






刚接触AI时,只知道AI对显存的要求很高,但慢慢发现,AI对内存的要求也越来越高了。
最近尝试玩下 wan 2.1 ,进行图生视频,使用comfyui官方工作流,720p(720*1280)53帧,结果在 Load Diffusion Model 加载32G的模型时就无错误退出了,当时有留意加载过程,内存还未开始占用就中断了,所以也没想到是内存不够导致的,直到看了B站这个视频《【干货分享】使用Wan2.1模型生成高质量视频的正确姿势,ComfyUI手摸手教程》里面有个大哥说将:虚拟+物理内存 --> 增加到96G后成功加载,我试过增加到 84G都不行(因为我的硬盘所剩空间不大,一开始想着设置到够用就好),最后我一狠心增加到 104G,也终于跑起来了。
内存不够时,无疾而终:
加载过程中,占用物理内存最大达到过63.5G,下面截图是在模型刚加载完后的情况:

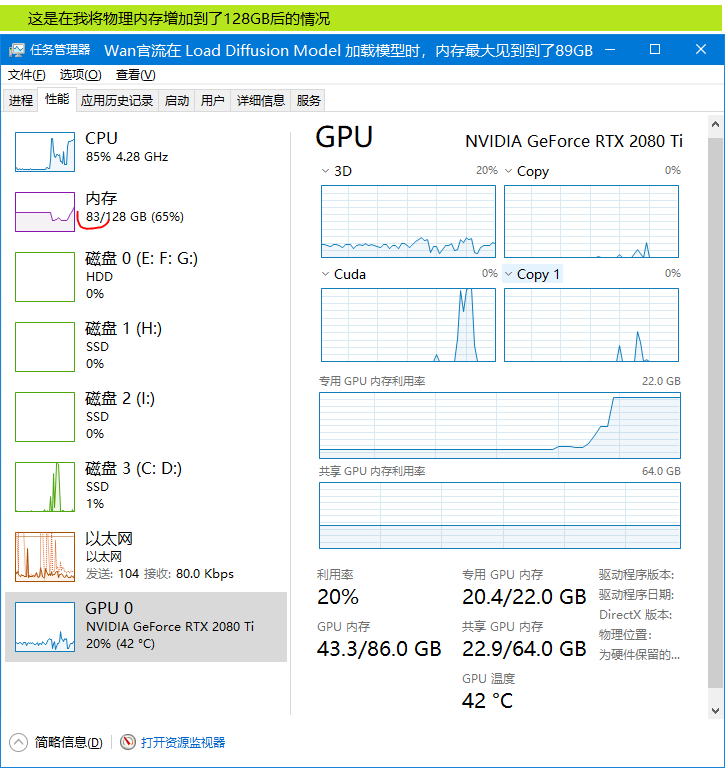 在K采样器运行时,内存占用减少,并且GPU显存占用增大:
在K采样器运行时,内存占用减少,并且GPU显存占用增大:


因为需要将总内存增加到96G以上,才能跑通 图生视频 工作流,而且发现GPU显示没有爆显存(没有使用共享显存),但会执行Copy1,而且系统盘也有数据读写,于是我就想,这个Copy1操作是否会从虚拟内存(也就是硬盘)读写数据呢?如果是从硬盘读写数据,那如果我将内存增大到不需要虚拟内存就能跑通的情况下,那这个Copy1操作将从内存读取数据,速度将比从硬盘读写数据要快得多。
