







文章信息

论文题目为《TimeCMA: Towards LLM-Empowered Multivariate Time Series Forecasting via Cross-Modality Alignment》,论文提出了一种基于大语言模型的时间预测框架,通过模态对齐的方式实现使用LLM进行预测,并提出使用最后一个token进行解码的方法降低计算成本。

摘要

多变量时间序列预测(MTSF)旨在学习时间序列之间的时序动态以进行预测。现有的统计和深度学习方法在学习可变参数和大规模训练数据时存在问题。近年来,基于大语言模型(LLM)的时间序列预测方法在MTSF中取得了有前景的表现。然而,我们发现现有的基于LLM的解决方案在学习可分离的嵌入方面存在困难。我们提出了TimeCMA,一个通过跨模态对齐有效学习的MTSF框架。具体来说,我们提出了一个双模态编码框架,包括两个分支:时间序列编码分支提取可分离的但仍然很弱的时间序列嵌入,而LLM增强分支将时间序列与文本作为提示一起处理,以获得纠缠但鲁棒的提示嵌入。作为一种整体,跨模态对齐通过从时间序列和提示嵌入中获取计算相似性来提取既可分离又鲁棒的时间序列嵌入。为了减少计算成本并加速推理过程,我们设计了一个有效的框架,使得最重要的时间信息封装在最后一个token中:仅传递最后一个token作为后续预测的输入。进一步的实验证明,TimeCMA在八个真实数据集上的表现优于现有的最先进方法。

引言

来自交通和环境等领域的大量时间序列数据,推动了多变量时间序列预测(MTSF)等应用的发展。MTSF旨在挖掘历史数据中变量之间的时序动态,以预测未来的时间序列,帮助用户做出主动决策,例如投资选择或天气预报。
MTSF方法可以分为统计方法和深度学习方法。然而,有限的可学习参数和小规模的训练数据限制了这些方法的表现和鲁棒性。近期的进展将预训练的LLM引入时间序列,通过从丰富的语言数据中学习到的鲁棒嵌入进行时序建模。
现有的LLM基础时间序列预测方法可以根据输入数据类别分为两类:(1)基于时间序列的LLM,用随机初始化的嵌入层替换LLM的tokenizer来处理时间序列数据。然而,这种嵌入层的训练会导致时间序列与语言数据之间的领域差距。(2)基于提示的LLM通过在时间序列中引入额外的提示信息,以帮助LLM理解时间序列预测任务。提示通过对时间序列的描述与文本相关联,以促进嵌入学习。
尽管基于提示的LLM在性能上取得了显著的进展,但它们仍面临数据纠缠的问题。具体来说,现有的方法将时间序列嵌入与文本提示嵌入进行拼接,这些融合的嵌入随后被输入到后续的时间序列处理阶段。然而,输出的嵌入是纠缠的,这会削弱预测性能,因为文本信息被当作噪声。那么,如何减轻噪音文本嵌入的问题呢?如图1(c),一种尝试是将时间序列值包裹在文本提示中,加强时间序列嵌入,同时保留文本,以便LLM理解。
为了应对这一挑战,我们提出只有可分离且鲁棒的时间序列嵌入才是最适合MTSF的,并且可以通过我们的直观跨模态对齐设计通过相似性检索来有效实现,如图1(d)。总体而言,我们提出了一个基于LLM的框架,通过跨模态对齐进行多变量时间序列预测,称为TimeCMA。该框架具有一个双模态编码模块,其中包括一个时间序列编码分支和一个LLM增强的编码分支、一个跨模态对齐模块和一个时间序列预测模块。时间序列编码分支从历史时间序列数据中提取变量嵌入。LLM增强的提示编码分支将时间序列作为提示来获取经过充分训练的嵌入。跨模态对齐模块通过信道-维度相似性检索来集成这两组嵌入,从而增强预测。
尽管如此,基于提示的LLM仍然面临计算成本高的问题,因为: (i) 多变量时间序列(MTS)数据的特性:与N个变量的时间序列数据相比,LLM处理MTS数据时需要更多的计算资源。 (ii) 高计算成本:由于多头自注意力机制,LLM生成高维输出并需要大量计算。 (iii) 冻结LLM参数的重复处理:在训练过程中,现有的基于提示的LLM对冻结的LLM执行在线处理,因此每个训练样本在每个训练时期都被重复处理,这使得推理速度较慢。
为了减轻计算负担,我们进一步提出了“最后一个token”的方法。在提示中,我们独立地将时间序列的每个变量包裹,并将其调整为LLM理解每个提示的方式。通过只将该嵌入与时间序列一起馈送,我们可以减少计算成本。(2) 离线存储:我们存储每个提示的最后一个token,以便对冻结的LLM进行离线处理,从而加速推理速度。
综上所述,主要贡献包括:
(1)识别跨模态LLM在时间序列预测中的数据纠缠问题,并提出TimeCMA框架,通过与LLM结合学习可分离的嵌入。
(2)设计跨模态对齐模块,通过信道-维度相似性从LLM增强的提示嵌入中提取鲁棒的时间序列嵌入,增强预测。
(3)为了减少计算成本,我们设计了最后一个token嵌入的策略。我们进一步将这些嵌入存储为离线信息,以减少冻结LLM的重复处理。
大量实验证明,TimeCMA在多个数据集上的表现优于现有的最先进方法。
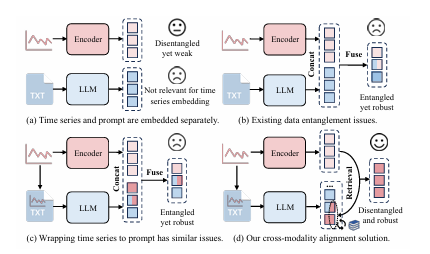
图1 不同实现方法对比

