







下周组会要讲朴素贝叶斯,朴素贝叶斯之前西瓜书上先是介绍了最大似然估计,但是我完全不知道那个理论的东西的到底能干嘛,然后找了一些资料看了下,最主要的是B站的一个视频,连接放在最后面。这个视频比较清楚的解释了极大似然估计到底是什么,它的含义是什么。
视频链接:https://www.bilibili.com/video/av56378793?p=1&t=541
极大似然估计Maximum likelihood estimation,简写就是MLE,其实在很多机器学习理论中都存在哈。
首先介绍下极大似然估计的历史:
- 1822年,高斯在处理正态分布的时候第一次提出了极大似然估计
- 1921年,美国统计学家费希尔证明了其相关特性并得到了广泛的应用,因此将极大似然估计的发现归功于费希尔。
极大似然估计的模型:
离散型:
离散型的含义就是统计量等于观测值的概率直接乘起来就可以了。
连续型:
连续型就是概率密度函数直接乘起来就可以了。
重点来了,似然函数的直观意义是什么?
似然函数的直观意义是刻画参数与真实数据的匹配程度。
什么叫匹配程度呢?就是你现在不知道一件事的发生概率,比如你去食堂找阿姨打饭,阿姨手抖不抖你不知道,但是有一段时间你亲自去食堂打饭了,打了10次饭,其中阿姨手抖了一次,那么你是不是就能得出结论说这个食堂阿姨打饭手抖的可能性并不大。也就是你看见了这个事实,你需要用一个理论去解释这个现象,这就是极大似然估计。
现在看一个例子:
有一个二项分布,如下:

上面的意思就是样本空间只可能取1或者2,取1的概率是,取2的概率是1-。我们现在去抽这个样本,抽了10次,1抽中3次,2抽中7次。现在只凭借直觉,不去想任何概率统计相关的知识,我们是不是可以认为1发生的概率是0.3,2发生的概率是0.7.
我们现在的感觉就是这样子,1发生的概率是0.3,2发生的概率是0.7,那么数学家就想,我们能不能有个办法来描述这个过程,就是用一套理论去解释这个过程?这个过程就是极大似然估计,也就是刻画参数与真实数据的匹配程度。
现在重新来看,我们一共抽取了n次,其中1被抽中n1次,2被抽中n2次,n1+n2=n。那么上面的就是n1/n。由上面的离散类型的似然函数我们有
有了这个似然函数后,我们要去算这个似然函数的最大值。疑问就在这个地方,为什么我们要把这个似然函数最大呢?
原因在于,当我们取1和2的时候分别是n1次和n2次,这是已经发生的事实了,我们要让这个事实发生的概率最大,那么我们就是要去求这个似然函数的最大值。再解释下,比如你不知道今天下不下雨,但是今天下雨了,你是不是就是要解释今天下雨的概率是1。同样的,在上面的那个取1和2的时候,也是类似的,只不过是让取1的可能性为100%是不可能的,因为发生的事实是n1次1和n2次2,所以就要去解释这个事实,就是最大化这个似然函数。
接着就是考研的时候的知识了,我们来求这个函数的最大值。
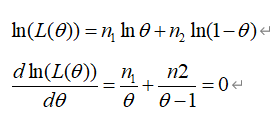
解出来就是

这是完全符合我们上面的直觉的。
好了,这就是极大似然估计的解释啦















 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









