






1.文章信息
本次介绍的文章为《A Random Effect Bayesian Neural Network (RE-BNN) for travel mode choice analysis across multiple regions》,发表在Travel Behaviour and Society上。该工作在经济学的随机效用理论下,利用深度学习进行了跨区域的出行行为选择的预测,并且对于英国不同区域的人们出行行为进行了分析。
2.介绍
出行方式选择建模在预测乘客出行需求和规划交通系统方面发挥着关键作用。传统选择建模通常采用经典的随机效用模型(Random Utility Models)来分析个体基于效用理论的决策。最近,随着深度学习的兴起,许多研究利用神经网络来进行出行方式选择的建模和预测分析。但使用深度学习进行出行方式的选择建模有两个挑战:(1)在行为分析领域对模型的可解释有着较高的要求,而深度学习模型经常被视为不可解释的(2)出行方式存在区域异质性,如果对于所有区域训练同一个预测模型会损失预测精度。考虑到这两个挑战,本研究基于效用理论,通过结合随机效应 (RE) 模型和贝叶斯神经网络 (BNN),设计了一种随机效应贝叶斯神经网络 (RE-BNN) 框架,用于预测和解释跨多个地区的出行方式选择。结果表明该模型在预测准确性方面优于普通的全连接网络,并且在对于不同数据集有着更强的泛化能力。此外,在模型解释方面,训练后的RE-BNN模型可以从三个方面来进行不同区域行人的出行行为分析:偏移效用(offset utilities)、选择概率函数(choice probability functions)和本地出行方式份额(local travel mode shares)。
3.模型
1. 区域特定的随机效用模型(Region-specific random utility model)
自1981年 McFadden提出随机效用模型(Random Utility Models,RUM)以来,该方法已成为建模出行模式选择的主要模型。基于每个备选方案都提供给个体一定程度的效用这样的假设,RUM 依赖于具体明确每个替代方案能提供的效用的多少。然而事实上,我们并不可能观察到这些效用。因此,对于每个备选方案,对于个体i而言,第k个方法的效用 是确定性效用 和随机效用 之和,分别代表观察到的变量和未观察到的变量的影响:
