







简介
随着技术的发展,在实际的生产环境中,由单台MySQL数据库服务器不能满足实际的需求。此时数据库集群就很好的解决了这个问题。采用MySQL分布式集群,能够搭建一个高并发、负载均衡的集群服务器。在此之前我们必须要保证每台MySQL服务器里的数据同步。数据同步我们可以通过MySQL内部配置就可以轻松完成,主要有主从复制和主主复制,常用的拓扑结构有一主一从,一主多从,双主复制、级联复制和双主级联。
MySQL主从复制(也称 A/B 复制) 是从一个主数据库服务器(Master)自动复制数据到另外一个或多个从数据库服务器(Slaves)中的过程。它通常用于在多个服务器上分布式读取数据以实现可扩展性,但也可以用于其他目的,例如故障转移或分析从服务器上的数据,多个数据备份不仅可以加强数据的安全性,通过实现读写分离还能进一步提升数据库的负载性能,以避免主服务器过载。 由于主从复制是单向复制(Master到Slaves),因此只有主数据库用于写操作,而读操作可以分布在多个从数据库上。这意味着,如果将主从复制用作扩展解决方案,则至少需要定义两个数据源,一个用于写操作,另一个用于读操作。下图就描述了一个多个数据库间主从复制与读写分离的模型(来源网络):

主从复制的特点
- 读写分离。在业务复杂的系统中,有这么一个情景,有一句sql语句需要锁表,导致暂时不能使用读的服务,那么就很影响运行中的业务,使用主从复制,让主库负责写,从库负责读,这样,即使主库出现了锁表的情景,通过读从库也可以保证业务的正常运作。
- 做数据的热备,高可用性和容错行(High availability and failover)
- 负载平衡(load balancing)
- 备份(Backups)
- 架构的扩展。业务量越来越大,I/O访问频率过高,单机无法满足,此时做多库的存储,降低磁盘I/O访问的频率,提高单个机器的I/O性能。
主从复制的原理
MySQL的主从复制是一个异步的复制过程(虽然一般情况下感觉是实时的),数据将从一个MySQL数据库(Master)复制到另一个MySQL数据库(Slave),在Master和Slave之间实现整个主从复制的过程是由三个线程参与完成的。其中两个线程(SQL线程和IO线程)在Slave端,另一个线程(I/O线程)在Master端。
- Master将数据改变记录到二进制日志(binary log)中,也就是配置文件log-bin指定的文件, 这些记录叫做二进制日志事件(binary log events);
- Slave 通过 I/O 线程读取 Master 中的 binary log events 并写入到它的中继日志(relay log);
- Slave 重做中继日志中的事件, 把中继日志中的事件信息一条一条的在本地执行一次,完 成数据在本地的存储, 从而实现将改变反映到它自己的数据(数据重放)。
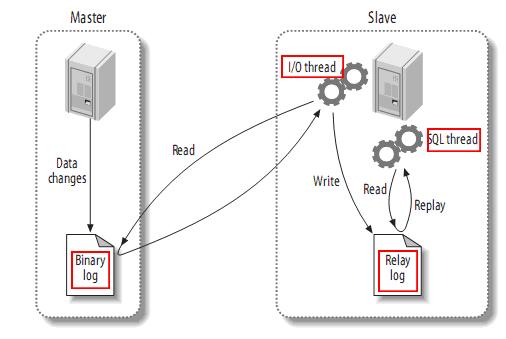
复制过程的第一步就是master记录二进制日志,在每个事务更新数据完成之前,master在二进制日志中记录数据的改变。事务串行的写入二进制日志,即使事务中的语句都是交叉执行的。在事件写入二进制日志完成后,master通知存储引擎提交事务。 下一步就是slave将master的binary log拷贝到它自己的中继日志。首先,slave开始一个工作线程——I/O线程。I/O线程在master上打开一个普通的连接,然后开始binlog dump process。Binlog dump process从master的二进制日志中读取事件,如果已经跟上master,它会睡眠并等待master产生新的事件。I/O线程将这些事件写入中继日志。SQL slave thread(SQL从线程)处理该过程的最后一步。SQL线程从中继日志读取事件,并重放其中的事件而更新slave的数据,使其与master中的数据一致。只要该线程与I/O线程保持一致,中继日志通常会位于OS的缓存中,所以中继日志的开销很小。 此外,在master中也有一个工作线程:和其它MySQL的连接一样,slave在master中打开一个连接也会使得master开始一个线程。复制过程有一个很重要的限制——复制在slave上是串行化的,也就是说master上的并行更新操作不能在slave上并行操作。
