为欧式距离;如果协方差矩阵为对角阵,其也可称为正规化的马氏距离。
其中σi是xi的标准差。
------------------------------------------------------------------------------------------------------余弦距离:两个向量的夹角作为一种判别距离的度量。
曼哈顿距离:两点投影到各轴上的距离总和。
切比雪夫距离:两点投影到各轴上距离的最大值。
以(x1,y1)和(x2,y2)二点为例,其切比雪夫距离为max(|x2-x1|,|y2-y1|)。标准化欧氏距离: 欧式距离里每一项除以标准差……
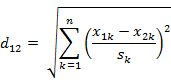
参考:地址
闵可夫斯基距离:如下,p=1时为曼哈顿距离,2为欧式距离,趋于无穷为切比雪夫距离。
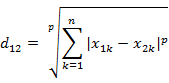
巴氏距离:常在类分类中测量类的可分离性。
在统计学中,巴氏距离(巴塔恰里雅距离 / Bhattacharyya distance)用于测量两离散概率分布。它常在分类中测量类之间的可分离性。在同一定义域X中,概率分布p和q的巴氏距离定义如下:
(1)离散概率分布
对于在X数域上的两个离散概率分布p和q,巴氏距离定义为
DB(p,q) = -ln(BC(p,q))
其中
BC(p,q) = ∑√p(x)q(x)
BC被称作Bhattacharyya系数(巴氏系数)
0≤BC≤1q且0≤DB≤∞
(2)连续概率分布
在连续情形中,Bhattacharyya系数如下定义:
BC(p,q) = ∫√p(x)q(x)dx
0≤BC≤1q且0≤DB≤∞
两种情形中,巴氏距离DB均不满足三角不等式杰卡德距离& 杰卡德相似系数:衡量两个集合的相似程度


相关系数& 相关距离
(1) 相关系数的定义

相关系数是衡量随机变量X与Y相关程度的一种方法,相关系数的取值范围是[-1,1]。相关系数的绝对值越大,则表明X与Y相关度越高。当X与Y线性相关时,相关系数取值为1(正线性相关)或-1(负线性相关)。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 相关程度
0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关(2)相关距离的定义

信息熵:很乱很分散就大,反之小。
信息熵并不属于一种相似性度量。那为什么放在这篇文章中啊?这个。。。我也不知道。 (╯▽╰)
信息熵是衡量分布的混乱程度或分散程度的一种度量。分布越分散(或者说分布越平均),信息熵就越大。分布越有序(或者说分布越集中),信息熵就越小。
计算给定的样本集X的信息熵的公式:

参数的含义:
n:样本集X的分类数
pi:X中第i类元素出现的概率
信息熵越大表明样本集S分类越分散,信息熵越小则表明样本集X分类越集中。。当S中n个分类出现的概率一样大时(都是1/n),信息熵取最大值log2(n)。当X只有一个分类时,信息熵取最小值0
好困……

















 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