---------------------------------于是有了下面的测试及观察记录------------------------------------------------
下图是在跑81帧K采样器刚开始运行时的情况,发现GPU不是满负荷运转,而且GPU会执行Copy1操作,说明GPU在操作过程中,需要不断从内存(包含虚拟内存)复制数据:

在K采样运行时,系统C盘有读写数据,不知道如果将内存增加到128,并将虚拟缓存取消,能否加快速度呢?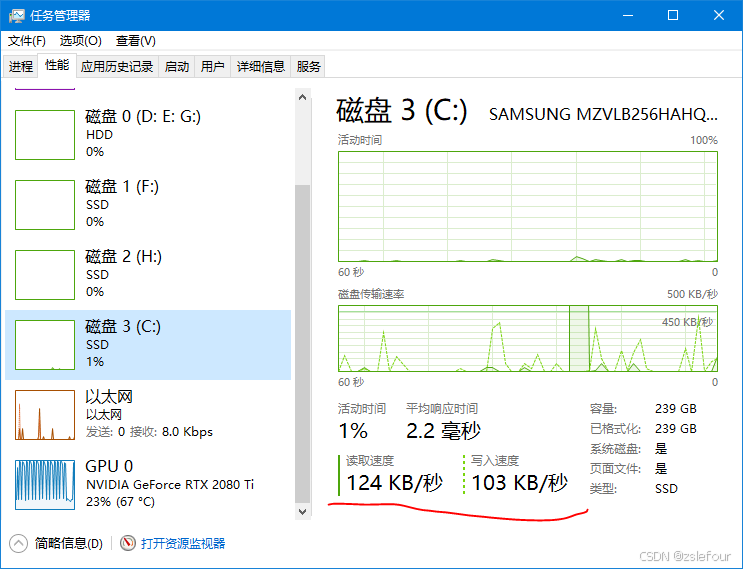
后来采用1.3B模型文生视频,并将虚拟内存完全取消,只留RAM,发现系统盘依然读写,而且该次运行,GPU并没有执行Copy1操作,也就说明硬盘读写数据并不是Copy1引起的。
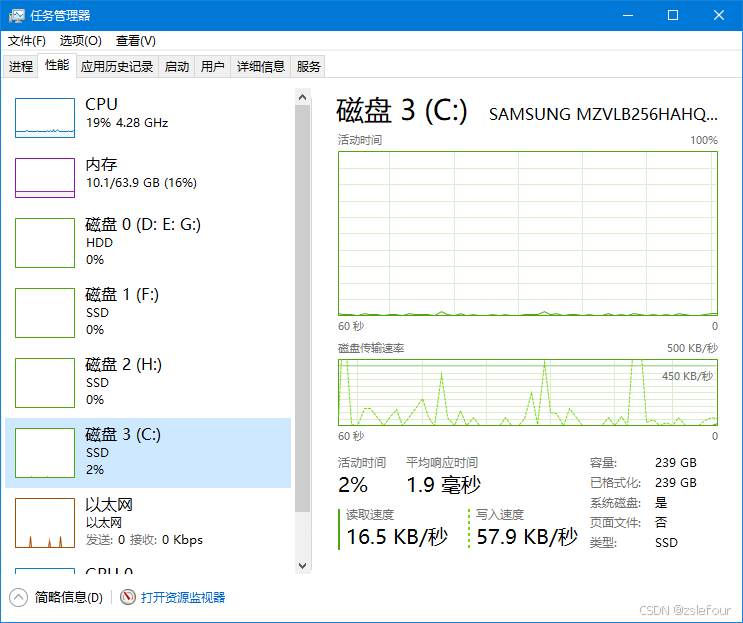
GPU满负荷工作,而且没有执行Copy1操作(但在上图中发现依然会读写系统盘,说明GPU中执行的Copy1操作,并没有从硬盘读写数据)
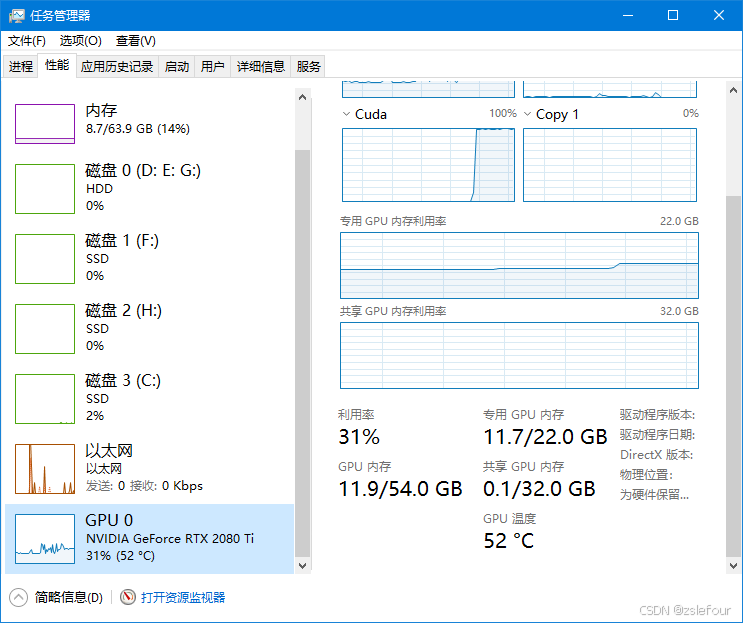
既然Copy1操作没有涉及到硬盘,也就是再怎么增加内存,对速度依然没有改进。
--------------------------------------------------------------------------------------
