






1.文章信息
本次介绍的是题目为《Metro Pedestrian Detection Based on Mask R-CNN and Spatial-temporal Feature》的一篇发表在2020年第三届IEEE信息通信和信号处理国际会议上的文章。
2.摘要
文章介绍了一种基于深度学习网络的目标检测方法Mask R-CNN,用于从地铁车厢和车站站台的监控视频中检测行人数量,并将多帧处理的结果进行融合,以减少检测误差。为了应用和分析检测结果,文章建立车厢和站台上行人数量的时空模型。实验表明了该方法的有效性:单帧检测的平均精度为73.43%。通过融合时间序列中帧的检测结果,平均精度为88.85%,增加了21%。该方法生成的行人数量数据可用于地铁管理、行人引导、应急管理等方面。
3.简介
随着城市化进程的不断推进,人口不断向城市集聚,这给城市的运营管理尤其是公共交通系统带来了巨大的压力和挑战,因此,有必要提高管理和运营效率。这些情况促使地铁管理模式向精细化、科学化的方向发展,这就需要地铁系统中准确、丰富的行人数量等交通信息。
行人的数量反映了许多有意义的事实。由于空间有限,地铁列车车厢内行人的实时数量与操作系统中承载行人的剩余容量有关。由于行人数量与检测区域的拥挤程度直接相关,因此也可作为衡量列车舒适性的参考。此外,检测结果还可以提供更深入、更详细的地铁人流采集。有了这些信息作为参考,地铁系统的管理者可以应用地铁列车容量的动态调度和站台人流引导,安全人员可以预测和处理紧急情况,行人也可以做出更好的选择和出行计划。为了获取地铁车厢和站台上行人数量的信息,我们引入了基于深度学习的Mask R-CNN目标检测方法,从监控视频中检测行人数量,并应用多帧处理结果的融合提高准确度。
此外,文章还建立了列车车厢和站台上行人数量的时空模型,通过该模型可以应用和分析检测结果。
文章的整体内容如下:
1)回顾现有的行人数量检测研究
2)介绍检测方法和时空建模
3)给出实验的实现结果和结论
4.现有的行人数量检测研究
地铁列车和站台的人流密度可以通过多种方法进行估计,甚至可以直接检测。例如,手机信号数据有助于推断火车的占用率或交通枢纽的行人流量。然而,根据手机信号数据的行人密度并不准确,这些数据无法准确估计平台内的密度。此外,当车站和列车位于地面或地面以上时,使用手机信号数据的方法可能会出现问题。目前,监控系统得到了广泛的应用,并在各种任务和场景中提出了一组基于监控视频的行人检测方法。可以通过视频通过Hough voting框架、增强分类器、人脸检测或基于CNN的架构来检测行人对象。
在公共交通领域,监控系统也产生了大量的视频数据,各种基于视频图像处理的方法应运而生。这些方法的基本思想和共同点是通过图像处理算法来检测行人。这些方法中的一个分支应用运动目标检测算法来检测和统计穿过某些特定位置的行人。检测到的行人流量数据可以表明有多少行人通过交通系统的特定路段,但是,它无法显示特定区域(如地铁车厢内)的人群分布。另一个分支的方法侧重于在整个视频监控区域检测行人。在部分的研究中,sobel边缘检测、光流和基于规则的推理相结合,以测量视频监控区域的人群密度水平。在有些研究中,研究人员检测了行人的头部和肩部,并通过Faster RCNN在隧道中记录的监控视频中计算人群数量。根据这一想法,我们将行人检测应用于地铁车厢和站台的监控视频,以统计这些地方的人群数量。
5.检测方法和时空建模
1) 目标检测
Mask R-CNN是从R-CNN、Fast RCNN和Faster R-CNN演变而来的。它在提取RoI feature时用RoIAlign替换RoIPool,并添加允许像素级实例分割的分支,从而扩展了Faster R-CNN。给定输入图像,Mask R-CNN通过深度卷积网络提取特征映射。然后,由Faster R-CNN引入一个区域建议网络,在特征地图上生成一系列滑动窗口,并发现其中包含一个对象作为感兴趣区域(RoI)。然后,通过RoIAlign算法从图像的特征图中提取出每个RoI的小特征图,从而防止了RoIpool引入的RoI和小特征图之间的不一致,这是Mask R-CNN的重要进展之一。最后,对这些RoI特征图进行处理,以生成一系列边界框,其中包含对象的特定类别和覆盖对象的mask。