方法论

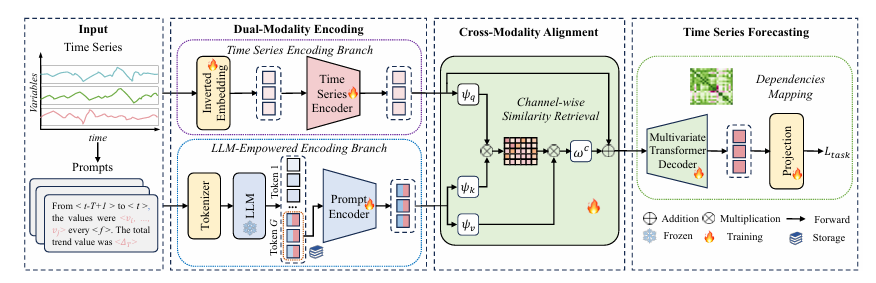
图2 模型框架图
TimeCMA主要模块分为:双模态编码、跨模态对齐和时间序列预测模块。
双模态编码:包括一个时间序列编码分支和一个LLM增强的编码分支,用于有效地学习输入时间序列和提示的嵌入。
时间序列编码分支:由一个反向嵌入层和一个时间序列编码器组成。反向嵌入层将变量的整个时间序列视为一个token,生成嵌入。该时间序列编码器有效地捕捉了变量之间复杂的时序依赖关系。
反向嵌入:给定时间序列数据,反向嵌入层将时间序列转换为变量嵌入,以捕捉变量的时序依赖性。该数据经过标准化处理以减轻时间序列分布偏移,然后被转换为变量嵌入:
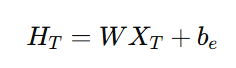
时间序列编码器:将变量嵌入输入到一个轻量级的编码器中,称为TSEncoder(·),该编码器借鉴了Transformer结构,并应用层归一化来稳定训练过程。与原始Transformer相比,Pre-LN Transformer具有更好的稳定性和更快的训练速度。TSEncoder(·)对嵌入执行两次层归一化:
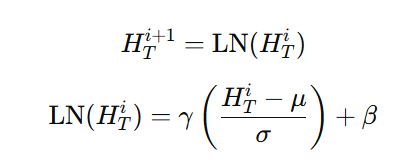
接下来,它们经过多头自注意力机制和前馈网络处理,输出嵌入。通过残差连接将其结合:
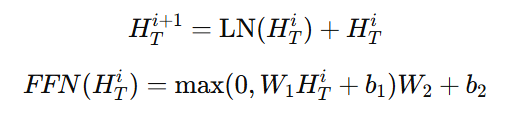
LLM增强的编码分支:预训练LLM从输入的tokens中学习,使其比传统编码器模型更高效。选用GPT-2模型生成时间序列嵌入:
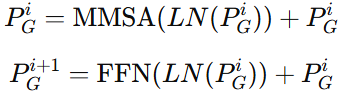
跨模态对齐:为了聚合时间序列和提示模态,我们设计了基于信道-维度相似性检索的跨模态对齐模块。其目的是根据提示嵌入的相似性,检索时间序列嵌入。
首先,通过线性层将HT和LN分别转换为三个紧凑的嵌入:
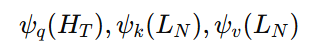
然后,通过信道-维度相似性计算获取跨模态对齐的嵌入:
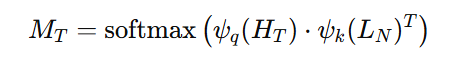
时间序列预测:我们设计了一个时间序列预测模块,包括一个多变量Transformer解码器和一个投影函数。首先,我们将对齐的时间序列嵌入HC输入到层归一化模块中:
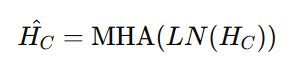
接着,进入第二个层归一化模块,并通过注意力层进行解码。
最终,解码后的向量被输入到投影函数中,以进行未来的预测:
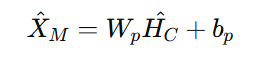

