









ACL2016 《通过双向 LSTM-CNNs-CRF 的端到端序列标记》
主要内容:
该文章提出了一种不需要对数据集进行任何特征工程或预处理就可以实现生成序列标记的任务的方法。
流程:
↓
卷积神经网络:提取单词字符级表示
↓
BLSTM:单向LSTM只能获取过去信息,无法获取未来信息,所以双向LSTM的基本思想是将每个序列向前和向后呈现到两个单独的隐藏状态,以分别捕获过去和未来的信息。 然后将两个隐藏状态连接起来形成最终的输出。
↓
CRF:使用条件随机场 (CRF) (Lafferty et al., 2001) 联合建模标签序列,而不是独立解码每个标签。
摘要
最先进的序列标记系统传统上需要大量手工制作特征和数据预处理形式的特定于任务的知识。 在本文中,我们介绍了一种新颖的中性网络架构,该架构通过使用双向 LSTM、CNN 和 CRF 的组合,自动受益于词级和字符级表示。 我们的系统是真正的端到端,不需要特征工程或数据预处理,因此适用于广泛的序列标记任务。 我们针对两个序列标记任务在两个数据集上评估我们的系统——Penn Treebank WSJ 语料库用于词性 (POS) 标记和 CoNLL 2003 语料库用于命名实体识别 (NER)。 我们在两个数据集上都获得了最先进的性能——POS 标记准确率为 97.55%,NER 准确率为 91.21%。
1 引言
语言序列标记,例如词性 (POS) 标记和命名实体识别 (NER),是深度语言理解的第一阶段之一,其重要性已在自然语言处理社区中得到广泛认可。自然语言处理 (NLP) 系统,如句法解析和实体共指解析正变得越来越复杂,部分原因是利用了 POS 标记或 NER 系统的输出信息。
大多数传统的高性能序列标注模型是线性统计模型,包括隐马尔可夫模型 (HMM) 和条件随机场 (CRF) (Ratinov and Roth, 2009; Passos et al., 2014; Luo et al. , 2015),它严重依赖手工制作的功能和特定于任务的资源。 例如,英语 POS 标记受益于精心设计的单词拼写功能; 正字法特征和外部资源(例如地名词典)在 NER 中被广泛使用。 然而,这种特定于任务的知识的开发成本很高(Ma and Xia,2014),使得序列标记模型难以适应新任务或新领域。
在过去几年中,非线性神经网络以分布式词表示作为输入,也称为词嵌入,已广泛应用于 NLP 问题并取得了巨大成功。 科洛伯特等人2011年提出了一个简单但有效的前馈中性网络,该网络通过在固定大小的窗口中使用上下文来独立地对每个单词的标签进行分类。 最近,循环神经网络 (RNN)(Goller 和 Kuchler,1996)及其变体,如长短期记忆(LSTM)(Hochreiter 和 Schmidhuber,1997;Gers 等,2000)和门控循环单元 (GRU)(Cho 等人,2014 年)在序列数据建模方面取得了巨大成功。已经提出了几种基于 RNN 的神经网络模型来解决序列标记任务,如语音识别(Graves 等人,2013 年)、词性标注(Huang 等人,2015 年)和 NER(Chiu 和 Nichols,2015 年;Hu 等人) al., 2016),实现与传统模型相比的竞争性能。 然而,即使使用分布式表示作为输入的系统也使用这些来增强而不是替换手工制作的特征(例如单词拼写和大写模式)。 当模型仅依赖于神经嵌入时,它们的性能会迅速下降。
在本文中,我们提出了一种用于序列标记的神经网络架构。 它是一个真正的端到端模型,不需要特定于任务的资源、特征工程或数据预处理,以及在未标记语料库上预训练的词嵌入。 因此,我们的模型可以轻松应用于不同语言和领域的各种序列标记任务。 我们首先使用卷积神经网络 (CNNs) (LeCun et al., 1989) 将单词的字符级信息编码为其字符级表示。 然后我们结合字符和单词级别的表示,并将它们输入双向 LSTM(BLSTM)以对每个单词的上下文信息进行建模。在 BLSTM 之上,我们使用顺序 CRF 来联合解码整个句子的标签。 我们在两个语言序列标记任务上评估我们的模型 - Penn Treebank WSJ 上的 POS 标记(Marcus 等,1993),以及来自 CoNLL 2003 共享任务的英语数据的 NER(Tjong Kim Sang 和 De Meulder,2003)。 我们的端到端模型优于之前最先进的系统,POS 标记准确率为 97.55%,NER 准确率为 91.21%。 这项工作的贡献是(i)提出了一种用于语言序列标记的新型神经网络架构。 (ii) 在两个经典 NLP 任务的基准数据集上对该模型进行实证评估。 (iii) 通过这个真正的端到端系统实现最先进的性能。
2 神经网络架构
在本节中,我们将描述神经网络架构的组件(层)。 我们从下到上一个一个地介绍我们神经网络中的神经层。
2.1 用于字符级表示的CNN
先前的研究(Santos 和 Zadrozny,2014 年;Chiu 和 Nichols,2015 年)表明,CNN 是一种从单词字符中提取形态信息(如单词的前缀或后缀)并将其编码为神经表征的有效方法。 图 1 显示了我们用来提取给定单词的字符级表示的 CNN。 CNN 类似于 Chiu 和 Nichols (2015) 中的那个,除了我们只使用字符嵌入作为 CNN 的输入,没有字符类型特征。 在将字符嵌入输入到 CNN 之前,应用了一个 dropout 层(Srivastava 等人,2014 年)。

