







 虚拟文件系统(VFS)是Linux内核的关键组件,允许不同文件系统共存并支持跨文件系统操作。VFS通过统一的接口与各种实际文件系统交互,简化了应用程序开发和新文件系统集成。VFS的主要数据结构包括超级块、索引节点、目录项和文件对象,这些结构提供了文件系统抽象。VFS使得Linux能够实现“一切皆文件”的哲学,所有类型的文件都有一致的操作界面。通过VFS,Linux可以方便地进行跨文件系统的文件操作,如在vfat和ext3文件系统间复制文件。
虚拟文件系统(VFS)是Linux内核的关键组件,允许不同文件系统共存并支持跨文件系统操作。VFS通过统一的接口与各种实际文件系统交互,简化了应用程序开发和新文件系统集成。VFS的主要数据结构包括超级块、索引节点、目录项和文件对象,这些结构提供了文件系统抽象。VFS使得Linux能够实现“一切皆文件”的哲学,所有类型的文件都有一致的操作界面。通过VFS,Linux可以方便地进行跨文件系统的文件操作,如在vfat和ext3文件系统间复制文件。
一、VFS 虚拟文件系统基础概念
Linux 允许众多不同的文件系统共存,并支持跨文件系统的文件操作,这是因为有虚拟文件系统的存在。虚拟文件系统,即VFS(Virtual File System)是 Linux 内核中的一个软件抽象层。它通过一些数据结构及其方法向实际的文件系统如 ext2,vfat 提供接口机制。
Linux 有两个特性:
a -- 跨文件系统的文件操作
Linux 中允许众多不同的文件系统共存,如 ext2, ext3, vfat 等。通过使用同一套文件 I/O 系统调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式;更进一步,对文件的操作可以跨文件系统而执行。如图 1 所示,我们可以使用 cp 命令从 vfat 文件系统格式的硬盘拷贝数据到 ext3 文件系统格式的硬盘;而这样的操作涉及到两个不同的文件系统。
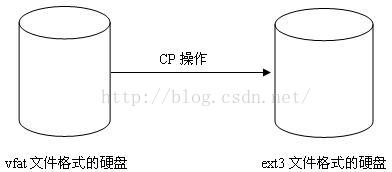
图 1. 跨文件系统的文件操作
b -- 一切皆是文件
“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。
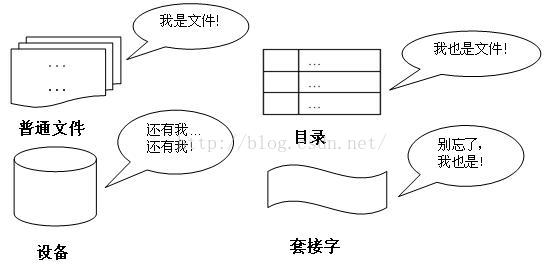
图 2. 一切皆是文件
而虚拟文件系统正是实现上述两点 Linux 特性的关键所在。虚拟文件系统(Virtual File System, 简称 VFS),是 Linux 内核中的一个软件层,用于给用户空间的程序提供文件系统接口;同时,它也提供了内核中的一个抽象功能,允许不同的文件系统共存。系统中所有的文件系统不但依赖 VFS 共存,而且也依靠 VFS 协同工作。
为了能够支持各种实际文件系统,VFS 定义了所有文件系统都支持的基本的、概念上的接口和数据结构;同时实际文件系统也提供 VFS 所期望的抽象接口和数据结构,将自身的诸如文件、目录等概念在形式上与VFS的定义保持一致。换句话说,一个实际的文件系统想要被 Linux 支持,就必须提供一个符合VFS标准的接口,才能与 VFS 协同工作。就像《老炮儿》里面的一样,“要有规矩”,想在Linux下混,就要按照Linux所定的规矩来办事。实际文件系统在统一的接口和数据结构下隐藏了具体的实现细节,所以在VFS 层和内核的其他部分看来,所有文件系统都是相同的。
图3显示了VFS在内核中与实际的文件系统的协同关系。
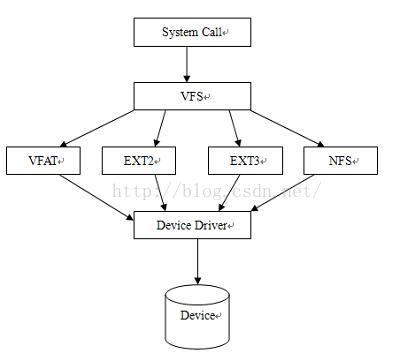
图3. VFS在内核中与其他的内核模块的协同关系
总结虚拟文件系统的作用:
虚拟文件系统(VFS)是linux内核和存储设备之间的抽象层,主要有以下好处。
- 简化了应用程序的开发:应用通过统一的系统调用访问各种存储介质
- 简化了新文件系统加入内核的过程:新文件系统只要实现VFS的各个接口即可,不需要修改内核部分
二、 VFS数据结构
1 、一些基本概念
从本质上讲,文件系统是特殊的数据分层存储结构,它包含文件、目录和相关的控制信息。
为了描述这个结构,Linux引入了一些基本概念:
文件 一组在逻辑上具有完整意义的信息项的系列。在Linux中,除了普通文件,其他诸如目录、设备、套接字等也以文件被对待。总之,“一切皆文件”。
目录 目录好比一个文件夹,用来容纳相关文件。因为目录可以包含子目录,所以目录是可以层层嵌套,形成文件路径。在Linux中,目录也是以一种特殊文件被对待的,所以用于文件的操作同样也可以用在目录上。
目录项 在一个文件路径中,路径中的每一部分都被称为目录项;如路径/home/source/helloworld.c中,目录 /, home, source和文件 helloworld.c都是一个目录项。
索引节点 用于存储文件的元数据的一个数据结构。文件的元数据,也就是文件的相关信息,和文件本身是两个不同的概念。它包含的是诸如文件的大小、拥有者、创建时间、磁盘位置等和文件相关的信息。
超级块 用于存储文件系统的控制信息的数据结构。描述文件系统的状态、文件系统类型、大小、区块数、索引节点数等,存放于磁盘的特定扇区中。
如上的几个概念在磁盘中的位置关系如图4所示。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 715
715

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









