







缓存穿透
问题描述
key 对应的数据在数据源并不存在,每次针对此 key 的请求从缓存获取不到,请求都会压到数据源,从而可能压垮数据源。比如用一个不存在的用户id(userId= -1)获取用户信息,不论缓存还是数据库都没有,若黑客利用此漏洞进行攻击可能压垮数据库。
解决方案
一个不存在缓存及查询不到的数据,由于缓存是不命中时被动写的,并且出于容错考虑,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到存储层去查询,失去了缓存的意义。
解决方案
(1)对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),我们仍然把这个空结果(null)进行缓存,设置空结果的过期时间会很短,最长不超过1分钟。
(2)设置可访问的名单(白名单)
使用bitmaps类型定义一个可以访问的名单,名单id作为bitmaps的偏移量,每次访问和bitmap里面的id进行比较,如果访问id不在bitmaps里面,进行拦截,不允许访问。
(3)采用布隆过滤器:(布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。
布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。)
将所有可能存在的数据哈希到一个足够大的bitmaps中,一个一定不存在的数据会被 这个bitmaps拦截掉,从而避免了对底层存储系统的查询压力。
(4)进行实时监控:当发现Redis的命中率开始急速降低,需要排查访问对象和访问的数据,和运维人员配合,可以设置黑名单限制服务
缓存击穿
问题描述
key对应的数据在数据库存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。

解决方案
key 可能会在某些时间点被超高并发地访问,是一种非常“热点”的数据。这个时候,需要考虑一个问题:缓存被“击穿”的问题。
解决问题
(1)预先设置热门数据:在redis高峰访问之前,把一些热门数据提前存入到redis里面,加大这些热门数据key的时长
(2)实时调整:现场监控哪些数据热门,实时调整key的过期时长
(3)使用锁:
(1)就是在缓存失效的时候(判断拿出来的值为空),不是立即去load db。
(2)先使用缓存工具的某些带成功操作返回值的操作(比如Redis的SETNX)去set一个mutex key
(3)当操作返回成功时,再进行load db的操作,并回设缓存,最后删除mutex key;
(4)当操作返回失败,证明有线程在load db,当前线程睡眠一段时间再重试整个get缓存的方法。
流程图
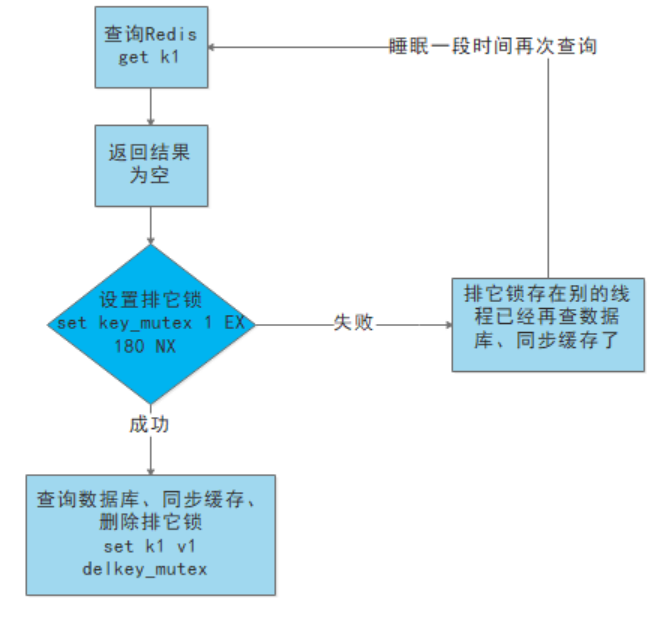
分布式锁实现
/**
* 获取文章详情 -- 防止缓存击穿
*
* @date: 2020/12/2 14:10
* @return: Content
*/
@GetMapping("getContentDetail02")
public Content getContentDetail02(@RequestParam(value = "contentId") Long contentId) {
log.info("getContentDetail02.req contentId={}", contentId);
Content content;
String detail = CONTENT + ":" + DETAIL + ":" + contentId;
String conLock = CONTENT + ":" + LOCK + ":" + contentId;
String lock = "";
String value = redisService.get(detail);
if (StringUtils.isNotEmpty(value)) {
log.info("从缓存获取数据.....");
return JSON.parseObject(value, Content.class);
}
try {
lock = redisService.getLock(conLock, 10);
if (StringUtils.isNotEmpty(lock)) {
// 获取数据库数据
content = getData(contentId);
// 查询文章内容不为空设置缓存为10min
if (Objects.nonNull(content)) {
redisService.setKeyByMINUTES(detail, JSON.toJSONString(content), 10);
}
// 查询文章内容为空设置缓存为1min,避免缓存穿透
redisService.setKeyByMINUTES(detail, JSON.toJSONString(content), 1);
return content;
}
// 休眠重新尝试调用方法
Thread.sleep(300);
getContentDetail(contentId);
} catch (Exception e) {
e.printStackTrace();
} finally {
redisService.unLock(detail, lock);
}
return null;
}缓存雪崩
问题描述
key对应的数据存在,但在redis中过期,此时若有大量并发请求过来,这些请求发现缓存过期一般都会从后端DB加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把后端DB压垮。
缓存雪崩与缓存击穿的区别在于这里针对很多key缓存,前者则是某一个key正常访问