2.2 Bi-directional LSTM
2.2.1 LSTM单元
循环神经网络 (RNN) 是一个强大的联结模型系列,可通过图中的循环捕获时间动态。 尽管从理论上讲,RNN 能够捕获长距离依赖关系,但在实践中,它们会由于梯度消失/爆炸问题而失败(Bengio 等人,1994 年;Pascanu 等人,2012 年)。LSTM(Hochreiter 和 Schmidhuber,1997)是 RNN 的变体,旨在解决这些梯度消失问题。 基本上,一个 LSTM 单元由三个乘法门组成,它们控制着遗忘信息和传递到下一个时间步的信息比例。 图 2 给出了 LSTM 单元的基本结构。

形式上,在时间 t 更新 LSTM 单元的公式是:
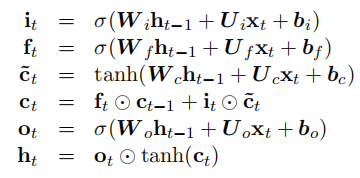
其中 σ 是逐元素 sigmoid 函数,⊙是逐元素乘积。
x
t
x_t
xt 是时间 t 的输入向量(例如词嵌入),而
h
t
h_t
ht 是隐藏状态(也称为输出)向量,用于存储时间 t(和之前)的所有有用信息。
U
i
,
U
f
,
U
c
,
U
o
U_i, U_f , U_c, U_o
Ui,Uf,Uc,Uo 表示输入 xt 的不同门的权重矩阵,
W
i
,
W
f
,
W
c
,
W
o
W_i,W_f ,W_c,W_o
Wi,Wf,Wc,Wo 是隐藏状态
h
t
h_t
ht 的权重矩阵。 $b_i, b_f , b_c, b_o $表示偏置向量。 应该注意的是,我们的 LSTM 公式中不包括窥视孔连接(Gers 等人,2003 年)。
2.2.2 BLSTM
对于许多序列标记任务,访问过去(左)和未来(右)上下文是有益的。 然而,LSTM 的隐藏状态 h t h_t ht 只从过去获取信息,对未来一无所知。 双向 LSTM (BLSTM) 是一种优雅的解决方案,其有效性已被先前的工作 (Dyer 等人,2015) 证明。 基本思想是将每个序列向前和向后呈现到两个单独的隐藏状态,以分别捕获过去和未来的信息。 然后将两个隐藏状态连接起来形成最终的输出。
2.3 CRF
对于序列标记(或一般结构化预测)任务,考虑邻域中标签之间的相关关系并联合解码给定输入句子的最佳标签链是有益的。 例如,在 POS 标记中,形容词后面更可能是名词而不是动词,而在具有标准 BIO2 的 NER 中,一个符号(Tjong Kim Sang 和 Veenstra,1999)I-ORG 不能跟在 I-PER 之后。 因此,我们使用条件随机场 (CRF) (Lafferty et al., 2001) 联合建模标签序列,而不是独立解码每个标签。
形式上,我们使用
z
=
z
1
,
⋅
⋅
⋅
,
z
n
z = {z_1, · · · , z_n}
z=z1,⋅⋅⋅,zn 来表示一个通用输入序列,其中
z
i
z_i
zi 是第 i 个单词的输入向量。
y
=
y
1
,
⋅
⋅
⋅
,
y
n
y = {y_1, · · · , y_n}
y=y1,⋅⋅⋅,yn 表示 z 的一般标签序列。 Y(z) 表示 z 的可能标签序列集。 序列 CRF 的概率模型定义了给定 z 的所有可能标签序列 y 的条件概率 p(y|z;W, b) 族,形式如下:

其中
ψ
i
(
y
′
,
y
,
z
)
=
e
x
p
(
W
y
′
,
y
T
z
i
+
b
y
′
,
y
)
ψi(y' , y, z) = exp(W^T_{y', y}z_i + b_{y', y})
ψi(y′,y,z)=exp(Wy′,yTzi+by′,y)是势函数,
W
y
′
,
y
T
W^T_{y', y}
Wy′,yT 和
b
y
′
,
y
b_{y', y}
by′,y 分别是标签对
(
y
′
,
y
)
(y' , y)
(y′,y) 对应的权重向量和偏差。
对于 CRF 训练,我们使用最大条件似然估计。 对于训练集
(
z
i
,
y
i
)
{(z_i, y_i)}
(zi,yi),似然的对数(也称为对数似然)由下式给出:

最大似然训练选择参数以使对数似然 L(W, b) 最大化。
解码就是搜索条件概率最高的标签序列y∗:

对于序列CRF模型(只考虑两个连续标签之间的相互作用),采用Viterbi算法可以有效地解决训练和解码问题。
2.4 BLSTM-CNNs-CRF
最后,我们通过将 BLSTM 的输出向量输入 CRF 层来构建我们的神经网络模型。 图 3 详细说明了我们网络的架构。

对于每个单词,字符级表示由图 1 中的 CNN 计算,字符嵌入作为输入。 然后将字符级表示向量与词嵌入向量连接起来,输入到 BLSTM 网络中。 最后,BLSTM 的输出向量被馈送到 CRF 层以联合解码最佳标签序列。 如图 3 所示,在 BLSTM 的输入和输出向量上都应用了 dropout 层。 实验结果表明,使用 dropout 显着提高了我们模型的性能(详见第 4.5 节)。
3 网络训练
在本节中,我们提供有关训练神经网络的详细信息。 我们使用 Theano 库(Bergstra 等,2010)实现神经网络工作。 单个模型的计算在 GeForce GTX TITAN X GPU 上运行。 使用本节中讨论的设置,模型训练需要大约 12 小时的 POS 标记和 8 小时的 NER。
3.1 参数初始化
词嵌入。 我们使用斯坦福大学公开可用的 GloVe 100 维嵌入 dings1 训练了来自维基百科和网络文本的 60 亿个单词(Pennington 等人,2014 年)
我们还对另外两组已发布的嵌入进行了实验,即在维基百科和路透社 RCV-1 语料库上训练的 Senna 50 维嵌入 2(Collobert 等人,2011),以及在 1000 亿字上训练的 Google Word2Vec 300 维嵌入 3 来自 Google 新闻(Mikolov 等人,2013 年)。为了测试预训练词嵌入的有效性,我们试验了随机初始化的 100 维嵌入,其中嵌入从范围 [
−
3
d
i
m
-\sqrt{3\over{dim}}
−dim3,
+
3
d
i
m
+\sqrt{3\over{dim}}
+dim3] 统一采样,其中 dim 是嵌入的维度。 4.4 节讨论了不同词嵌入的性能。
字符嵌入。 字符嵌入使用来自 [
−
3
d
i
m
-\sqrt{3\over{dim}}
−dim3,