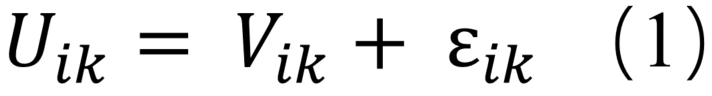
确定性效用 是关于 的函数,其中 是第i个观测变量,包括了个体相关的和行程相关的属性。随机效用 一般由确定性效用 决定。
随机效应(Random Effects,RE)模型是一种分析多级数据的统计方法,包括纵向重复测量数据。一个明确规定的RE模型可以提供比固定效应(Fixed Effects ,FE)模型更多的信息。与所有观测值共享一个共同效应的FE模型不同,RE模型允许效应大小变化,因此它们可以描述不同“集群”的不同行为。
在本研究中,由于对出行方式选择的偏好可能因地区而异,因此RE模型用于描述不同地区个体的不同出行行为。RE模型通过在等式(1)中引入随机影响因子 与RUM相结合,使得我们能够适应不同地区的偏好异质性,并实现特定地区的RUM:
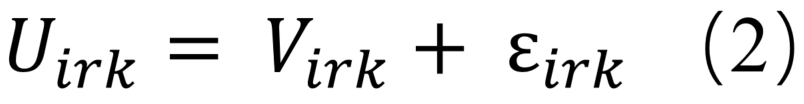
此时式中的确定性效用 是关于 和 ,其中 是一个区域可变自变量。在效用理论的背景下,可以将其视为居住在第r个区域的人们对于选择k的偏移(offset)效用。
在效用最大化行为理论中,人们倾向于在做选择的时候选择能够提供最大效用的选择k,这个概率可以描述为:
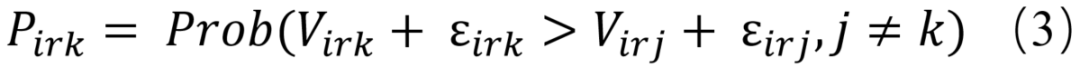
假设随机效 用服从Gumbel分布,选择备选方案k的概率可以表示为:
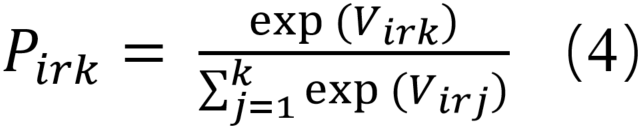
2. 神经网络建模区域特定选择
神经网络(Neural Network,NN)被证明可用于分析出行方式选择。当假设随机效用项 服从Gumbel分布时,可以将Softmax激活函数的输入变量视为效用、Softmax激活函数的输出表示替代方案的概率:
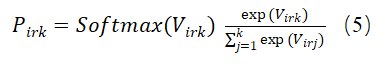
用NN建模区域特定的选择效用可以表示为:
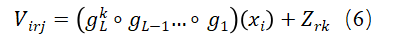
其中,
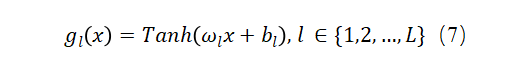
每个 由线性和非线性单元(即激活函数)变换组成,其中 是包含第l层中随机权重的参数矩阵, 将最后一层的输出转换为选择k的效用,L代表总层数。 是居住在r区域的人对于选择k的偏移(offset)项。这个项对模型有两个贡献:首先,它表示区域项是这个NN模型中的随机效应;其次,它有助于模型的可解释性,因为它代表了偏移效用,其变化可以用来分析不同地区的旅行行为和偏好的差异。