2) 时空建模
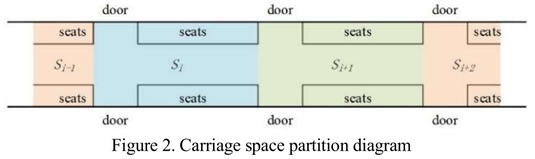
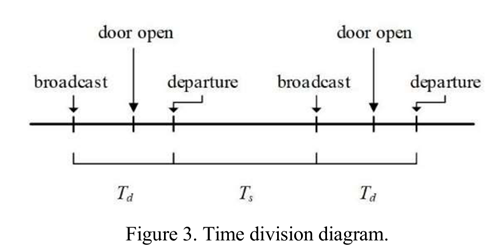
在地铁列车车厢内,行人区可分为休息区和站立区。车厢两侧的车门间隔均匀。一旦列车到达车站,一侧的门就会打开,让行人进出。当列车在两个车站之间行驶时,行人通常会在他们所处的地方迷路。当列车接近车站时,他们可能会走向车门,其中一些人会通过车门下车,当列车到达车站时,在外面等候的行人会进入,如下图Figure1。

本文将空间单位定义为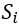 , 从一侧的一扇门开始,到同侧的下一个门结束,每个单元的一侧包含一个休息区和一扇门(见下Figure2),整个车厢空间为
, 从一侧的一扇门开始,到同侧的下一个门结束,每个单元的一侧包含一个休息区和一扇门(见下Figure2),整个车厢空间为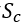
同时,将运行时间划分为动态时间段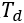 和稳定时间段
和稳定时间段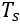 (见下Figure3)。根据实验观察,到达提醒广播与开门之间的平均时间为50秒。在此期间,行人一般开始向门口移动,因此人群变得活跃起来。此外,车门打开至列车发车的平均时间为40秒。到这段时间结束时,行人通常已经找到了合适的停留地点,因此人群再次变得稳定。
(见下Figure3)。根据实验观察,到达提醒广播与开门之间的平均时间为50秒。在此期间,行人一般开始向门口移动,因此人群变得活跃起来。此外,车门打开至列车发车的平均时间为40秒。到这段时间结束时,行人通常已经找到了合适的停留地点,因此人群再次变得稳定。
因此,文章动态时间段从车站开门前50秒开始,到开门后40秒结束。其余运行时间(开门后40秒至下一扇门关闭前50秒)属于稳定时间。根据地铁的具体信号系统,可以对这些时间段进行不同的设置。至于站台,行人可以随时到达,并选择安全门等待火车,人群总是动态的。定义一个空间单位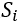 ,从一扇安全门的一侧开始,到下一扇安全门的同一侧结束,整个平台空间为
,从一扇安全门的一侧开始,到下一扇安全门的同一侧结束,整个平台空间为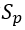 ,平台空间划分图如下Figure4。
,平台空间划分图如下Figure4。

每秒可用帧数为f帧,每秒运行一次检测过程,检测时刻为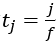
在地铁列车车厢中, 空间里时刻
空间里时刻 车厢内的行人数量是
车厢内的行人数量是
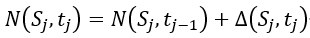
这个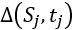 是指
是指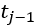 到
到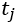 之间不断变化的行人数量。如果行人数量变化率
之间不断变化的行人数量。如果行人数量变化率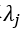 在这两个时刻之间的是非负的,假设
在这两个时刻之间的是非负的,假设 遵循以下公式
遵循以下公式
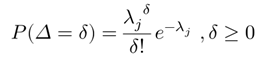
在火车车厢里,当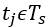 ,
,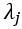 通常接近于0。与地铁车厢相似,站台内行人数量