+
3
d
i
m
+\sqrt{3\over{dim}}
+dim3] 的统一样本进行初始化,其中我们设置 dim = 30。
权重矩阵和偏置向量。 矩阵参数使用来自[
−
6
r
+
c
-\sqrt{6\over{r+c}}
−r+c6,
+
6
r
+
c
+\sqrt{6\over{r+c}}
+r+c6] 的均匀样本随机初始化,其中 r 和 c 是结构中的行数和列数(Glorot 和 Bengio,2010)。 偏差向量被初始化为零,除了 LSTM 中遗忘门的偏差 bf,它被初始化为 1.0 (Jozefowicz et al., 2015)。
3.2 优化算法
使用批量大小为 10 和动量 0.9 的小批量随机梯度下降 (SGD) 执行参数优化。 我们选择初始学习率
η
0
η_0
η0(对于 POS 标签,
η
0
η_0
η0 = 0.01,对于 NER 为 0.015,参见第 3.3 节。),并且学习率在每个训练时期更新为
η
t
=
η
0
/
(
1
+
ρ
t
)
η_t = η_0/(1 + ρt)
ηt=η0/(1+ρt) ,衰减率
ρ
=
0.05
ρ = 0.05
ρ=0.05,
t
t
t 是已完成的 epoch 数。为了减少“梯度爆炸”的影响,我们使用 5.0 的梯度裁剪(Pascanu 等,2012)。 我们探索了其他更复杂的优化算法,例如 AdaDelta (Zeiler, 2012)、Adam (Kingma and Ba, 2014) 或 RMSProp (Dauphin et al., 2015),但它们都没有在我们的 初步实验。
提前停止。 我们根据验证集的性能使用提前停止(Giles,2001;Graves 等,2013)。 根据我们的实验,“最佳”参数出现在大约 50 个 epochs。
微调。 对于每个嵌入,我们微调初始嵌入,通过反向传播梯度在神经网络模型的梯度更新期间修改它们。 这种方法的有效性之前已经在序列和结构化预测问题中进行了探索(Col lobert 等人,2011 年;Peng 和 Dredze,2015 年)。
dropout训练。 为了减轻过度拟合,我们应用 dropout 方法(Srivastava 等人,2014 年)来规范我们的模型。 如图 1 和图 3 所示,我们在输入到 CNN 之前对字符嵌入以及 BLSTM 的输入和输出向量应用 dropout。 在所有实验中,我们将所有 dropout 层的 dropout 率固定为 0.5。 使用 dropout 后,我们获得了模型性能的显着改进(参见第 4.5 节)。
3.3 调整超参数
表 1 总结了为所有实验选择的超参数。 我们通过随机搜索调整开发集上的超参数。 由于时间限制,在整个超参数空间中进行随机搜索是不可行的。 因此,对于 POS 标记和 NER 的任务,我们尝试共享尽可能多的超参数。 请注意,除了初始学习率之外,这两个任务的最终超参数几乎相同。 我们将 LSTM 的状态大小设置为 200。调整这个参数并没有显着影响我们模型的性能。 对于 CNN,我们使用 30 个过滤器,窗口长度为 3。