结论:1、要想在本地玩AI,除了显卡外,内存有能力搞多大就搞多大吧,当内存不够大时,可通
增大虚拟内存的方式,来达到Comyui对内存的需求。
2、我根据上面数据猜:Comfyui在显存不够的情况下,用到内存来存放数据。当对显存需
求超过实际显存 时,在 wan2.1 视频生成中,将使用内存存放数据,GPU从内存复制数
据,也同时将计算好的数据复制回内存,当显存需求继续增大,则会使用到共享显存,
这时候速度就超级慢,到了根本没法跑的地步,就像下面:测试5 的情况。
3、后来认真看了kijia大神 ComfyUI-WanVideoWrapper 中问题讨论区后,发现 wan 就是分
块运算的,也就是第2点中说的,Comfyui官方流也一样。之前的想法都是瞎想了。
------------------------------------------
附注:官方工作流 2080ti 图生视频耗时情况
(因为模型放在机械硬盘,下面的总时间包含了加载模型的耗时 620秒)
1、720p(720*1280)53帧(4秒) 20步:5531秒=1小时32分
(模型加载620秒+K采样4794秒+解码24秒+合成wep 90秒)
同样参数,4090D、64G内存,要18分钟(就是前面B站视频里面的UP主)
2、720p(720*1280)81帧(5秒) 20步:10716秒=2小时58分
(模型加载620秒+K采样10547秒+解码34秒+合成wep 132秒)
3、720p(720*1280)97帧(6秒) 20步:15089秒=4小时11分
