







个性化智能推荐(协同过滤算法)技术研究
一. 协同过滤推荐(Collaborative Filtering简称 CF)
协同过滤技术是目前推荐系统中最成功和应用最广泛的技术,在理论研究和实践中都取得了快速的发展,它根据用户的历史选择信息和相似性关系,收集与用户兴趣爱好相同的其他用户的评价信息来产生推荐。
协同过滤也称为社会过滤,它计算用户间偏好的相似性,在相似用户的基础上自动的为目标用户进行过滤和筛选,其基本思想为具有相同或相似的价值观、思想观、知识水平和兴趣偏好的用户,其对信息的需求也是相似的。因此相对于传统的推荐方法,协同过滤技术体现出的一个显著的优势是能够推荐一些难以进行内容分析的项目,比如信息质量、个人品味等抽象的资源对象。另外协同过滤技术能够有效的使用其他兴趣相似用户的评价信息,从而利用较少的用户反馈,加快了个性化学习的速度,同时利于发现用户的隐藏兴趣。从 1992 年该技术的思想首次被提出以来,协同过滤技术以其广阔的应用价值,受到了越来越多学者的关注,并成为一个重要的研究热点。
协同过滤技术是利用户间的兴趣偏好相似性来产生推荐,且推荐的过程是完全自动的,即推荐结果的产生是系统从用户的购买行为或浏览记录等隐式信息中得到的,无需用户通过填写调查表格等方式来明确自己的兴趣信息。
相对于其它的推荐技术,由于协同过滤不依赖于抽取”推荐对象“的特征信息来了解用户的兴趣,并能够发现用户的潜在兴趣,具备较高的个性化程度,因此协同过滤技术受到越来越多研究者的关注,并广泛应用于在电子商务推荐领域。
常用协同过滤算法:基于内存的协同过滤推荐,基于模型的协调过滤推荐。
1.基于内存的-协同过滤(Collaborative Filtering简称 CF)
1.1基于内存的协同过滤算法又分为两类
第一类:基于user的协同过滤(user-based CF):
通过不同用户对item的评分来评测用户之间的相似性,基于用户之间的相似性做出推荐;基于用户的(User-based)协同过滤算法是根据邻居用户的偏好信息产生对目标用户的推荐。它基于这样一个假设: 如果一些用户对某一类项目的打分比较接近,则他们对其它类项目的打分也比较接近(相似用户对某一item的打分相似,即先计算用户相似性找到最相似top-k个用户,再从中找到对指定item预测过的用户,根据相似用户的评分估算出该用户对此商品的可能评分,然后做出预测)。协同过滤推荐系统采用统计计算方式搜索目标用户的相似用户, 并根据相似用户对项目的打分来预测目标用户对指定项目的评分,最后得出可能的预测评分比较高的n个项目(产品),并推荐给用户。这种算法不仅计算简单且精确度较高,被现有的协同过滤推荐系统广泛采用。User-based协同过滤推荐算法的核心就是通过相似性度量方法计算出最近邻居集合,并将最近邻的评分结果作为参考,预测该用户对此item的可能评分。
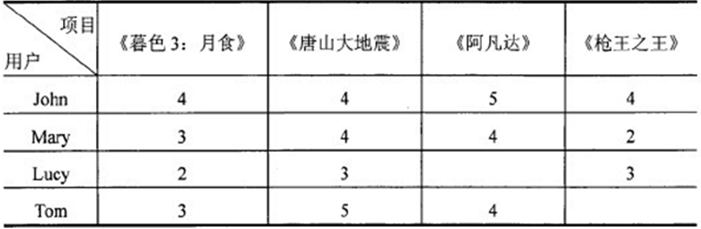
例如,在下表所示的用户一项目评分矩阵中,行代表用户,列代表项目(电影),表中的数值代表用户对某个项目的评价值。现在需要预测用户Tom对电影《枪王之王》的评分(用户Lucy对电影《阿凡达》的评分是缺失的数据)。
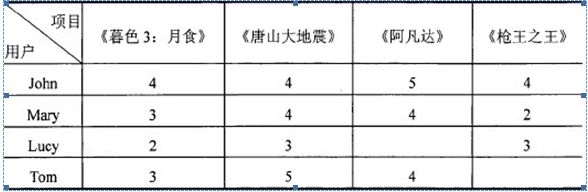