3.RE-BNN (随机效应-贝叶斯网络)
由于全链接网络对于超参数敏感,为了提高从NN中提取的经济信息的可靠性,本研究选择贝叶斯神经网络(BNN),通过引入权重的不确定性来避免过度拟合以及提高预测质量。基于效用理论和随机效应模型,我们设计了随机效应贝叶斯神经网络(RE-BNN)来预测和分析跨区域的出行模式选择。给定数据集 ,包含N个行程记录 ,区域 ,和标签 。P表示输入的维数, 表示所有参数矩阵。根据贝叶斯方法,先验分布 基于参数矩阵 。当后续数据被观测到时,这个分布会改变。可以表示为:
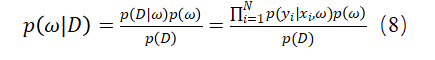
有了这个分布,我们可以根据新观测到的输入来更新网络并做预测:
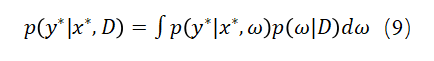
然而,由于这个后验分布 难以计算,一般使用变分推断来训练BNNs。该方法通过找到一个可处理的变分分布 的参数来近似后验分布 ,找到合适的参数使得该变分分布与真实后验分布 的偏差最小。Kullback-Leibler(KL)散度被广泛用于测量两个分布之间的差异:
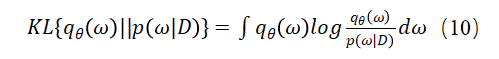
然而最小化KL散度也很棘手,因为它直接依赖于真实的后验分布 。不过最小化KL散度等价于最大化ELBO:
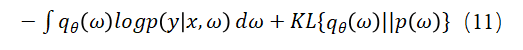
变分推断是贝叶斯建模中的标准方法。变分推断将后验推断问题转化成了优化问题,可以通过基于梯度的方法进行优化。在本研究中,采用ELBO作为损失函数来找到参数、b和z的最佳分布。
4.数据集
实验使用的数据集为英国交通部(Department for Transport)公开提供的2005年至2016年国家旅游调查(National Travel Survey ,NTS)数据集。根据受访者的家庭地址,研究区域分为九个区域:North East, North West, Yorkshire and the Humber, East Midlands, West Midlands, East of England, London, South East, and South West。