4、720p(720*1280)113帧(7秒) 20步:15小时
5、720p(720*1280)129帧(8秒) 20步:显存不够,需要使用到了共享显存,没法跑,在K采样器卡死了,几个小时都没跑完1步。
官流加载模型使用都是 fp16
got prompt
Using xformers attention in VAE
Using xformers attention in VAE
VAE load device: cuda:0, offload device: cpu, dtype: torch.float16
Requested to load CLIPVisionModelProjection
loaded completely 18142.542979049682 1208.09814453125 True
Using scaled fp8: fp8 matrix mult: False, scale input: False
CLIP/text encoder model load device: cuda:0, offload device: cpu, current: cpu, dtype: torch.float16
Requested to load WanTEModel
loaded completely 16934.442393112182 6419.477203369141 True
Requested to load WanVAE
loaded completely 787.2901859283447 242.02829551696777 True
model weight dtype torch.float16, manual cast: None
model_type FLOW
Requested to load WAN21
loaded partially 15275.34289894104 15275.339477539062 0
100%|██████████████████████████████████████████████████████████████████████████████████| 20/20 [16:20<00:00, 49.02s/it]
Requested to load WanVAE
loaded completely 550.9129009246826 242.02829551696777 True
Prompt executed in 1055.13 seconds
Kj流,先跑1趟少帧的,然后再跑129帧,第一次会报 00M,第二次能继续跑下去,不过3小时一步(新买主板内存,当测试来跑的):
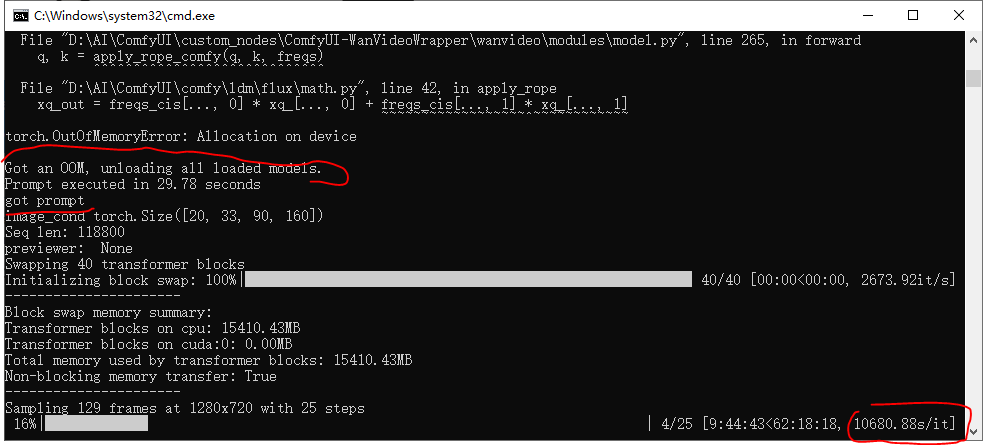
只有像下图有变化的,才能真的在跑: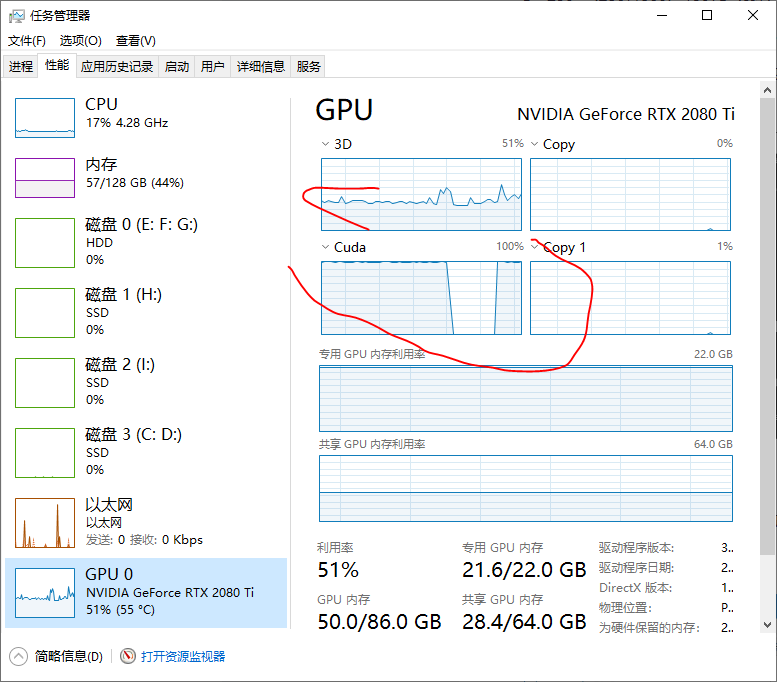
最终没有测试完,也不知道最终能否解码,也没有意义。