由上表不难发现,Mary和Tom对电影的评分非常接近,Mary对《暮色3:月食》、《唐山大地震》、《阿凡达》的评分分别为:3、4、4;Tom的评分分别为:3、5、4,他们之间的相似度最高,因此Mary是Tom的最接近的邻居,Mary对《枪王之王》的评分结果对预测值的影响占据最大比例。相比之下,用户John和Lucy不是Tom的最近邻居,因为他们对电影的评分存在很大差距,所以John和Lucy对《枪王之王》的评分对预测值的影响相对小一些。在真实的预测中,推荐系统只对前若干个邻居进行搜索,并根据这些邻居的评分为目标用户预测指定项目的评分。由上面的例子不难知道,User-based协同过滤推荐算法的主要工作内容是用户相似性度量、最近邻居查询和预测评分。
user-based CF推荐算法描述:
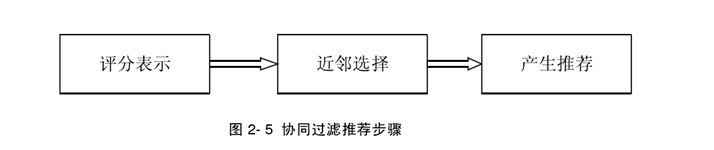
1) 评分标示:传统协同过滤推荐算法的输入数据是一个m × n的用户-项目评分矩阵
2) 近邻选择:
协同过滤算法的推荐原理就是查找与目标用户相似的近邻用户,通过近邻用户的评价对目标用户产生推荐。近邻用户的选择方法如下:计算目标用户与推荐系统中其他所有用户的相似性,根据相似性排序从大到小依次选择前面的K个最相似的用户作为目标用户的近邻集合。
这其中,相似性度量方法的选择对于推荐精度有着至关重要的影响,常用的相似性度量方法有皮尔逊相关(PearsonCorrelationSimilarity)、余弦相似性(Cosine Similarity)、修正的余弦相似性(Adjusted Cosine Similarity)等
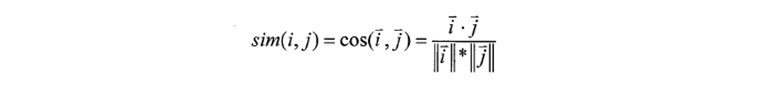
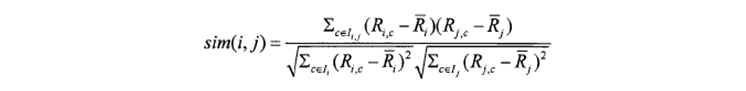
③相关相似性(Correlation)此方法是采用皮尔森(Pearson)相关系数来进行度量。设Iij表示用户i和用户j共同评分过的项目集合,则用户i和用户j之间相似性为:
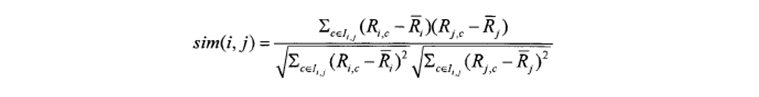
最后,在得到目标用户的最近邻居以后,接着就要产生相应的推荐结果。设NNu为用户u的最近邻居集合,则用户u对项j的预测评分Puj计算公式如下:
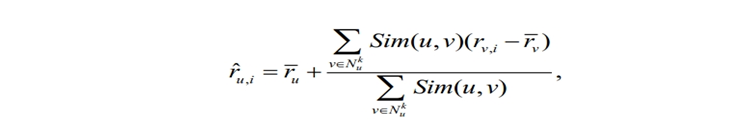
3)产生推荐
协同过滤算法一个基本的假设就是具有相似喜好的用户对于同一个项目会给出相似的评分。因此,目标用户的近邻集合生成后,就可以根据近邻集合中用户的评分,来预测目标用户对于未评分项目的评分。
根据预测得分,选择预测评分较高的几个项目(产品)推荐给客户。
第二类:基于item的协同过滤(item-based CF)
item-based CF举例说明:客户W已经购买了商品 A 并给与了评分,而之前还有很多客户购买了商品 A 并且也大都给与了评分,那么可以使用其他用户对A的一系列评分作为A的特征向量,得A=(score1,score2,...,score n),根据此原理,去寻找也其与其相似的item,找到最相似的K个,推荐给客户W。
原理讲解:通过用户对不同item的评分来评测item之间的相似性,基于item之间的相似性做出推荐;基于项目的(Item-based)协同过滤是根据用户对相似项目的评分数据预测目标项目的评分,它是建立在如下假设基础上的,Item-based算法认为:一个人会喜欢“和他以前喜欢的东西”相似的东西;比如我喜欢文艺片,昨天看过文艺片,或者刚刚看完一部文艺片,正不知道下一部要看啥,这时候豆瓣推荐引擎会给我推荐其它类的文艺片。Item-based协同过滤算法主要对目标用户所评价的一组项目进行研究,并计算这些项目与目标项目之间的相似性,然后从选择前K个最相似度最大的项目输出,这是区别于User-based协同过滤。