4 实验
4.1 数据集
如前所述,我们在两个序列标记任务上评估我们的神经网络工作模型:POS 标记和 NER。
POS 标记。 对于英语 POS 标签,我们使用 Penn Treebank (PTB) (Marcus et al., 1993) 的 Wall Street Journal (WSJ) 部分,其中包含 45 个不同的 POS 标签。 为了与之前的工作进行比较,我们采用标准分割——第 0-18 节作为训练数据,第 19-21 节作为开发数据,第 22-24 节作为测试数据(Manning,2011;Søgaard,2011)。
NER。 对于 NER,我们对来自 CoNLL 2003 共享任务(Tjong Kim Sang 和 De Meulder,2003)的英文数据进行了实验。 该数据集包含四种不同类型的命名实体:PERSON、LOCATION、ORGA NIZATION 和 MISC。 我们使用 BIOES 标记方案而不是标准 BIO2,因为之前的研究报告了该方案的显着改进(Ratinov 和 Roth,2009 年;Dai 等人,2015 年;Lample 等人,2016 年)。
语料库统计数据如表 2 所示。我们没有对数据集进行任何预处理,让我们的系统真正做到了端到端。

4.2 主要结果
我们首先运行实验,通过消融研究剖析我们神经网络架构的每个组件(层)的有效性。 我们将性能与三个基线系统进行比较——BRNN,双向 RNN; BLSTM,双向 LSTM 和 BLSTM-CNN,BLSTM 与 CNN 的组合,用于对字符级信息进行建模。 所有这些模型都使用斯坦福的 GloVe 100 维词嵌入和相同的超参数运行,如表 1 所示。根据表 3 所示的结果,BLSTM 在两个任务的所有评估指标上都获得了比 BRNN 更好的性能。 BLSTM-CNN 模型明显优于 BLSTM 模型,表明字符级表示对于语言序列标记任务很重要。 这与之前工作报告的结果一致(Santos 和 Zadrozny,2014 年;Chiu 和 Nichols,2015 年)。 最后,通过添加用于联合解码的 CRF 层,我们在所有指标的 POS 标记和 NER 方面都比 BLSTM CNN 模型实现了显着改进。 这表明联合解码标签序列可以显着提高神经网络模型的最终性能。

4.3 与以往工作的比较
4.3.1 POS 标记
表 4 说明了我们的 POS 标记模型的结果,以及用于比较的七个以前的最佳性能系统。 我们的模型明显优于 Senna (Collobert et al., 2011),后者是一种使用大写和离散后缀特征以及数据预处理的前馈神经网络模型。 此外,我们的模型比“CharWNN”(Santos 和 Zadrozny,2014)的准确度提高了 0.23%,这是一个基于 Senna 的神经网络模型,也使用 CNN 对字符级表示进行建模。这证明了 BLSTM 对序列数据建模的有效性以及结构化预测模型联合解码的重要性。

与传统的统计模型相比,我们的系统实现了最先进的准确性,比 Søgaard (2011) 先前报告的最佳结果提高了 0.05%。 应该指出的是,黄等人在2015年还评估了他们的 BLSTM-CRF 模型,用于在 WSJ 语料库上进行 POS 标记。 但是他们对训练/开发/测试数据集使用了不同的划分。 因此,他们的结果不能与我们的结果直接比较。
4.3.2 NER
表 5 显示了 NER 先前模型在来自 CoNLL-2003 共享任务的测试数据集上的 F1 分数。 出于比较的目的,我们将他们的结果与我们的结果一起列出。 与 POS 标记的观察结果类似,我们的模型在 Senna 和其他三个神经模型(即 Huang 等人提出的 LSTM-CRF)上取得了显着的改进。 (2015)、Chiu 和 Nichols (2015) 提出的 LSTM-CNN,以及 Lample 等人提出的 LSTM CRF。 (2016)。 黄等人。 (2015) 使用离散拼写、POS 和上下文特征,Chiu 和 Nichols (2015) 使用字符类型、大写和词典特征,并且所有三个模型都使用了一些特定于任务的数据预处理,而我们的模型没有 不需要任何精心设计的特征或数据预处理。我们必须指出,Chiu 和 Nichols (2015) 报告的结果 (90.77%) 与我们的无法相比,因为他们的最终模型是在训练和开发数据集的组合数据集4上训练的。