缓存失效瞬间
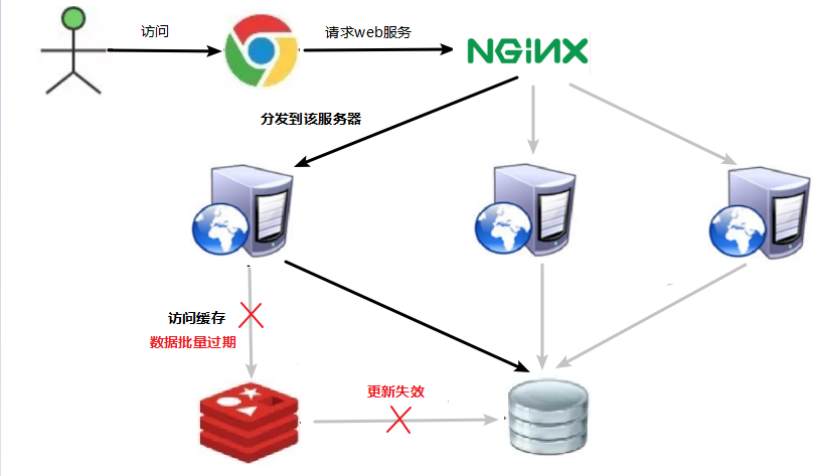
解决方案
缓存失效时的雪崩效应对底层系统的冲击非常可怕!
解决方案:
(1)构建多级缓存架构:nginx缓存 + redis缓存 +其他缓存(ehcache等)
(2)使用锁或队列:
用加锁或者队列的方式保证来保证不会有大量的线程对数据库一次性进行读写,从而避免失效时大量的并发请求落到底层存储系统上。不适用高并发情况
(3)设置过期标志更新缓存:
记录缓存数据是否过期(设置提前量),如果过期会触发通知另外的线程在后台去更新实际key的缓存。
(4)将缓存失效时间分散开:
比如我们可以在原有的失效时间基础上增加一个随机值,比如1-5分钟随机,这样每一个缓存的过期时间的重复率就会降低,就很难引发集体失效的事件。
缓存预热
缓存预热如字面意思,当系统上线时,缓存内还没有数据,如果直接提供给用户使用,每个请求都会穿过缓存去访问底层数据库,如果并发大的话,很有可能在上线当天就会宕机,因此我们需要在上线前先将数据库内的热点数据缓存至Redis内再提供出去使用,这种操作就成为"缓存预热"。
缓存预热的实现方式有很多,比较通用的方式是写个批任务,在启动项目时或定时去触发将底层数据库内的热点数据加载到缓存内。
缓存更新
缓存服务(Redis)和数据服务(底层数据库)是相互独立且异构的系统,在更新缓存或更新数据的时候无法做到原子性的同时更新两边的数据,因此在并发读写或第二步操作异常时会遇到各种数据不一致的问题。如何解决并发场景下更新操作的双写一致是缓存系统的一个重要知识点。
第二步操作异常:缓存和数据的操作顺序中,第二个动作报错。如数据库被更新, 此时失效缓存的时候出错,缓存内数据仍是旧版本;
缓存更新的设计模式有四种:
- Cache aside:查询:先查缓存,缓存没有就查数据库,然后加载至缓存内;更新:先更新数据库,然后更新缓存;
- Read through:在查询操作中更新缓存,即当缓存失效时,Cache Aside 模式是由调用方负责把数据加载入缓存,而 Read Through 则用缓存服务自己来加载;
- Write through:在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库;
- Write behind caching:俗称write back,在更新数据的时候,只更新缓存,不更新数据库,缓存会异步地定时批量更新数据库
- Cache aside:
为了避免在并发场景下,多个请求同时更新同一个缓存导致脏数据,因此不能直接更新缓存而是另缓存失效。