从2005年到2016年,每年有69208户家庭的121765名受访者接受采访。经过简单的数据清理,数据库总共包含2100492个关于他们所有出行活动细节的观察结果,包括出行方式、目的、原始目的地、目的地、旅行时间和旅行距离。该数据库还提供有关受访者家庭和他们自己的信息,包括性别、教育收入、汽车拥有量和就业情况。原始数据库由几个相互关联的子表组成,其中包含个人、家庭、态度、旅行、车辆阶段和日间水平。根据前文讨论的出行方式选择的决定因素,为每个人选择了15个变量,这些地区的人口密度数据由大伦敦管理局提供。在数据集中,输出表示模式替代。为了保持选择的区域一致性,对数据预处理时合并了多个选择。合并后,有五种出行方式可供选择:步行、自行车、驾驶、公共汽车和铁路(包括伦敦地铁)。输入 是每次旅行的属性,y和r代表每个旅行社的受访者的家庭地区。
5.实验结果
本节通过与四个模型(即BNN、DNN、MNL和MXL)的比较,展示了RE-BNN模型的预测性能。然后,描述了RE-BNN模型关于偏移效用、选择概率函数和当地出行方式份额的解释。
1. 预测表现
图1显示了baseline和RE-BNN模型的预测精度结果。对于三个基于NN的模型,颜色相对较浅的曲线表示每个单一训练结果的预测精度,深曲线是所有训练结果的平均精度。结果表明, RE-BNN、BNN和DNN的平均预测精度分别比MNL模型和MXL模型高10和2左右,与之前的研究一致。RE-BNNs和BNNs的平均预测性能相似,超过DNNs约1至2个百分点。这表明,RE-BNNs预测能力的提高主要归因于将贝叶斯不确定性引入NNs。除了与DNN相比具有较高的预测精度外,不同年份数据集的RE-BNN曲线更稳定,表明它的泛化能力更强,能够更好地适应不同的数据集。
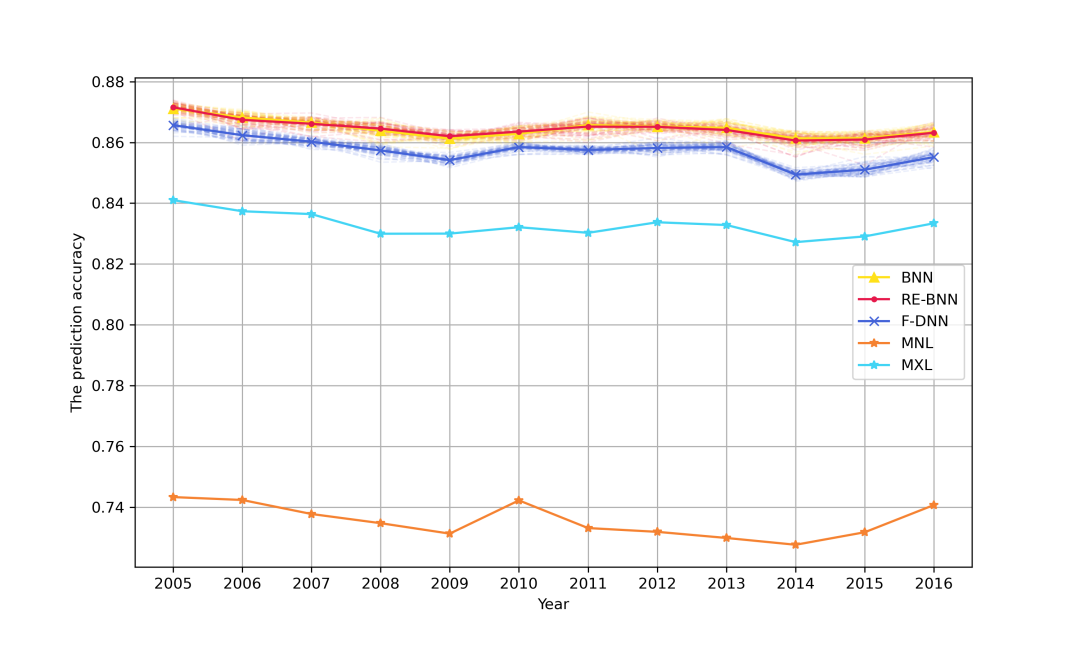
图 1
因为在我们的模型中引入随机效应参数的主要目的是提高模型学习区域异质性的能力,所以本研究还调查了RE-BNN和其他三个模型的局部预测精度。图2显示了2016年数据集训练的这五个模型在不同地区的预测精度。注意,三个ML模型的精度由50个训练结果的平均值表示。图中显示,与其他地区相比,这五种模型(包括REBNN模型)对伦敦出行方式选择的准确度都相对较低。这一结果表明,RE-BNN模型在预测不同地区的个体水平出行方式选择方面没有明显优势。然而,对于所有地区,RE-BNN和BNN的预测准确度都高于DNN。
