









文章目录
GAT
主要思想
对于一个一节点,计算所有邻接节点与其的相关系数(包括该节点自身),然后通过聚合这些邻接特征得到该节点的新特征。

相关系数的计算公式
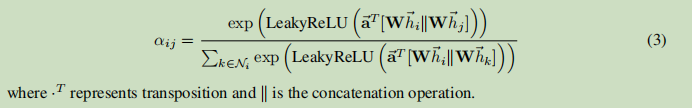
N
i
N_i
Ni表示节点
i
i
i的邻近节点,包括
i
i
i本身。
文中还涉及到一个新概念,叫多抽头注意力,如图1右边的图像所示,不同颜色的箭头都代表独立的一个注意力计算,进行多次注意力计算然后拼接或求平均。

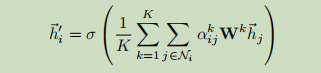
pytorch实现代码
GraphSAGE

个人认为和空域gcn思想的区别不大,都是通过聚合邻接节点的信息来更新节点,只是提供了三种不同的的聚合方式(第5行类似于跳跃连接)。其目的和node2vec一样,得到节点的向量表示供下游任务使用。
注:邻接节点是通过某个固定采样大小采样得到的(只采样了一阶邻接),并不像gcn要得到整个图的邻接矩阵,所有GraphSAGE属于归纳(inductive)学习,能泛化到未知节点,而GCN则是转导(transductive)学习,对于新增节点只能重新训练。
Mean aggregator
将自身特征与邻接节点特征一起求平均,也就是将如下公式替换掉上图算法中的4、5行,
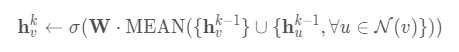
此时就类似于gcn中的传播规则了。
Pooling aggregator
分为max pooling和mean pooling,如下是max pooling的聚合方式
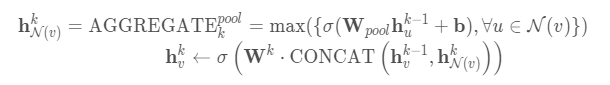
LSTM aggregator
通过将邻居序列的嵌入作为LSTM的输入来实现邻居节点的聚合。
JK-Net (Representation Learning on Graphs with Jumping Knowledge Networks)
with Jumping Knowledge Networks)
问题提出
我们知道,对于gcn,堆叠几层就相当于聚合几阶邻域的节点的信息,对于比较中心且密集的节点,层数如果较深的话,聚合信息就会很快地扩展到全图,而对于那些比较边缘且稀疏的点,如果层数较少的话,就只能聚集到局部很少的信息。作者做了一个实验来验证。

如上图,方块形的节点为起始节点,蓝色为影响的节点,对比a、b,同样扩展4步,在核心的节点的影响分布几乎覆盖整个图,在边枝节点的影响分布就很少。对比b、c,随着步数的增加,影响分布会越来越广。
作者表示,太快的信息扩张可能会导致平均范围过广,丢失重要信息,同时在一个图的其他部分,为了稳定节点表示,一个充足的邻接信息可能是需要的。至此,作者提出了一个对每个节点和任务自适应调节聚合邻接范围的网络。
网络结构