仍拿上所示的用户-项目评分矩阵作为例子,还是预测用户Tom对电影《枪王之王》的评分(用户Lucy对电影《阿凡达》的评分是缺失的数据)。
项目-用户评分矩阵,如下:
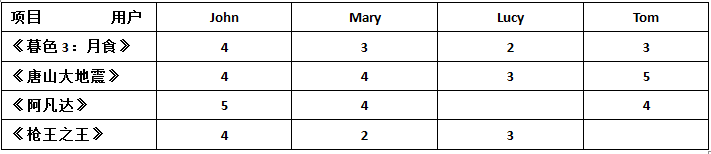
通过数据分析发现,电影《暮色3:月食》的评分与《枪王之王》评分非常相似,前三个用户对《暮色3:月食》的评分分别为4、3、2,前三个用户对《枪王之王》的评分分别为4、3、2,他们二者相似度最高,因此电影《暮色3:月食》是电影《枪王之王》的最佳邻居,因此《暮色3:月食》对《枪王之王》的评分对预测值的影响占据最大比例。而《唐山大地震》和《阿凡达》不是《枪王之王》的好邻居,因为用户群体对它们的评分存在很大差距,所以电影《唐山大地震》和 《阿凡达》对《枪王之王》的评分对预测值的影响相对小一些。比如Tom刚刚看完《暮色3:月食》这部电影,并且完成了对该电影的打分;此时采用Item-based算法的影视系统就可能会给Tom推荐《枪王之王》这部电影。在真实的预测中,推荐系统只对前若干个邻居进行搜索,并根据这些邻居的评分为目标用户预测指定项目的评分。
由上面的例子不难知道,Item-based协同过滤推荐算法的主要工作内容是最近邻居查询和产生推荐。因此,Item-based协同过滤推荐算法可以分为最近邻查询和产生推荐两个阶段。最近邻查询阶段是要计算项目与项目之间的相似性,搜索目标项目的最近邻居;产生推荐阶段是根据用户对目标项目的最近邻居的评分信息,来预测用户对目标项目的评分,最后产生前N个推荐信息。
ltem-based协同过滤算法的关键步骤仍然是计算项目之间的相似性并选出最相似的项目,这一点与user-based协同过滤类似。计算两个项目i 和j之间相似性的基本思想是首先将对两个项目共同评分的用户提取出来,并将每个项目获得的评分看作是n维用户空间的向量,再通过相似性度量公式计算两者之间的相似性。
分离出相似的项目之后,下一步就要为目标项目预测评分,通过计算用户u对与项目i相似的项目集合的总评价分值来计算用户u对项目i的预期。这两个阶段的具体公式和操作步骤与基于用户的协同过滤推荐算法类似,所以在此不再赘述。
1.2. 与传统文本过滤相比,协同过滤有下列优点:
1. 能够过滤难以通过机器自动基于内容分析的信息。如艺术品、音乐;
2. 能够基于一些复杂的,难以表达的概念(信息质量、品位)进行过滤;
3. 推荐的新颖性。 正因为如此,协同过滤在商业应用上也取得了不错的成绩。Amazon,CDNow,MovieFinder,都采用了协同过滤的技术来提高服务质量。
因此,协同过滤的基本出发点可以总结为:(1)用户是可以按兴趣分类;(2)用户对不同的信息评价包含了用户的兴趣信息;(3)用户对一个未知信息的评价将和其相似(兴趣)用户的评价相似。这三条构成了协同过滤系统的基础。
1.3 协同过滤算法的不足之处:
协同过滤技术在推荐系统中取得了广泛的应用和巨大的成功,但是随着互联网的发展和普及,用户人数和商品、网络资源的爆增,站点结构复杂度的增加,以及网络信息安全的不断升级,协同过滤推荐系统也面临着如下诸多问题和挑战:
1) 数据稀疏