据我们所知,之前在 CoNLL 2003 数据集上报告的最佳 F1 分数 (91.20) 是由联合 NER 和实体链接模型(Luo 等人,2015 年)得出的。 该模型使用了许多手工制作的功能,包括词干和拼写功能、POS 和块标签、WordNet 集群、Brown 集群,以及外部知识库,如 Freebase 和 Wikipedia。 我们的端到端模型将此模型略微改进了 0.01%,从而产生了最先进的性能。
4.4 词嵌入
如第 3.1 节所述,为了测试预训练词嵌入的重要性,我们对不同的公开发布的词嵌入集以及随机采样方法进行了实验,以初始化我们的模型。 表 6 给出了三种不同词嵌入的性能,以及随机采样的一种。 根据表 6 中的结果,与使用随机嵌入的模型相比,使用预训练词嵌入的模型获得了显着的改进。 比较这两个任务,NER 比 POS 标记更依赖于预训练的嵌入。 这与之前工作报告的结果一致(Collobert 等,2011;Huang 等,2015;Chiu 和 Nichols,2015)。

对于不同的预训练嵌入,Stanford 的 GloVe 100 维嵌入在这两个任务上都取得了最好的结果,与 Senna 50 维嵌入相比,POS 准确度提高了 0.1%,NER F1 得分提高了 0.9%。这与 Chiu 和 Nichols (2015) 报告的结果不同,其中 Senna 在 NER 上的表现略好于其他嵌入。 Google 的 Word2Vec 300 维嵌入在 POS 标记上获得与 Senna 相似的性能,但仍略落后于 GloVe。 但对于 NER 来说,Word2Vec 上的表现远远落后于 GloVe 和 Senna。 Word2Vec 不如其他两个嵌入 NER 的可能原因是词汇不匹配——Word2Vec 嵌入以区分大小写的方式进行训练,排除了许多常见符号,如标点符号和数字。 由于我们不使用任何数据预处理来处理此类常见符号或生僻字,因此使用 Word2Vec 可能会出问题。
4.5 Dropout的影响
表 7 比较了每个数据集有和没有 dropout 层的结果。 所有其他超参数与表 1 中的相同。我们观察到这两个任务都有本质的改进。 它证明了 dropout 在减少过拟合方面的有效性。

4.6 OOV误差分析
为了更好地理解我们模型的行为,我们对词外词 (OOV) 进行了错误分析。 具体来说,我们将每个数据集划分为四个子集——词汇表内词 (IV)、训练外词汇 (OOTV)、嵌入词汇外词 (OOEV) 和两者外词汇 字 (OOBV)。 如果一个词同时出现在训练和嵌入词汇中,那么它就被认为是 IV,而如果都没有出现,则被认为是 OOBV。OOTV词是没有出现在训练集中但出现在嵌入词汇中的词,而OOEV是没有出现在嵌入词汇中而是出现在训练集中的词。 对于NER,如果至少存在一个不在训练集中的词和至少一个不在嵌入词汇表中的词,则一个实体被认为是OOBV,其他三个子集可以用类似的方式完成。 表 8 形成了每个语料库上分区的统计信息。 我们使用的嵌入是斯坦福大学的 GloVe,维度为 100,与第 4.2 节相同。

表 9 说明了我们的模型在不同单词子集上的性能,以及用于比较的基线 LSTM-CNN 模型。 最大的改进出现在两个语料库的 OOBV 子集上。 这表明通过添加 CRF 进行联合解码,我们的模型在训练集和嵌入集之外的词上更强大。

