以下是 深度学习、机器学习和人工智能 的详细对比,从定义、原理、技术基础、应用场景、优缺点等多个维度展开分析:
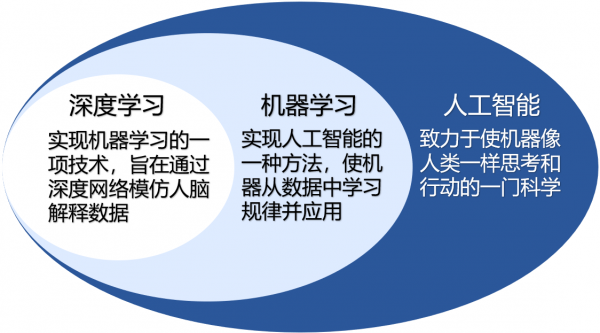
1. 定义与范围
| 概念 | 定义 | 范围 |
|---|
| 人工智能(AI) | 使机器模拟人类智能(如推理、学习、感知、决策)的广义技术领域。 | 包括所有模拟人类智能的技术,如规则系统、专家系统、机器学习、深度学习等。 |
| 机器学习(ML) | AI的子领域,通过算法从数据中自动学习规律,无需显式编程。 | 属于AI的一部分,专注于数据驱动的模型训练与预测。 |
| 深度学习(DL) | ML的子领域,基于多层神经网络(深度神经网络)模拟人脑学习过程。 | 属于ML的一部分,依赖大量数据和计算资源,擅长处理非结构化数据(如图像、文本)。 |
2. 核心原理对比
| 维度 | 人工智能(AI) | 机器学习(ML) | 深度学习(DL) |
|---|
| 核心思想 | 模拟人类智能行为(如推理、决策、感知) | 通过数据学习规律,实现预测或决策 | 通过多层神经网络模拟人脑,自动提取特征 |
| 是否需要人工干预 | 需要(如规则设计、算法选择) | 需要(如特征工程、模型调参) | 较少(自动特征提取,但需大量数据) |
| 数据依赖 | 可以是规则、数据或混合 | 高(依赖结构化或半结构化数据) | 极高(依赖大规模非结构化数据) |
3. 技术基础对比
| 技术基础 | 人工智能(AI) | 机器学习(ML) | 深度学习(DL) |
|---|
| 算法类型 | 包括规则引擎、逻辑推理、搜索算法等 | 包括线性回归、决策树、SVM、随机森林等 | 包括CNN(卷积神经网络)、RNN(循环神经网络)、Transformer等 |
| 特征工程 | 可能需要人工设计规则或特征 | 需要人工设计特征(传统ML) | 自动提取特征(如图像中的边缘、纹理) |
| 计算资源需求 | 低至中等(如规则系统) | 中等(依赖数据规模) | 高(需GPU/TPU加速训练) |
| 模型复杂度 | 简单到复杂(如专家系统到复杂算法) | 中等(模型结构相对简单) | 极高(多层网络,参数量可达亿级) |
4. 典型应用场景
| 应用场景 | 人工智能(AI) | 机器学习(ML) | 深度学习(DL) |
|---|
| 经典案例 | 专家系统(如医疗诊断)、传统机器人 | 推荐系统(如Netflix)、分类(如垃圾邮件检测) | 图像识别(如人脸识别)、自然语言处理(如ChatGPT) |
| 数据类型 | 结构化、非结构化均可(如规则系统) | 以结构化数据为主(如表格数据) | 非结构化数据为主(如图像、文本、音频) |
| 实时性要求 | 可能低(如规则系统) | 中等(如在线预测) | 高(如实时图像识别、语音助手) |
5. 优缺点对比
(1) 人工智能(AI)
- 优点:
- 灵活性高,可结合多种技术(如规则+ML+DL)。
- 适用于复杂逻辑(如专家系统)。
- 缺点:
- 传统AI(非数据驱动)依赖人工规则设计。
- 难以处理大规模非结构化数据。
(2) 机器学习(ML)
- 优点:
- 数据驱动,减少人工规则依赖。
- 可解释性较强(如决策树、逻辑回归)。
- 适用于结构化数据(如金融风控、销售预测)。
- 缺点:
- 需人工设计特征(传统ML)。
- 对小数据集效果有限。
- 模型复杂度较低,难以处理高维数据。
(3) 深度学习(DL)
- 优点:
- 自动特征提取,适合图像、文本等非结构化数据。
- 在大规模数据下表现优异(如AlphaGo、图像生成)。
- 缺点:
- 需要大量标注数据和计算资源。
- 模型“黑箱”特性强,可解释性差。
- 训练时间长,部署成本高。
6. 技术演进关系
人工智能(AI)
├── 机器学习(ML)
│ ├── 传统机器学习(如SVM、决策树)
│ └── 深度学习(DL)
│ ├── CNN(图像识别)
│ ├── RNN(序列数据)
│ └── Transformer(NLP)
└── 非机器学习方法
├── 规则引擎
├── 专家系统
└── 搜索算法(如A*算法)
7. 典型工具与框架对比
| 工具/框架 | 适用领域 | 典型用途 |
|---|
| 人工智能(AI) | 规则系统、传统算法 | IBM Watson、Prolog、Drools |
| 机器学习(ML) | 结构化数据建模 | Scikit-learn、XGBoost、Spark MLlib |
| 深度学习(DL) | 非结构化数据处理 | TensorFlow、PyTorch、Hugging Face |
8. 典型问题解决对比
(1) 图像识别