- 先更新数据库后失效缓存:并发场景下,推荐使用延迟失效(写请求完成后给缓存设置1s过期时间),在读请求缓存数据时若redis内已有该数据(其他写请求还未结束)则不更新。当redis内没有该数据的时候(其他写请求已另该缓存失效),读请求才会更新redis内的数据。这里的读请求缓存数据可以加上失效时间,以防第二步操作异常导致的不一致情况。
- 先失效缓存后更新数据库:并发场景下,推荐使用延迟失效(写请求开始前给缓存设置1s过期时间),在写请求失效缓存时设置一个1s延迟时间,然后再去更新数据库的数据,此时其他读请求仍然可以读到缓存内的数据,当数据库端更新完成后,缓存内的数据已失效,之后的读请求会将数据库端最新的数据加载至缓存内保证缓存和数据库端数据一致性;在这种方案下,第二步操作异常不会引起数据不一致,例如设置了缓存1s后失效,然后在更新数据库时报错,即使缓存失效,之后的读请求仍然会把更新前的数据重新加载到缓存内。
四种缓存更新模式的优缺点:
- Cache Aside:实现起来较简单,但需要维护两个数据存储,一个是缓存(Cache),一个是数据库(Repository);
- Read/Write Through:只需要维护一个数据存储(缓存),但是实现起来要复杂一些;
- Write Behind Caching:与Read/Write Through 类似,区别是Write Behind Caching的数据持久化操作是异步的,但是Read/Write Through 更新模式的数据持久化操作是同步的。优点是直接操作内存速度快,多次操作可以合并持久化到数据库。缺点是数据可能会丢失,例如系统断电等。
- 缓存本身就是通过牺牲强一致性来提高性能,因此使用缓存提升性能,就会有数据更新的延迟性。这就需要我们在评估需求和设计阶段根据实际场景去做权衡了。
缓存降级
缓存降级是指当访问量剧增、服务出现问题(如响应时间慢或不响应)或非核心服务影响到核心流程的性能时,即使是有损部分其他服务,仍然需要保证主服务可用。可以将其他次要服务的数据进行缓存降级,从而提升主服务的稳定性。
降级的目的是保证核心服务可用,即使是有损的。如去年双十一的时候淘宝购物车无法修改地址只能使用默认地址,这个服务就是被降级了,这里阿里保证了订单可以正常提交和付款,但修改地址的服务可以在服务器压力降低,并发量相对减少的时候再恢复。
降级可以根据实时的监控数据进行自动降级也可以配置开关人工降级。是否需要降级,哪些服务需要降级,在什么情况下再降级,取决于大家对于系统功能的取舍。














 1285
1285











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









