








[Pytorch] 前向传播和反向传播示例_反向传播和前向传播的网络程序-CSDN博客
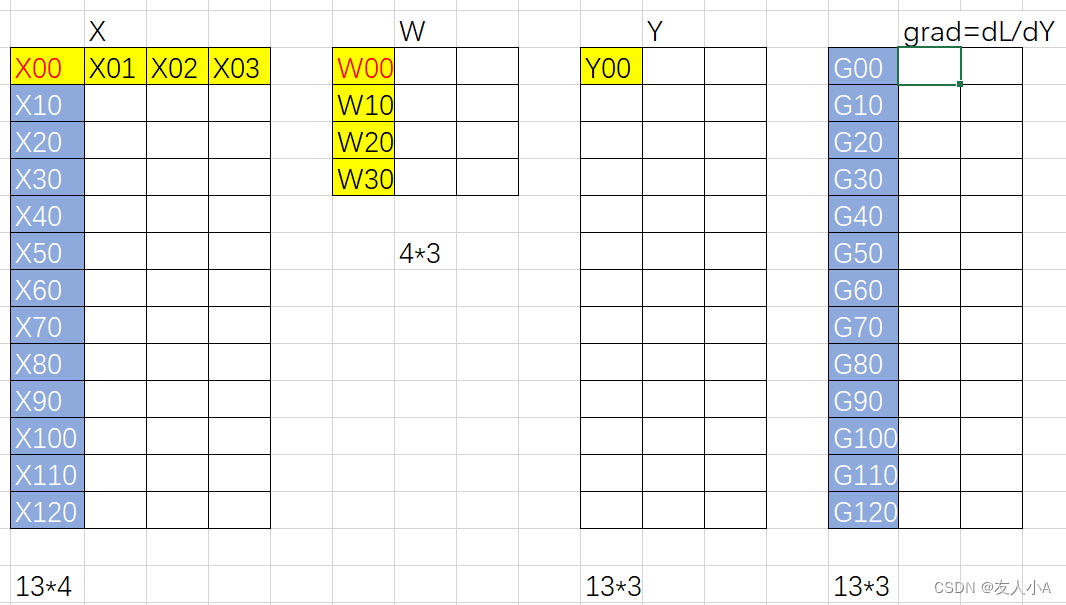
→ Y(i,j) = X(i,0)*W(0, j) + X(i, 1)*W(1,j) + X(i,2) * W(2,j) + X(i, 3)*W(3,j)
x=0,1,2,3,4,5,6,7,8,9,10,11,12; j=0,1, 2
如:
Y(0,0) = X(0,0)*W(0, 0) + X(0, 1)*W(1,0) + X(0,2) * W(2,0) + X(0, 3)*W(3,0)
Y(1,2) = X(1,0)*W(0, 2) + X(1, 1)*W(1,2) + X(1,2) * W(2,2) + X(1, 3)*W(3,2)
→ loss = Lossfun(Y)
→ 损失函数backward得到matmul反向的输入grad = d loss /dY
→ W.grad = d loss / dW = dloss/dY * dY/dW = grad * dY/dW
→ 前向计算中若把W作为变量:Y(i,j) = X(i,0)*W(0, j) + X(i, 1)*W(1,j) + X(i,2) * W(2,j) + X(i, 3)*W(3,j), i=0,1,2,3,4,5,6,7,8,9,10,11,12
→ W(0,j)的梯度由 X(i,0) i=0,1,2,3,4,5,6,7,8,9,10,11,12共同组成,但是这12个数字没有直接的参与关系,而是分别对应Y(i,j)
→ Y(i, j) = X(i, 0) * W(0, j) + ....
所以在计算W(0,j)的梯度时,我们需要遍历 i (取值范围为 0 到 12),将 Y(i,j) 对 W(0,j) 的偏导数乘以 grad, 再累加起来即可得到 W(0,j) 的梯度。
这样就是 W(0,j).grad = X(0,0) * grad(0,j) + X(1,0) * grad(1,j) + ... + X(12,0) * grad(12,j) = mma(Transpose(X), grad)
—————— 》因此W.grad要取完整的X列(转置后的行),和grad的列 ——》不管TP按照什么切分,X都能保持完整的列,因此不需要通信
→ X.grad = dloss/dX = dloss/dY * dY/dX = grad * dY/dX
→ 前向计算中若把X作为变量:Y(i,j) = X(i,0)*W(0, j) + X(i, 1)*W(1,j) + X(i,2) * W(2,j) + X(i, 3)*W(3,j), j=0,1,2
X(i,0).grad = grad(i, 0) * W(0,0) + grad(i,1)*W(0,1) + grad(i,2)*W(0,2) = mma(grad, W)
—————— 》因此X.grad要取完整W行,和grad列 ——》若按照列切分,则需要all-gather回来















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