- AI:传统方法(如SIFT特征匹配)。
- ML:SVM+人工设计的特征(如颜色直方图)。
- DL:CNN自动提取特征(如ResNet、YOLO)。
(2) 文本翻译
- AI:基于规则的翻译系统。
- ML:基于统计的机器翻译(如SMT)。
- DL:Transformer模型(如BERT、GPT)。
(3) 游戏AI
- AI:规则引擎(如棋类游戏策略)。
- ML:强化学习(如AlphaGo的早期版本)。
- DL:深度强化学习(如AlphaGo Zero)。
9. 数据需求对比
| 数据类型 | 人工智能(AI) | 机器学习(ML) | 深度学习(DL) |
|---|
| 结构化数据 | 可处理(如表格数据) | 主要应用场景 | 较少直接使用,需转换为向量形式 |
| 非结构化数据 | 依赖人工规则(如文本处理) | 需人工特征工程(如TF-IDF) | 直接处理(如原始像素、单词序列) |
| 数据规模 | 小规模或中等规模 | 中等规模(千至百万级样本) | 大规模(百万至十亿级样本) |
10. 总结对比表格
| 维度 | 人工智能(AI) | 机器学习(ML) | 深度学习(DL) |
|---|
| 技术定位 | 包含所有智能技术的总称 | 数据驱动的预测与决策技术 | 基于深度神经网络的复杂模式识别 |
| 核心目标 | 模拟人类智能行为 | 从数据中学习规律 | 模拟人脑神经网络,自动学习特征 |
| 典型模型 | 专家系统、规则引擎 | 决策树、SVM、随机森林 | CNN、RNN、Transformer、GAN |
| 计算资源 | 低至中等 | 中等 | 高(需GPU/TPU) |
| 应用场景 | 专家系统、传统机器人 | 推荐系统、分类、回归 | 图像识别、NLP、语音合成、生成模型 |
| 数据依赖 | 可少(规则系统)或需大量数据 | 中等(需特征工程) | 极高(需海量标注数据) |
| 可解释性 | 高(规则系统)或低(复杂模型) | 中等(如决策树可解释) | 低(黑箱模型) |
11. 技术选型建议
| 需求场景 | 推荐技术 | 理由 |
|---|
| 小规模规则驱动 | AI(规则引擎) | 开发成本低,逻辑清晰。 |
| 结构化数据预测 | ML(如XGBoost、逻辑回归) | 模型可解释性强,适合金融、医疗等。 |
| 图像/语音处理 | DL(CNN、WaveNet) | 自动特征提取,处理复杂非结构化数据。 |
| 实时性要求高 | DL(轻量化模型,如MobileNet) | 边缘计算部署,低延迟推理。 |
| 可解释性要求高 | ML(决策树、LSTM) | 医疗诊断、金融风控需透明决策。 |
12. 典型工具与案例
(1) 机器学习(ML)案例
- 场景:电商推荐系统。
- 工具:Scikit-learn、XGBoost。
- 方法:基于用户行为的协同过滤(矩阵分解)。
(2) 深度学习(DL)案例
- 场景:医学影像诊断。
- 工具:PyTorch、TensorFlow。
- 方法:CNN自动检测肿瘤(如ResNet-50)。
(3) 传统AI案例
- 场景:早期游戏AI(如国际象棋)。
- 工具:规则引擎、搜索算法。
- 方法:基于规则的棋局评估(如AlphaBeta剪枝)。
13. 关键差异总结
| 对比项 | 机器学习 vs 深度学习 | 人工智能 vs 其他技术 |
|---|
| 特征工程 | ML需要人工设计,DL自动提取 | AI包含DL和ML,也包括规则系统 |
| 模型复杂度 | ML模型简单,DL模型复杂(多层网络) | AI涵盖所有智能技术,DL是其中最前沿的分支 |
| 适用数据类型 | ML适合结构化数据,DL适合非结构化数据 | AI可处理任何数据类型(需匹配技术) |
| 实时性 | ML推理快,DL需优化(如轻量化模型) | DL在边缘部署时需权衡性能与精度 |
14. 发展趋势
- AI:向**通用人工智能(AGI)**探索,结合多种技术(如符号AI+DL)。
- ML:与DL结合(如混合模型),提升可解释性(如SHAP、LIME)。
- DL:向小样本学习(Few-shot Learning)、自监督学习发展,减少对标注数据的依赖。
15. 典型技术栈对比
| 技术栈 | 适用场景 | 工具/框架 |
|---|
| 传统AI | 规则驱动、小数据场景 | Prolog、Drools、规则引擎 |
| 机器学习 | 结构化数据、可解释性要求高 | Scikit-learn、XGBoost、Spark ML |
| 深度学习 | 非结构化数据、复杂模式识别 | TensorFlow、PyTorch、Hugging Face |
16. 使用场景选择流程