-------------------下面是使用kijia流跑的情况--------------------------------------
1、480p 33帧(分块:40)
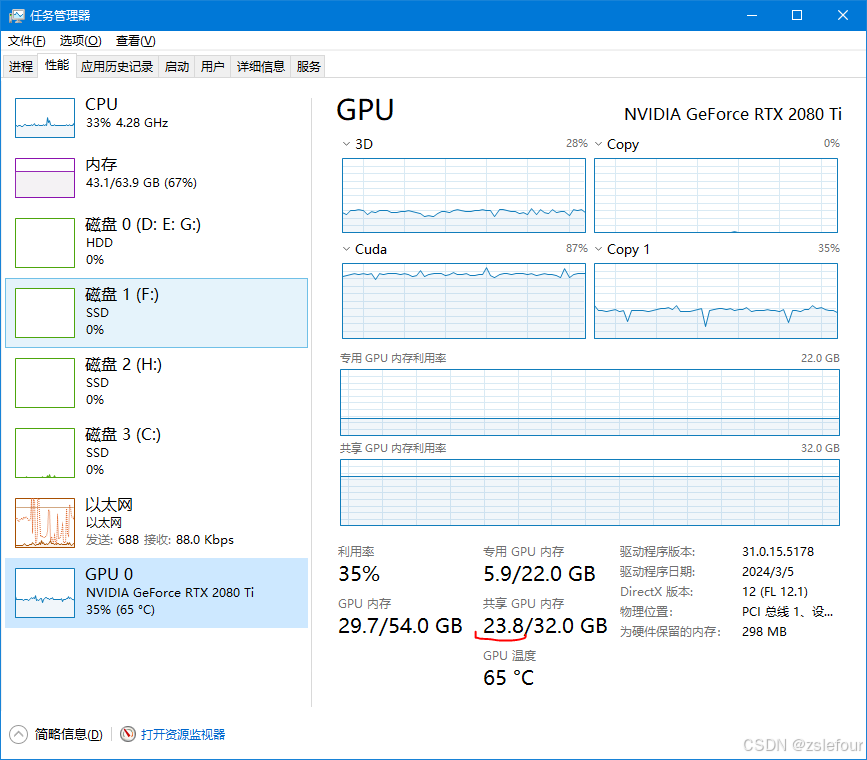
在执行WanVideo Sampler采样器时,显存占用情况:
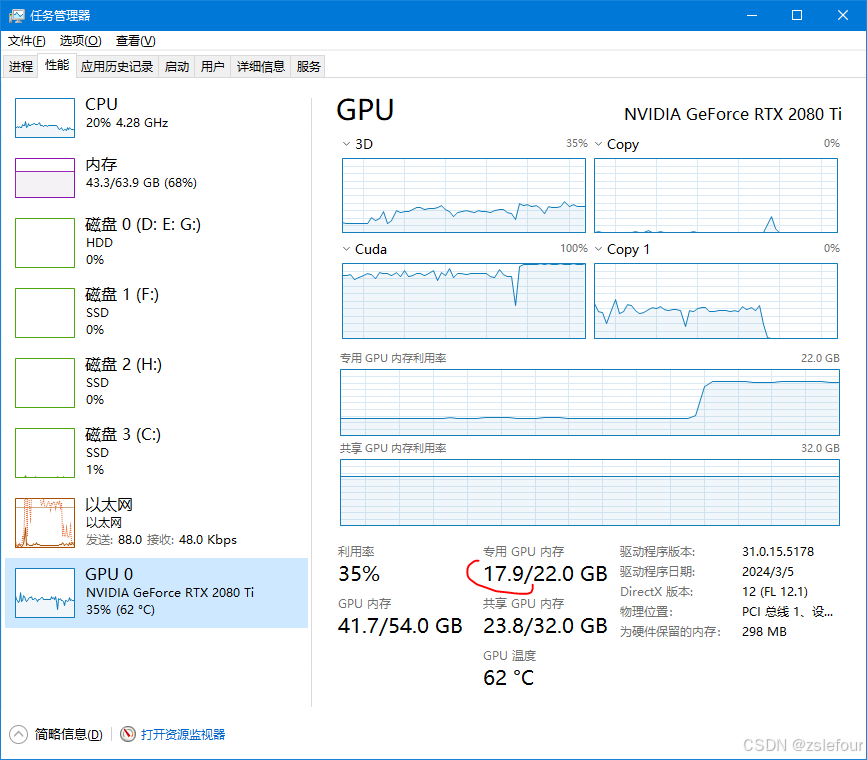
在执行WanVideo Decode解码时,显存占用增大:
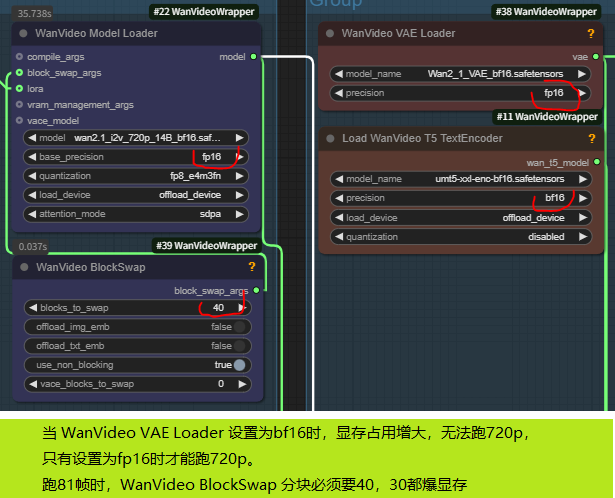
后来发现,跑Kj流,精度有2个地方都设置为fp16就没有问题了,不知道20系以上显卡设置为bf16是什么情况。
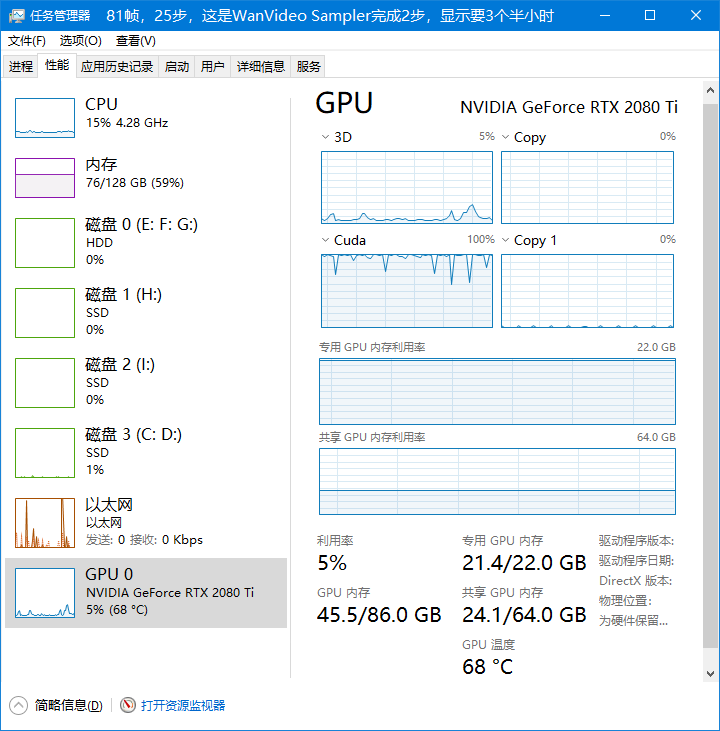
81帧实际用时9537秒=2小时40分钟,比官方工作流快点点。
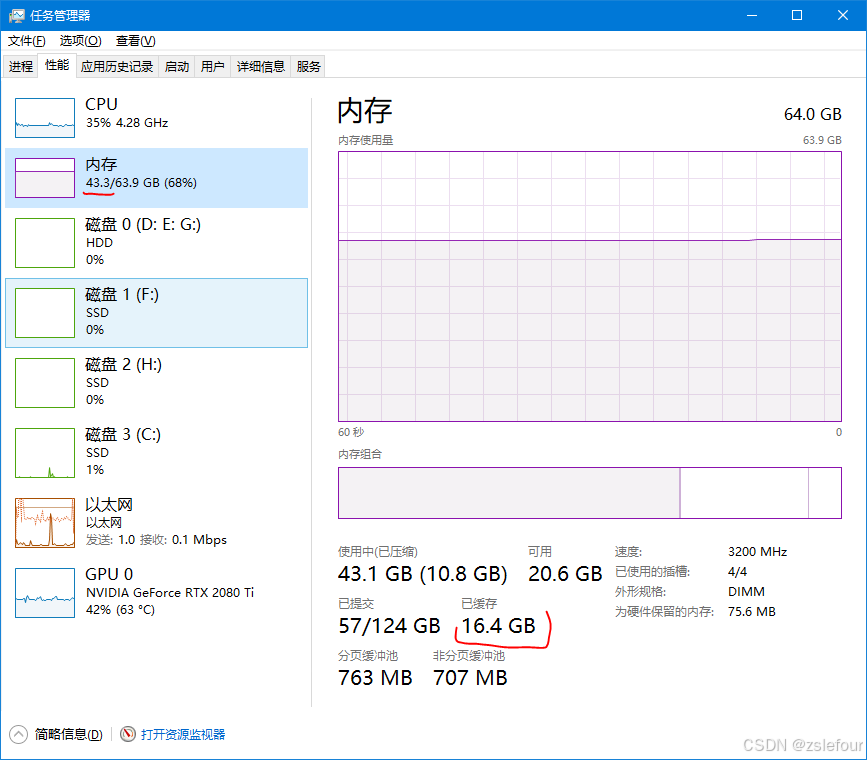
在 Windows 任务管理器的 性能 → 内存 页面中,“已提交” 和 “已缓存” 是衡量系统内存使用情况的重要指标。以下是它们的详细解析:
1. 已提交(Committed)
定义:
已提交内存 = 物理内存(RAM)中的已用部分 + 页面文件(Page File)中的预留空间
表示操作系统为所有进程承诺分配的虚拟内存总量(包括实际使用的物理内存和潜在的磁盘交换空间)。关键特性:
若 已提交 > 物理内存总量:
系统依赖页面文件(虚拟内存)扩展内存容量,可能导致性能下降(频繁磁盘读写)。若 已提交 ≈ 物理内存总量:
内存压力较高,可能需优化程序或增加 RAM。公式:
已提交 = 正在使用的物理内存 + 页面文件中已分配的空间
2. 已缓存(Cached)
定义:
操作系统将部分物理内存用于 缓存频繁访问的数据(如文件系统缓存、程序预加载数据),以加速后续操作。
可释放性:
当应用程序需要更多内存时,系统会自动释放这部分缓存(无需用户干预)。关键特性:
缓存 ≠ 已使用内存:
缓存内存属于“备用”内存,随时可被回收供其他程序使用。缓存高 ≠ 内存不足:
反而是系统高效利用空闲内存的表现(未使用的 RAM 是浪费的)。
3. 其他相关指标
指标 说明 使用中(In Use) 当前被进程和系统核心占用的物理内存(不可回收)。 可用(Available) 当前可直接分配给程序的内存 = 空闲内存 + 可释放的缓存内存。 页面文件(Page File) 磁盘上的虚拟内存文件(默认在系统盘),扩展物理内存容量(但速度远慢于 RAM)。
frame_pack,15秒,10个小时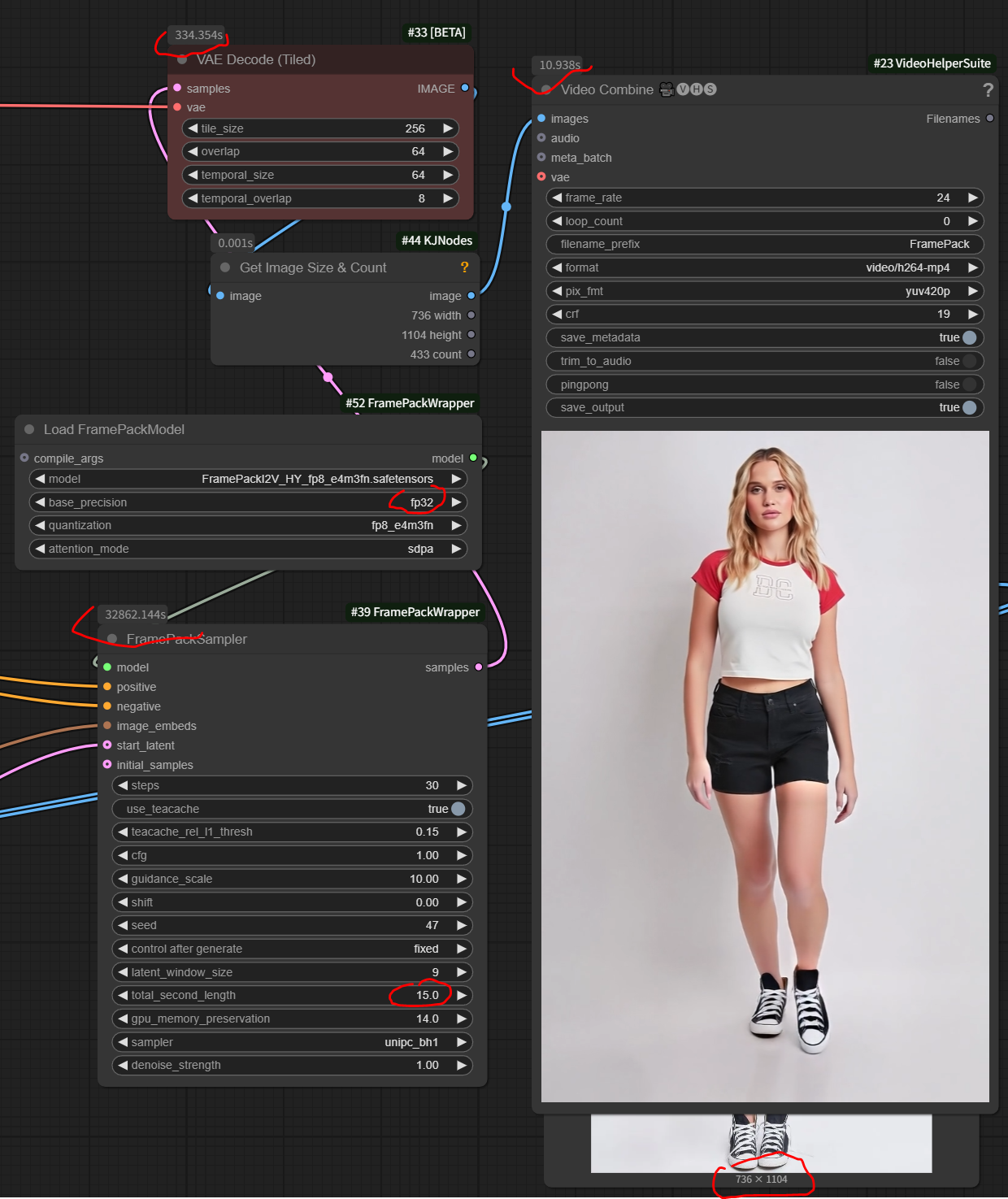
--------1151CPU 支持DDR4 128G内存的主板--------------------------------------

















 1034
1034

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









