







以下是AI学习中的主要分类及其详细说明:
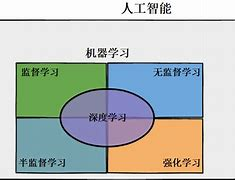
1. 监督学习分类算法
通过带标签的数据进行训练,预测离散类别。
1.1 逻辑回归(Logistic Regression)
- 原理:使用Sigmoid函数将线性组合映射到概率,阈值判断分类。
- 特点:简单高效,适合二分类,可扩展为多分类。
- 适用场景:垃圾邮件检测、信用评分。
1.2 决策树(Decision Tree)
- 原理:通过特征分裂数据,形成树形结构,叶子节点为类别。
- 特点:可解释性强,但易过拟合。
- 适用场景:规则明确的业务场景(如客户分群)。
1.3 随机森林(Random Forest)
- 原理:集成多棵决策树,通过投票或平均结果。
- 特点:抗过拟合,处理高维数据,但可解释性弱。
- 适用场景:高维数据分类(如图像、文本)。
1.4 支持向量机(SVM)
- 原理:寻找最优超平面最大化类别间隔,可结合核函数处理非线性数据。
- 特点:适合高维数据,但计算复杂度高。
- 适用场景:文本分类、图像识别。
1.5 K近邻(K-Nearest Neighbors, KNN)
- 原理:根据样本最近邻的类别投票决定分类。
- 特点:无需训练,计算量大,对噪声敏感。
- 适用场景:小规模数据或实时分类。
1.6 朴素贝叶斯(Naive Bayes)
- 原理:基于贝叶斯定理,假设特征条件独立。
- 特点:计算高效,适合高维稀疏数据。
- 适用场景:文本分类(如情感分析)。
1.7 神经网络(Neural Networks)
- 原理:多层感知机,通过反向传播调整权重。
- 特点:强大的非线性建模能力,需大量数据。
- 适用场景:图像分类(CNN)、自然语言处理(RNN/Transformer)。
1.8 集成方法(Ensemble Methods)
- Bagging:如随机森林,通过并行训练降低方差。
- Boosting:如AdaBoost、XGBoost,串行训练纠正错误。
- Stacking:结合多个模型预测结果。
2. 无监督学习分类
无需标签数据,发现数据内在结构。
2.1 聚类(Clustering)
- K-means:基于距离划分簇。
- 层次聚类:形成树状结构。
- DBSCAN:基于密度划分区域。
- 适用场景:客户分群、异常检测。
2.2 关联规则学习(Association Rule Learning)
- 原理:挖掘数据项间的关联关系(如Apriori算法)。
- 适用场景:市场篮分析(如“啤酒与尿布”关联)。
3. 半监督学习
结合少量标注数据和大量未标注数据。
3.1 传递学习(Transfer Learning)
- 原理:利用已标注领域的模型初始化,微调适应新领域。
- 适用场景:小数据集上的图像/文本分类。
3.2 协同训练(Co-Training)
- 原理:使用多个视图(特征子集)互相标注数据。
- 适用场景:多模态数据(如文本+图像)。
4. 深度学习分类
基于深度神经网络的复杂模型。
4.1 卷积神经网络(CNN)
- 特点:局部感知与权值共享,擅长图像分类。
- 典型模型:ResNet、VGG、EfficientNet。
4.2 循环神经网络(RNN)
- 特点:处理序列数据,如文本、时间序列。
- 变种:LSTM、GRU(解决梯度消失问题)。
4.3 变换器(Transformer)
- 原理:自注意力机制,处理长距离依赖。
- 典型应用:BERT、GPT系列模型。
5. 其他分类方法
5.1 贝叶斯网络(Bayesian Networks)
- 原理:基于概率图模型,表示变量间依赖关系。
- 适用场景:医疗诊断、故障诊断。
5.2 主成分分析(PCA)
- 原理:降维后进行分类(如结合SVM)。
- 适用场景:高维数据可视化或加速计算。
总结
- 选择依据:数据规模、特征类型、可解释性需求、计算资源。
- 典型场景:
- 文本分类:朴素贝叶斯、Transformer。
- 图像分类:CNN、ResNet。
- 业务规则明确:决策树、规则引擎。
- 复杂非线性问题:深度学习、集成方法。
可根据具体任务需求选择或组合上述方法。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