- 问题类型:
- 需要规则逻辑(如流程自动化) → 传统AI。
- 需要结构化数据预测(如销售预测) → 机器学习。
- 需要图像/语音处理 → 深度学习。
- 数据规模:
- 小数据 → 传统ML或规则系统。
- 大数据 → 深度学习。
- 实时性要求:
- 低延迟 → 边缘部署轻量化DL模型(如TensorFlow Lite)。
- 离线处理 → 普通DL模型(如ResNet)。
17. 常见误解澄清
- “AI = DL”:错误。AI包含DL,但DL是AI的子集。
- “所有ML都是DL”:错误。DL是ML的子集,传统ML(如SVM、决策树)仍广泛使用。
- “DL不需要特征工程”:正确。DL自动提取特征,而传统ML需人工设计特征。
18. 典型工具与框架生态
| 技术 | 核心框架 | 优势 |
|---|
| 人工智能(AI) | Drools(规则引擎)、Prolog | 灵活性高,适合小规模逻辑场景。 |
| 机器学习(ML) | Scikit-learn、XGBoost、LightGBM | 模型轻量,可解释性强。 |
| 深度学习(DL) | TensorFlow、PyTorch、Hugging Face | 处理复杂模式,性能优越。 |
19. 典型行业应用对比
| 行业 | AI技术应用 | ML应用 | DL应用 |
|---|
| 医疗 | 专家系统辅助诊断 | 患者分群(K-means) | 医学影像分析(CNN) |
| 金融 | 风险规则引擎 | 信用评分(逻辑回归) | 反欺诈(GAN生成对抗样本检测) |
| 自动驾驶 | 路径规划(搜索算法) | 传感器数据分类(SVM) | 实时目标检测(YOLO)、决策(RL) |
20. 技术选型总结
| 需求 | 选择建议 | 案例 |
|---|
| 小数据、规则明确 | 传统AI(规则引擎) | 工业质检(规则+CV) |
| 结构化数据预测 | 机器学习(XGBoost) | 电商销量预测 |
| 图像/视频处理 | 深度学习(CNN、Transformer) | 医疗影像分析、视频监控 |
| 实时性要求高 | 边缘部署DL模型(TensorFlow Lite) | 智能摄像头、无人机避障 |
| 可解释性关键 | 机器学习(决策树、LIME) | 金融风控、医疗诊断 |
21. 技术局限性
| 技术 | 局限性 | 解决方案 |
|---|
| 传统AI | 依赖人工规则,扩展性差 | 结合ML/DL增强自动化能力 |
| 机器学习 | 特征工程耗时,对非结构化数据效果差 | 使用DL自动特征提取 |
| 深度学习 | 数据需求大,可解释性差 | 结合可解释性工具(如SHAP)、小样本学习 |
22. 典型技术栈组合
| 场景 | 技术组合 | 工具/框架 |
|---|
| 智能客服 | NLP(DL) + 对话管理(ML) | BERT(NLP) + Rasa(对话系统) |
| 自动驾驶 | 计算机视觉(DL) + 决策(RL) | YOLO(目标检测) + Stable Baselines(强化学习) |
| 推荐系统 | 协同过滤(ML) + 图神经网络(DL) | LightFM(ML) + GraphSAGE(DL) |
23. 关键术语与工具关系图
人工智能(AI)
├── 机器学习(ML)
│ ├── 监督学习(如SVM、决策树)
│ └── 无监督学习(如K-means、GAN)
└── 深度学习(DL)
├── CNN(图像)
├── RNN/LSTM(序列数据)
└── Transformer(NLP)
24. 典型错误案例分析
- 错误选型1:用传统ML处理图像分类 → 效果差(需人工设计特征)。
- 错误选型2:用DL处理小规模表格数据 → 过拟合风险高,应选择XGBoost。
- 错误选型3:实时性场景部署大型DL模型 → 应使用轻量化模型(如MobileNet)。
25. 行业趋势与未来方向
- AI:向多模态融合发展(如CLIP图文关联)。
- ML:与DL结合(如混合模型)提升性能。
- DL:向自监督学习(如BERT)、小样本学习(如Meta-Learning)发展。
通过以上对比,开发者可根据具体需求选择合适的技术:
- 简单逻辑场景 → 传统AI。
- 结构化数据预测 → 机器学习。
- 复杂非结构化数据 → 深度学习。
- 边缘部署 → 轻量化模型(如TensorFlow Lite)。
- 可解释性关键 → 机器学习或可解释性DL工具(如LIME)。



























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