5 相关工作
近年来,已经提出了几种不同的神经网络架构并成功应用于语言序列标记,例如词性标注、分块和 NER。 在这些神经架构中,与我们的模型最相似的三种方法是 Huang 等人提出的 BLSTM-CRF 模型。 (2015)、Chiu 和 Nichols 的 LSTM-CNNs 模型 (2015) 以及 Lample 等人的 BLSTM-CRF。 (2016)。
黄等人。 (2015) 使用 BLSTM 进行词级表示,使用 CRF 进行联合标签解码,这与我们的模型类似。 但是他们的模型和我们的模型之间有两个主要区别。 首先,他们没有使用 CNN 来对字符级信息进行建模。 其次,他们将他们的神经网络模型与手工制作的特征相结合,以提高他们的性能,使他们的模型不是一个端到端的系统。Chiu 和 Nichols (2015) 提出了 BLSTM 和 CNN 的混合体来对字符级和单词级表示进行建模,这类似于我们模型中的前两层。 他们在 NER 上评估了他们的模型并取得了有竞争力的性能。 我们的模型与该模型的主要区别在于使用 CRF 进行联合解码。 此外,他们的模型也不是真正的端到端,因为它利用外部知识,如字符类型、大写和词典特征,以及一些专门针对 NER 的数据预处理(例如用一个“0”替换所有数字序列 0-9 )。最近,Lample 等人。 (2016) 为 NER 提出了 BLSTM CRF 模型,该模型利用 BLSTM 对字符级和单词级信息进行建模,并使用与 Chiu 和 Nichols (2015) 相同的数据预处理。 相反,我们使用 CNN 对字符级信息进行建模,从而在不使用任何数据预处理的情况下实现更好的 NER 性能。
之前还提出了其他几种用于序列标记的神经网络。 拉博等人。 (2015) 提出了一种用于德语词性标注的 RNN-CNNs 模型。 该模型类似于 Chiu 和 Nichols (2015) 中的 LSTM-CNNs 模型,不同之处在于使用 vanila RNN 代替 LSTM。 另一种使用 CNN 对字符级信息进行建模的神经架构是“CharWNN”架构(Santos 和 Zadrozny,2014),其灵感来自前馈网络(Collobert 等,2011)。 CharWNN 在英语 POS 标签上获得了接近最先进的准确度(有关详细信息,请参阅第 4.3 节)。 类似的模型也已应用于西班牙语和葡萄牙语 NER(dos Santos 等人,2015 年)Ling 等人。 (2015) 和 Yang 等人。 (2016) 还使用 BSLTM 将字符嵌入组合到单词的表示中,这类似于 Lample 等人。 (2016)。 Peng 和 Dredze (2016) 通过分词改进了中文社交媒体的 NER。
6 总结
在本文中,我们提出了一种用于序列标记的神经网络架构。 它是一个真正的端到端模型,不依赖于特定于任务的资源、特征工程或数据预处理。 与之前最先进的系统相比,我们在两个语言序列标记任务上取得了最先进的性能。
未来的工作有几个潜在的方向。 首先,我们的模型可以通过探索多任务学习方法来进一步改进,以结合更多有用和相关的信息。例如,我们可以联合训练一个带有 POS 和 NER 标签的神经网络模型,以改进在我们的网络中学习的中间表示。 另一个有趣的方向是将我们的模型应用于来自社交媒体(Twitter 和微博)等其他领域的数据。 由于我们的模型不需要任何特定于领域或任务的知识,因此将其应用于这些领域可能会毫不费力。
致谢
这项研究部分得到了 DEFT 计划资助的 DARPA 赠款 FA8750-12-2-0342 的支持。 本材料中表达的任何意见、发现、结论或建议均为作者的观点,不一定反映 DARPA 的观点。















 1253
1253











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