2) 冷启动问题:冷启动问题包含新用户问题(new user problem)和新项目问题(new itemproblem)两种情况。新用户问题是指当一个新用户加入到推荐系统时,由于没有该用户的历史评分数据,因此无法根据评分信息对新用户进行推荐服务。新项目问题是指当一个全新的商品加入到推荐系统中后,由于没有用户对其进行过评价,则在系统运行的初期,它将很难获得推荐。新项目问题可以通过结合基于内容的推荐(项目的属性信息)等方法,来缓解冷启动问题。
3) 可扩展性问题
4) 鲁棒性问题:推荐系统能否识别此种情况,去除恶意用户及异常数据,提高推荐系统的可靠性,这也是目前推荐系统鲁棒性方面所需要重点关注的问题。
5) 隐性喜好发现
1.4 无聊写点笔记2-User-CF和Item-CF的联系和区别
以前一直觉得user-based和item-based差别不大,算法的差异小的我每次和别人说起都解释一下。后来慢慢的才发现丢脸了,其实从物理意义上两者差别大着呢,想想自己以前一直喜欢从物理角度给别人解说算法我就脸红。
User-CF和Item-CF是协同过滤中最为古老的两种算法,早在20多年前就有学着提出来,由于简单,很多网站都应用。以我现在的阅读论文经验来说,youtobe等各大网站应用的算法,概括点说就是在数据清洗阶段不同,数据组织成矩阵存储之后,差不多都是有user-based和item-based的影子。我忘了和谁聊天了,似乎是面试官还是朋友说,数据挖掘,推荐引擎什么的其实也就那样,只不过外行的看起来很高深而已,做了才知道,弄来弄去不过如此。EMC一个博士在面试我的时候也提及了类似的观点,我现在的观点也觉得,如果计算相似度的逻辑搞清楚了,其余剩下的没什么难度。
User- based算法认为一个人会喜欢和他有相同爱好的人喜欢的东西,即人以群分,我在豆瓣上关注的人都是我喜欢的人,他们喜欢的东西我也喜欢。而Item-based算法认为一个人会喜欢“和他以前喜欢的东西”相似的东西;比如我喜欢文艺片,昨天看过文艺片,或者刚刚看完一部文艺片,正不知道下一部要看啥,这时候豆瓣推荐引擎会给我推荐其它类的文艺片。这两个假设都有其合理性。
在网上看网友的博客指出,根据网友的测试,用User-CF和Item-CF做出的推荐列表中,只有50%是一样的,还有50%完全不同。但是这两个算法确有相似的精度,所以说,这两个算法是很互补的。这句话在很多书中也见过,但是没有做过测试检验。以下是网友的见解,粘贴过来:
我一直认为这两个算法是推荐系统的根本,因为无论我们是用矩阵,还是用概率模型,我们都非常的依赖于前面说的两种假设。如果用户的行为不符合那两种假设,推荐系统就没必要存在了。因此我一直希望能够找出这两种算法的本质区别。他们有相似的精度,但是coverage(覆盖)相差很大,Item-CF coverage很大而User-CF很小。我还测试了很多其他指标,不过要从这些表象的指标差异找出这两个算法的本质区别还是非常困难。不过上周我基本发现了这两个算法推荐机理的本质区别。
我们做如下假设。每个用户兴趣爱好都是广泛的,他们可能喜欢好几个领域的东西。不过每个用户肯定也有一个主要的领域,对这个领域会比其他领域更加关心。给定一个用户,假设他喜欢3个领域A,B,C,同时A是他喜欢的主要领域。这个时候我们来看User-CF和Item-CF倾向于做出什么推荐。