主从配置需要注意的点
主从服务器操作系统版本和位数一致;
Master 和 Slave 数据库的版本要一致;
Master 和 Slave 数据库中的数据要一致;
Master 开启二进制日志, Master 和 Slave 的 server_id 在局域网内必须唯一;
MySQL主从复制的复制方式
MySQL的主从复制并不完美,存在着几个由来已久的问题,首先一个问题是复制方式:
- 基于SQL语句的复制(statement-based replication,SBR)
- 基于行的复制(row-based replication,RBR)
- 混合模式复制(mixed-based replication,MBR)
- 全局事务标识符 GTID(Global Transaction Identifier,GTID)
基于SQL语句的方式是最古老的方式,也是目前默认的复制方式,后来的三种是MySQL 5以后才出现的复制方式。
SBR方式的优缺点
SBR的优点
- 历史悠久,技术成熟
- binlog文件较小
- binlog中包含了所有数据库更改信息,可以据此来审核数据库的安全等情况
- binlog可以用于实时的还原,而不仅仅用于复制
- 主从版本可以不一样,从服务器版本可以比主服务器版本高
SBR的缺点:
- 不是所有的UPDATE语句都能被复制,尤其是包含不确定操作的时候
- 复制需要进行全表扫描(WHERE 语句中没有使用到索引)的 UPDATE 时,需要比 RBR 请求更多的行级锁
- 对于一些复杂的语句,在从服务器上的耗资源情况会更严重,而 RBR 模式下,只会对那个发生变化的记 录产生影响
- 数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错
- 执行复杂语句如果出错的话,会消耗更多资源
RBR方式的优缺点
RBR的优点
- 任何情况都可以被复制,这对复制来说是最安全可靠的
- 和其他大多数数据库系统的复制技术一样
- 多数情况下,从服务器上的表如果有主键的话,复制就会快了很多
RBR 的缺点:
- binlog 大了很多
- 复杂的回滚时 binlog 中会包含大量的数据
- 主服务器上执行 UPDATE 语句时,所有发生变化的记录都会写到 binlog 中,而 SBR 只会写一次,这会导致频繁发生 binlog 的并发写问题
- 无法从 binlog 中看到都复制了写什么语句
混合方式
混合方式就是有mysql自动选择RBR方式和SBR方式,能够充分发挥两种方式的优点,一般情况下都使用该种方式实现主从复制
全局事务标识符 GTID
这种方式虽然能够大大提高主从复制的效率,减小主从复制的延时,但也存在问题,具体请参看下面的博客。
https://blog.csdn.net/guotao521/article/details/45483833
http://hamilton.duapp.com/detail?articleId=47
实现MySQL主从复制需要进行的配置
- 主服务器Master:开启二进制日志 binlog;配置唯一的server-id;获得master二进制文件名及位置 ;创建一个用于slave和master通信的用户账号,修改配置文件my.cnf(或者my.ini),插入如下:
[mysqld]
#开启二进制日志
log-bin=mysql-bin
#设置server-id,建议使用ip最后3位
server-id=140- 从服务器Slave:配置唯一的server-id;使用master分配的用户账号读取master二进制日志; 启动slave服务;修改配置文件my.cnf(或者my.ini),插入如下:
#开启中继日志
relay-log=mysql-relay
#设置server-id,建议使用ip最后3位
server-id=141在主机上建立账户并授权slave
GRANT REPLICATION SLAVE ON *.* TO 'mysql141'@'192.168.131.141' IDENTIFIED BY 'mysql141';
flush privileges;
--查询master的状态
show master status\G告知从服务器二进制文件名与位置
