







因分布式存储ceph集群可加入任意大小和性能的磁盘,所以我们误以为可以随意添加osd,只需要平衡一下weight值就行, 但实际操作中是会出现各种麻烦的,数据平衡或者恢复时可能造成节点直接卡死。
1、解决方案一
建议各个节点下同一个存储池pool下的osd在各个节点中容量和读写性能大致一致,且所有osd节点保持相同osd数量,不一致的采取添加磁盘的方式进行平衡。
对于容量完全不一致的,可以使用raid或zfs的方式先组成性能和容量相当的磁盘。
对不同性能的磁盘如ssd和hdd,可使用crush rule进行分组,分组后有pool类型下的osd仍然不均的可只修改对应pool类型下的crush map type,参考下面解决方案二。
2、解决方案二
调整crushmap的type,从host 调整为osd,crushmap的type为host的时,同一数据的不同副本会默认在不同的host主机之间找数据块进行存储,以防止同一个数据块的不同重复分布在同一故障主机的不同osd中,这样会造成ceph的数据在线服务中断。
但一般情况下主机down的情况比单个osd down的几率要小一些,如不在意数据在线服务的中断,只关心数据存储,可以将crush的type设置为osd,这样数据存储时只考虑将数据重复副本分布在不同的磁盘中即可,尤其是在osd节点数低于3个和osd数及容量、性能不均的情况下使用是很有效的。
osd crush map type修改:
###调整前请先注意暂停数据迁移和恢复动作,尽量在数据平衡和恢复停止后开始操作
#停止数据恢复和心跳
for i in noout nodown nobackfill norecover norebalance noscrub nodeep-scrub;do ceph osd set $i;done
###获取当前ceph的crushmap
ceph osd getcrushmap -o crushmap_compiled_file
###将获取的crushmap转换为普通文本
crushtool -d crushmap_compiled_file -o crushmap_decompiled_file
###编辑普通文本的crushmap file
vim crushmap_decompiled_file
#找到rules下的不同rule,以下是crush map中rules部分:
#################################
# rules
rule replicated_rule { ##默认情况下只有replicated_rule,表示数据不同重复副本的存储规则,默认为host方式,即同一数据块的不同重复分布在不同主机的osd中。
id 0
type replicated
step take default
step chooseleaf firstn 0 type host
step emit
}
rule rule-ssd {
id 1
type replicated
step take default class ssd
step chooseleaf firstn 0 type host ##固态硬盘在各节点分布均匀,且节点数大于3个,所以不用修改
step emit
}
rule rule-hdd {
id 3
type replicated
step take default class hdd
step chooseleaf firstn 0 type osd ###机械硬盘的分布不均,修改为osd类型,
step emit
}
####################################
存储池crush rule可自定义,根据实际需求设置crush type即可
####################################
###退出编辑保存,然后将编译后的文本类型crush map文件转换为可设置map文件:
crushtool -c crushmap_decompiled_file -o newcrushmap
###使用新生成的map文件设置crush rule
ceph osd setcrushmap -i newcrushmap
###打开心跳和数据平衡迁移
for i in noout nodown nobackfill norecover norebalance noscrub nodeep-scrub;do ceph osd unset $i;done
#观察数据平衡状态,集群会自动按照osd平衡的方式重新平衡数据
ceph -s
ceph osd df tree
下面是个人调整后的osd分布情况: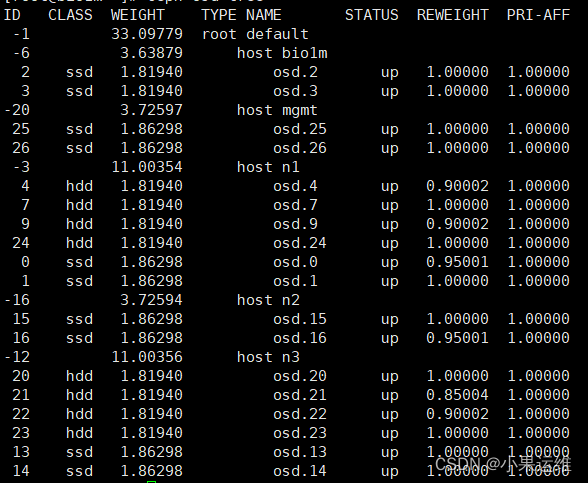
3 解决方案三:
直接添加新的osd分组,将指定pool应用新的规则,创建crush 类型时直接指定按照osd方式存储重复副本
###查看已有磁盘类型
ceph osd crush class ls
###如不满足多个类型, 先删除需要分组的osd已有类型
for i in {0..11} ; do ceph osd crush rm-device-class osd.$i;done
###将特定osd指定磁盘分组
for i in {0..11};do ceph osd crush set-device-class ssd osd.${i};done
###新建ssd和hdd磁盘对应分类规则,分布均匀的使用host type,分布不均的使用osd type
ceph osd crush rule create-replicated rule-ssd default host ssd
ceph osd crush rule create-replicated rule-hdd default osd hdd
###创建存储池并应用相应规则
ceph osd pool create ssdpool 64 64 rule-ssd
ceph osd pool create hddpool 64 64 rule-hdd
###修改pool绑定的rule
ceph osd pool set cephfs_data crush_rule rule-ssd
ceph osd pool set cephfs_metadata crush_rule rule-ssd
###查看存储池信息
ceph osd pool ls detail

















 2722
2722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











