









本文思考如何将Transformer的主体结构应用到图结构数据上。
作者认为将Transformer应用到图上最关键问题是如何适合地将图的结构信息整合到模型之中。自注意力机制只计算了节点和其他节点的语义相似性,而没有考虑图上节点的结构信息和节点对之间的关系。

作者采用了如下三种方式对结构信息进行编码
Centrality Encoding
中心性编码,用来衡量节点的重要性,通过节点的入度和出度来得到中心性编码
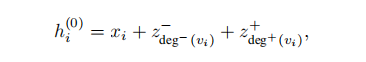
![]() 是基于入度和出度的可学习向量,如果是无向图,则出度等于入度。将其与原始节点特征相加作为输入。
是基于入度和出度的可学习向量,如果是无向图,则出度等于入度。将其与原始节点特征相加作为输入。
Spatial Encoding
空间编码。序列数据空间信息固定,方便位置编码,而图的空间结构依赖于边的连接。作者使用最短路径来作为自注意力的偏置,以此来捕获结构信息

![]() 表示两个节点之间的最短路径,如果不存在,则为-1,
表示两个节点之间的最短路径,如果不存在,则为-1,![]() 是基于最短路径的可学习标量。通过最短路径,模型会更多关注邻近节点的关系,少关注远离节点的关系。
是基于最短路径的可学习标量。通过最短路径,模型会更多关注邻近节点的关系,少关注远离节点的关系。
Edge Encoding in the Attention
作者认为将边的信息加入到相关节点中不是一个有效方式。作者同样采用了最短路径的方式,将边的信息编码到自注意力上。
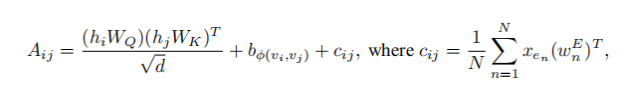
![]() 表示节点i到节点j之间最短路径中第n个边的特征,
表示节点i到节点j之间最短路径中第n个边的特征,![]() 是相应的权重参数。
是相应的权重参数。















 287
287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