通常接近于0。与地铁车厢相似,站台内行人数量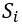 在空间里
在空间里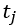 时刻车厢内的行人数量是
时刻车厢内的行人数量是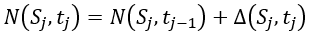 ,其中
,其中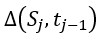 服从下列分布
服从下列分布

这个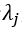 是行人数量在
是行人数量在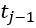 到
到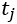 行驶过程中的变化率
行驶过程中的变化率
3) 检测
每个在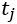 时刻进行的检测过程中,已计算的行人人数为
时刻进行的检测过程中,已计算的行人人数为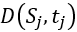 ,并且
,并且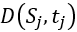 和
和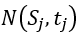 的关系为
的关系为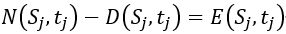 。其中,
。其中,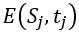 是由于人群的高密度和监控视野不好引起的算法与遮挡问题
是由于人群的高密度和监控视野不好引起的算法与遮挡问题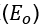 ,造成的遗漏或者计算错误
,造成的遗漏或者计算错误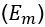 。
。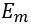 由于检测算法的准确性出问题而发生,这个问题可以通过使用地铁行人视频数据集训练Mask R-CNN的网络重量来降低发生率。
由于检测算法的准确性出问题而发生,这个问题可以通过使用地铁行人视频数据集训练Mask R-CNN的网络重量来降低发生率。 由于人群阻塞而发生,当人群移动时,某一刻被他人阻挡的人可能会在另一刻出现。融合时间序列帧的检测结果,可以降低遮挡的影响。
由于人群阻塞而发生,当人群移动时,某一刻被他人阻挡的人可能会在另一刻出现。融合时间序列帧的检测结果,可以降低遮挡的影响。
遵循这个想法,在平台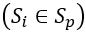 的场景中,设最小检测周期为1s,第k秒输出行人检测次数为
的场景中,设最小检测周期为1s,第k秒输出行人检测次数为
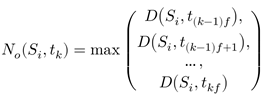
在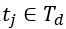 时刻的车厢场景
时刻的车厢场景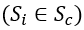 ,第k秒的行人检测输出数量与站台上的相同。
,第k秒的行人检测输出数量与站台上的相同。
为了使得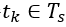 整个周期设置为一个检测周期,输出编号为
整个周期设置为一个检测周期,输出编号为
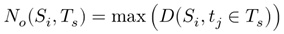
4) 错误分析
为了克服遮挡的影响,文章在一个检测周期内取检测到的行人数量的最大值。但是,它可能会导致另一个错误(文章称其为理论错误),因为在周期内特定检测时刻的实际行人数量可能会发生变化。例如,在检测周期T中,有一个时刻,该地区的行人数量S达到峰值时,该峰值将被记录为输出。但到了第T周期结束时,行人仍停留在S并且小于输出编号。最坏的情况是检测周期中大量行人可以到达空旷区域的时刻人群以最快的速率λ涌入地区S并在被记录后以同样的速度迅速离开这个区域。检测输出将是S能够保持的最大行人数量,而大多数时间T,可能并没有行人通过。