接下来就是让slave连接master,并开始重做master二进制日志中的事件。你不应该用配置文件进行该操作,而应该使用CHANGE MASTER TO语句,该语句可以完全取代对配置文件的修改,而且它可以为slave指定不同的master,而不需要停止服务器。如下:
CHANGE MASTER TO master_host = '192.168.131.140',
master_user = 'mysql141',
master_password = 'mysql141',
master_log_file = 'mysql-bin.000001',
master_log_pos = 0;
MASTER_LOG_POS的值为0,因为它是日志的开始位置。
你可以用start slave 开启复制功能;然后使用SHOW SLAVE STATUS语句查看slave的设置是否正确:当看到Slave_IO_State:Waiting for master ot send event 、Slave_IO_Running: YES、Slave_SQL_Running: YES才表明状态正常。
可查看master和slave上线程的状态。在master上,你可以看到slave的I/O线程创建的连接:在master和slave上输入show processlist\G;
但是,主从复制也带来其他一系列性能瓶颈问题:
- 写入无法扩展
- 写入无法缓存
- 复制延时
- 锁表率上升
- 表变大,缓存率下降
业务起步初始,为了加快应用上线和快速迭代,很多应用都采用集中式的架构。随着业务系统的扩大,系统变得越来越复杂,越来越难以维护,开发效率变得越来越低,并且对资源的消耗也变得越来越大,通过硬件提高系统性能的方式带来的成本也越来越高,通过读写分离,主从复制方式已经无法解决数据增长的要求。随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对N个数据库的依赖,这样的话就变成了N个数据库同时承担压力,系统的吞吐量自然就提高了。
数据库分库与分表
我们知道每台机器无论配置多么好它都有自身的物理上限,所以当我们应用已经能触及或远远超出单台机器的某个上限的时候,我们惟有寻找别的机器的帮助或者继续升级的我们的硬件,但常见的方案还是通过添加更多的机器来共同承担压力。
我们还得考虑当我们的业务逻辑不断增长,我们的机器能不能通过线性增长就能满足需求?因此,使用数据库的分库分表,能够立竿见影的提升系统的性能,关于为什么要使用数据库的分库分表的其他原因这里不再赘述,主要讲具体的实现策略。
- 垂直拆分
垂直拆分常见有垂直分库和垂直分表两种。垂直分表在日常开发和设计中比较常见,通俗的说法叫做“大表拆小表”,拆分是基于关系型数据库中的“列”(字段)进行的。通常情况,某个表中的字段比较多,可以新建立一张“扩展表”,将不经常使用或者长度较大的字段拆分出去放到“扩展表”中
另外,在“微服务”盛行的今天已经非常普及了,按照业务模块来划分出不同的数据库,也是一种垂直拆分。而不是像早期一样将所有的数据表都放到同一个数据库中
- 水平拆分
水平拆分是通过某种策略将数据分片来存储,分为库内分表和分库分表两部分,每片数据会分散到不同的MySQL表或库,达到分布式的效果,能够支持非常大的数据量。
库内分表,仅仅是单纯的解决了单一表数据过大的问题,由于没有把表的数据分布到不同的机器上,因此对于减轻 MySQL 服务器的压力来说,并没有太大的作用,大家还是竞争同一个物理机上的 IO、CPU、网络,这个就要通过分库分表来解决。
最常见的方式就是通过主键或者时间等字段进行Hash和取模后拆分
同一台主机上的主从复制:https://www.toptal.com/mysql/mysql-master-slave-replication-tutorial
参考链接:
https://blog.csdn.net/why15732625998/article/details/80463041
https://www.cnblogs.com/jirglt/p/3549047.html















 811
811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