结果如下,如果用User-CF, 它会将A,B,C三个领域中比较热门的东西推荐给用户【这个可以理解,算法会寻找同是喜欢这3个领域的用户,然后将这3个领域中最相似的物品进行推荐】。而如果用Item-CF,它会基本上只推荐A领域的东西给用户【A领域在用户偏好中占大部分,对应item-item相似度占比率大,被推荐概率大】。因为User-CF只推荐热门的,所以User-CF在推荐长尾上能力不足。而Item-CF只推荐A领域给用户,这样他有限的推荐列表中就可能包含了一定数量的不热门item,所以Item-CF推荐长尾的能力比较强。不过Item-CF的推荐对某一个用户而言,显然多样性不足。但是对整个系统而言,因为不同的用户的主要兴趣点不同,所以系统的coverage会很大。【终于明白了覆盖率大的含义】
显然上面的两种推荐都有其合理性,但都不是最好的选择,因此他们的精度也会有损失。最好的选择是,如果我们给这个用户推荐30个item,我们既不是每个领域挑选10个最热门的给他,也不是推荐30个A领域的给他,而是比如推荐15个A领域的给他,剩下的15个从B,C中选择。【这个在实际应用中就不是很容易做到了,如何将用户兴趣分类?使用图论,连接矩阵将用户兴趣偏好识别?与其这样,还不如先将数据进行社区聚类,将数据根据图划分为几个小团体,针对小团体做推荐,这样就比如将只有上面提及的3中兴趣爱好的人组成的社区里面进行推荐。至于算法,小团体里大家都差不多,对应偏好矩阵稠密度较高,两个算法差距应该不大吧,具体有待考究】
认识到这一点,可以给我们设计高精度的算法指明一个方向。就是当一个系统对个人推荐的多样性不足时,我们增加个人推荐的多样性可以提高精度。而当一个系统的整体多样性不足(比如只推荐popular的),我们增加整体的多样性同样可以提高精度。
参考:http://www.douban.com/note/205755213/
对于系统中item更新速度非常快时,基于user的推荐算法能更好的起到推荐的作用。google reader推荐策略:定期的算一下用户之间的相似度,豆瓣是6个小时吧?然后对一个给定用户,找出和他最相似的100个用户,这里其实和mahout中分布式的推荐过程不一样了,但是对于其非分布式估计是一样,按照参数的含义,亟待分析其非分布式代码!然后找出这100个用户最近3天share和like的文章,并对这些文章进行排序,选择前50个,作为最后的结果。
user-based算法非常适合于item快速更新的场合,在google reader上,每秒钟都会出现很多新的文章,所以实时计算文章直接的相似度是很困难的。
2. 基于模型的协同过滤(仅今年的技术趋势)
基于矩阵分解算法属于基于模型的推荐。矩阵分解算法目前在推荐系统中应用非常广泛,对于使用RMSE作为评价指标的系统尤为明显,因为矩阵分解的目标就是使RMSE取值最小。但矩阵分解有其弱点,就是解释性差,不能很好为推荐结果做出解释。
参考:http://blog.csdn.net/sun_168/article/details/20637833
3. 混合推荐技术(Hybrid Recommendation)
鉴于各种推荐方法都有优缺点和技术特点,且具有将强的互补性,因此在实际推荐系统中,通常采用组合推荐(Hybrid Recommendation)的方式来对用户做出推荐。目前的组合推荐方法中,较为流行的是将协同过滤和基于内容推荐相结合,最简单的做法就是用协同过滤推荐方法和基于内容的方法分别得到一个推荐结果,最终结果由这两者然后按照一定的原则组合产生。















 7480
7480











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