实际上,在动态期间,例如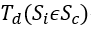 整个过程在站台上都有
整个过程在站台上都有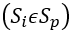 。检测周期短,这意味着行人没有足够的时间完成一个区域。因此,理论误差的最大期望值是
。检测周期短,这意味着行人没有足够的时间完成一个区域。因此,理论误差的最大期望值是
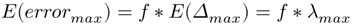
根据学者关于人群密度和移动速度之间关系的研究,最大行人流量为1.3人/(m*s)。在宽约2米的地铁车站站台上,最大行人流量可达2人。每秒6人。这意味着最大的变化率是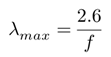 ,因此,预计误差为2.6人。在稳定期
,因此,预计误差为2.6人。在稳定期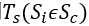 ,检测周期很长,但行人通常不会移动,如前所述,λ通常接近0。因此,理论误差近似为0。
,检测周期很长,但行人通常不会移动,如前所述,λ通常接近0。因此,理论误差近似为0。
6.实验
文章对从上海地铁采集的视频和从上海地铁10号线实际监控系统采集的部分地铁列车内部视频进行了检测实验。还拍摄了一些11号线上海汽车城站和安亭站站台的视频,以及上海汽车城站和光明路站之间的列车车厢视频。使用Mask R-CNN检测行人,算法代码来自GitHub程序,Mask R-CNN用于Keras和TensorFlow上的目标检测和实例分割。这些代码基于特征金字塔网络(FPN)和ResNet101主干网。视频的帧速率为每秒25帧。因此,在实验中,检测率f设置为25。
1) 地铁车厢
下列TABLE1显示了行人下车时动态周期的检测结果示例。由于行人在移动,且行人的相对位置不断变化,遮挡效应在严重和轻微之间快速频繁地变化。检测错误源于未能检测到未被阻挡的行人(丢失错误)。在一些超过一半的行人未被检测到的帧中,可以发现检测结果不令人满意。TABLE 2显示了行人在原地停留时稳定期的检测结果示例。在这一时期,遮挡的影响几乎一直是显著的,这对检测误差有很大的贡献,而缺失误差保持在较低的水平。
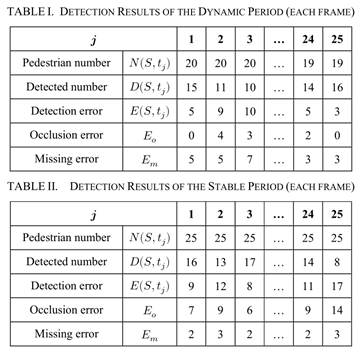
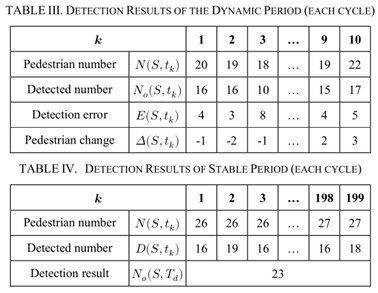
TABLE3显示动态周期的10秒检测样本。行人数量变化在预期范围内,1秒内融合了25个结果,检测效果较好。然而,与几秒钟相关的一些结果仍然不令人满意,这有不同的原因,例如检测算法的准确性以及检测周期设置缺乏足够的灵活性,因此单个帧的更好检测可能仅与周期相隔一或两帧,但不包括在内。此外,考虑行人离开时人数的变化有助于改善结果。TABLE4显示了一个与整个稳定周期(作为一个周期)相关的检测结果示例,结果比预期的要好。在稳定期内,实际行人数量不会发生太大变化,较小的移动有助于减少遮挡的影响。
2) 站台
下图中显示了行人在一秒钟内等车上车时站台的检测结果。这种情况下的缺失错误几乎为0,因为平台中的视频拍摄具有高清晰度和分辨率。遮挡误差是检测误差的主要来源。

7.结论
结合基于深度学习的目标检测算法和多帧信息融合,可以通过监控视频有效检测地铁车厢和站台上的行人数量,减少检测误差。结合文章建立的时空模型,这些检测结果数据可以有效地应用和分析,获得上述场景的行人数量信息。实验还揭示了性能改进的可能性。在实验中,单帧检测的平均精度是73.43%,通过融合时间序列中帧的检测结果,平均精度为88.85%,增加了21%。由于多帧信息融合可以减少遮挡效应,因此最大的问题是漏检。通过对地铁行人图像的数据集训练Mask R-CNN的网络权值,可以克服这一问题。
Attention
如果你和我一样是轨道交通、道路交通、城市规划相关领域的,可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