实验

1.数据与实验环境
我们在八个数据集上进行了实验:ETTm1、ETTm2、ETTh1、ETTh2,ECL,FRED-MD,ILI和Weather。我们删除了FRED-MD中的缺失值变量,并将其简化为FRED。
我们评估了五类中的八个基线模型:(1)基于提示的LLM:Time-LLM、UniTime;(2)基于时间序列的LLM:OFA;(3)基于Transformer的模型:iTransformer、PatchTST和FEDformer;(4)基于线性方法的模型:Dlinear;(5)基于CNN的模型:TimesNet。评估指标为均方误差(MSE)和平均绝对误差(MAE)。测试批次大小设置为1,以确保测试期间的公平性。每个实验至少重复三次,使用不同的种子和NVIDIA A100 GPU。
2.总体表现
表1展示了TimeCMA在所有基线模型中的平均表现。
(1) 基于LLM的模型在所有情况下表现优于深度学习和线性模型。这些结果验证了我们使用LLM进行多变量时间序列预测的动机。(2) 反向嵌入对于捕捉多变量依赖关系至关重要。对于具有更多变量的数据集,TimeCMA能够表现得更好,因为我们在TimeCMA中引入了反向嵌入和多变量注意力机制。(3) 基于提示的LLM优于基于时间序列的LLM。基于提示的LLM,如TimeCMA,优于基于时间序列的LLM和OFA,MSE和MAE分别提高了16.1%和11.9%。这表明提示增强了时间序列的嵌入。与UniTime相比,TimeCMA在MSE上平均提高了约13.9%,在MAE上提高了12.6%。
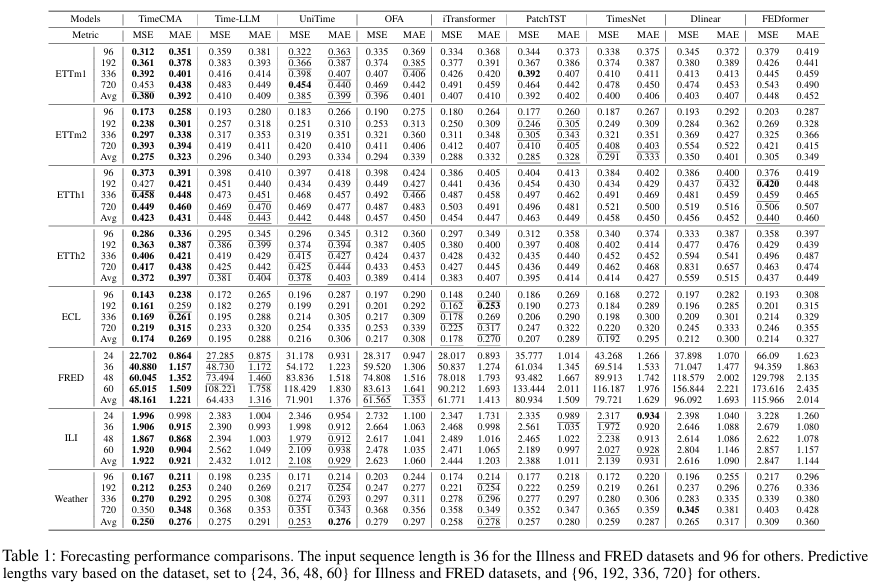
表1 模型结果对比
2.消融实验
图3显示了模型设计的消融研究,结果是跨所有预测长度的平均值。对预测结果影响最大的变体是去除跨模态对齐(w/o Alignment)。通过这种方式,我们用相似性检索替换了跨模态设计,这表明我们的跨模态设计优于拼接。接下来是去除LLM(w/o LLM),这意味着双分支的预测结果比时间序列分支更好。没有时间序列编码器(w/o TS Encoder)的情况下,退化结果表明提取可分离的时间序列嵌入对预测至关重要。我们发现,去除提示编码器(w/o Prompt Encoder)的影响最小,因为LLM能够捕捉变量之间的依赖关系,并且提示编码器的作用是为后续的跨模态对齐做准备。此外,去除解码器(w/o Decoder)表明解码多个变量之间的长期时序依赖关系对MTSF非常重要。
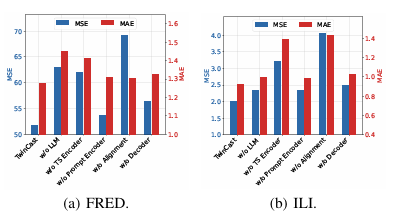
图3消融实验结果

结论

本文提出了TimeCMA,一个通过跨模态对齐赋能LLM的多变量时间序列预测框架。跨模态对齐模块旨在根据信道间相似性检索来聚合时间序列和LLM分支,以增强预测性能。TimeCMA在使用最后一个token嵌入来减少计算成本和加速LLM方法推理速度方面表现出良好的前景。充分的实验结果提供了对TimeCMA有效性和效率的深入见解。


















 406
406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