如上图,是一个4层的JK-Net,每层的输出表示聚合了不同范围的邻接信息,将每层的输出都送到最后一层进行层级聚合来得到最终输出。
层级聚合分三种:
1、拼接
拼接
[
h
v
(
1
)
,
.
.
.
,
h
v
(
k
)
]
[h_v^{(1)},...,h_v^{(k)}]
[hv(1),...,hv(k)]之后我们可以进行一个线性变换,如果线性变换矩阵是共享的,则该方法并不是节点自适应的。
2、最大池化
m
a
x
(
h
v
(
1
)
,
.
.
.
,
h
v
(
k
)
)
max(h_v^{(1)},...,h_v^{(k)})
max(hv(1),...,hv(k)),按元素选取信息最重要的层,该方法是自适应的,同时没引入任何参数。
3、LSTM-attention
对于每个节点
v
v
v计算每层
l
l
l的注意力分数
s
v
(
l
)
(
∑
l
s
v
(
l
)
=
1
)
s_v^{(l)}(\sum_ls_v^{(l)}=1)
sv(l)(∑lsv(l)=1),将
h
v
(
1
)
,
.
.
.
,
h
v
(
k
)
h_v^{(1)},...,h_v^{(k)}
hv(1),...,hv(k)输入到双向LSTM,为每层
l
l
l产生一个前向特征
f
v
(
l
)
f_v^{(l)}
fv(l)和反向特征
b
v
(
l
)
b_v^{(l)}
bv(l),将两者拼接
[
f
v
(
l
)
∣
∣
b
v
(
l
)
]
[f_v^{(l)}||b_v^{(l)}]
[fv(l)∣∣bv(l)]进行一个线性映射再加个softmax得到每层的注意力分数
s
v
(
l
)
s_v^{(l)}
sv(l),
∑
l
s
v
(
l
)
h
v
(
l
)
\sum_ls_v^{(l)}h_v^{(l)}
∑lsv(l)hv(l)得到最终输出。同样该方法是自适应的,且适用于比较大而复杂的图结构。
作者将JK-Net结合GCN、GraphSAGE、GAT在不同的数据集上都取得了不错的效果提升,且对于不同复杂程度的图数据,要采用合适的层级聚合策略才能达到最好的效果。
Towards Deeper Graph Neural Networks(DAGNN,KDD2020)
问题提出
文章表示,图神经网络(聚合邻接信息)已经取得了巨大的成功,但是这些聚合邻接信息的方法一般只能考虑低阶邻接信息(即堆叠少数几层),如果强行堆叠多层,实现更大的空间感受野,性能就会下降,最近的一些研究将这种性能下降归因于过度平滑的问题(重复传播使不同节点的表示难以区分)
文章对该问题进行了系统的分析,认为性能下降的原因主要是变换和传播的纠缠影响的,据此,文章解耦变换和传播两个操作,并提出了一个深度自适应图神经网络(DAGNN),实现了性能的提升。
图卷积网络(GCN)
这里以常见的图卷积为例
X
l
=
σ
(
A
^
X
l
−
1
W
)
X^l=\sigma(\hat{A}X^{l-1}W)
Xl=σ(A^Xl−1W)
X
′
=
X
l
−
1
W
X'=X^{l-1}W
X′=Xl−1W即为转换,
A
^
X
′
\hat{A}X'
A^X′为传播。每个gcn都要经过一个转换和传播,这样的纠缠就会导致多层gcn的性能。
深度图神经网络的实证与分析
作者为了验证自己的观点,首先给图的平滑程度做了定量分析。作者定义如下公式来描述图的平滑程度:
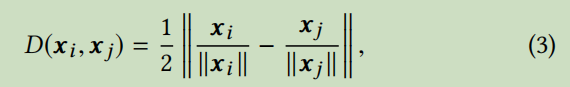
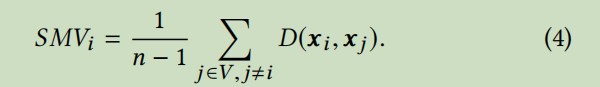
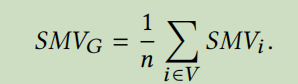
i
,
j
i,j
i,j表示不同的两个节点,
V
V
V为图的节点集,
S
M
V
G
SMV_G
SMVG即为最终图的平滑程度。
作者以GCN为例,在Cora数据集上实验,得到如下结果

从上图可知,当gcn堆叠达到6层的话,节点之间的类别就很难区分开来了。同时从下图也可看出,层数达到5之后精度下降多,平滑程度高(平滑程度值越小越平滑)。

然后作者解耦转换和传播:
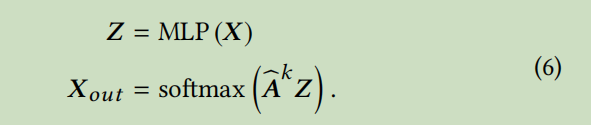
MLP是一个多层感知器,
k
k
k为传播的层数,该公式也就是做一次转换,多层传播,针对gcn即去掉后面层数中的W这个权重参数。

改为公式(6)之后得到上图的实验结果,即聚合达到75阶邻接信息时都不会存在精度大幅下降和过度平滑的问题,当然,当空间感受野极大(即达到100阶),过度平滑的问题还是会出现。
(文中还对极深的图神经网络产生过度平滑问题进行了深入的理论分析,由于涉及了大量的公式推导,本人也看的有点迷糊,这里就不介绍了,有兴趣的可以认真看看原文论文地址)
深度自适应图神经网络(DAGNN)
该网络也比较简单,就是应用了上面解耦转化和传播的思想,加上注意力机制的思想(只要是自适应,一定和注意力机制有关)实现。

上图公式中
S
~
\tilde{S}
S~即为注意力分数,给不同的k阶子图分配权重。

最后,作者在不同数据集上证明了该模型的优越性。















 5038
5038











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