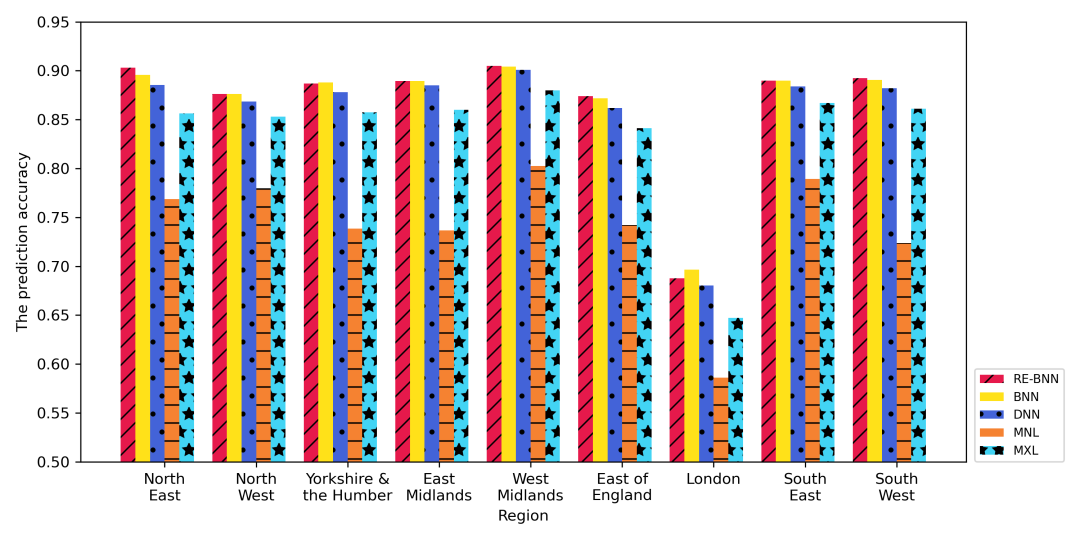
图 2
2. RE-BNN的解释性
由于我们是基于经济学的效用理论设计的网络,因此我们可以通过从模型中提取的行为信息解释RE-BNN。具体来说,我们分析了选择偏好的区域异质性、五种不同模式的选择概率函数和跨区域的市场份额。
2.1跨区域出行模式的偏移效用
基于效用理论和等式(6),区域特定随机效应参数 可以视为行为分析区域r的模式k的偏移效用。因此,通过比较该参数的值,我们可以分析同一出行方式的不同效用以及不同地区乘客出行偏好的异质性。图3显示了2016年的RE-BNN模型中区域特定随机效应参数 的变化。每个方框的长度表示从50次RE-BNN训练结果中获得的随机效应参数的变化程度,每个方框的位置表示在这五个备选方案中生活在不同地区的人们选择旅行方式的抵消效用的平均水平,在选择铁路作为交通方式的行为偏好方面,地区差异最为显著。当其他变量相同时,铁路为居住在伦敦的人带来的效用要比居住在其他地区的人大得多,这与以下事实相一致:地铁作为一种便捷的交通工具,仅服务于伦敦和部分邻近县。在所有地区中,选择居住在东北部的铁路的效用最小,而伦敦铁路的效用最高,与生活在其他地区的人相比,公共设施费用是最低的。造成这种现象的潜在原因是伦敦的社会政策环境与伦敦拥堵收费并不友好,伦敦拥堵费是2003年推出的一项缓解伦敦市中心交通拥堵的措施。根据这项政策,进入市中心约16公里的汽车充电(2003年为£5,2016年为£11.50),这降低了伦敦居民的驾驶效用。在伦敦东部和西南部,乘客在乘坐公交车时更喜欢选择在东北部行驶。关于步行的偏好,没有明显的地区差异。
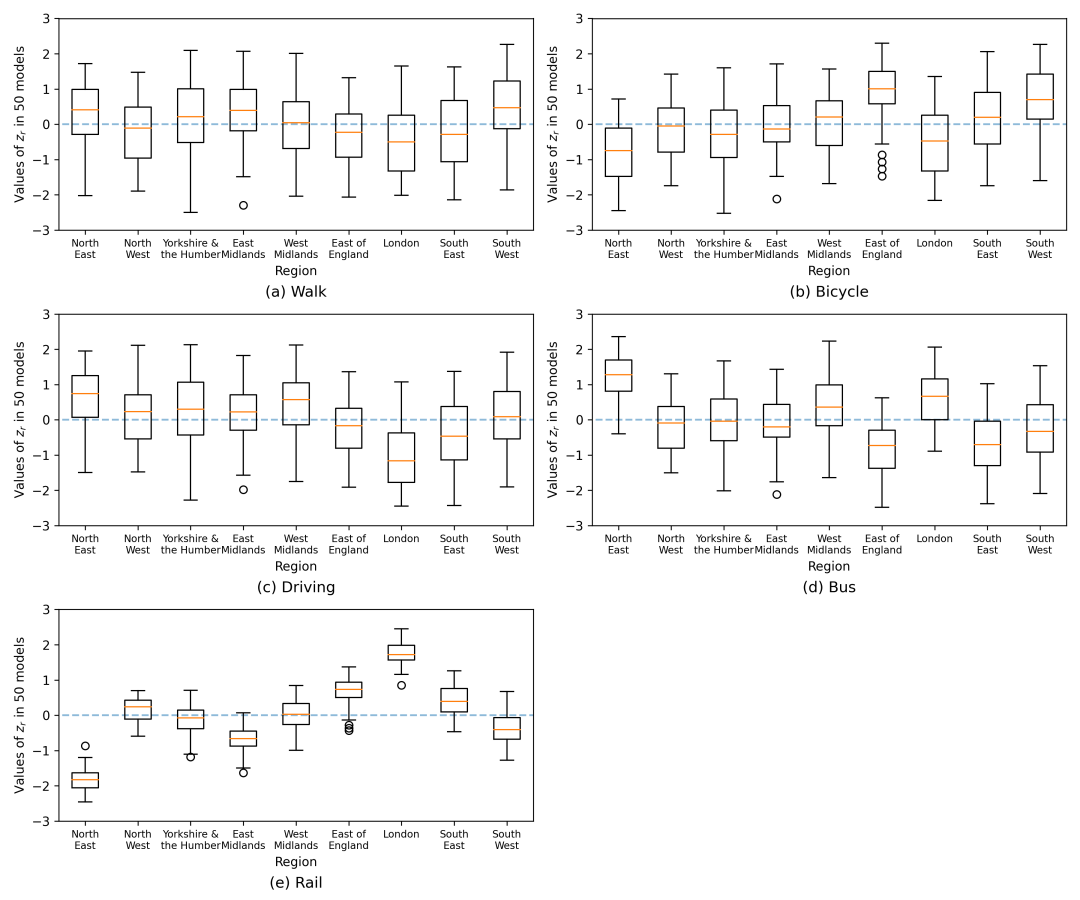
图 3
我们还可以调查生活在不同地区的人们出行方式效用的时间变化。每年的随机效应参数的平均值用于表示抵消效用的总体水平。图4显示了不同地区的这个参数,在2005年至2016年期间,备选方案各不相同。每个方框代表的是这一时期五种出行方式偏移效用的变化程度。每个盒子的位置代表了这一时期不同地区居民抵消效用的总体水平,与盒子类似,这种相似性表明,2016年出行方式选择行为偏好的地区差异与过去12年的平均水平相似。图4a、4c、4d和4e中的短盒子长度表明,选择步行、驾驶、公共汽车和铁路并不十分明显。相比之下,骑行作为一种出行方式的效用在同一时期发生了更大的变化。
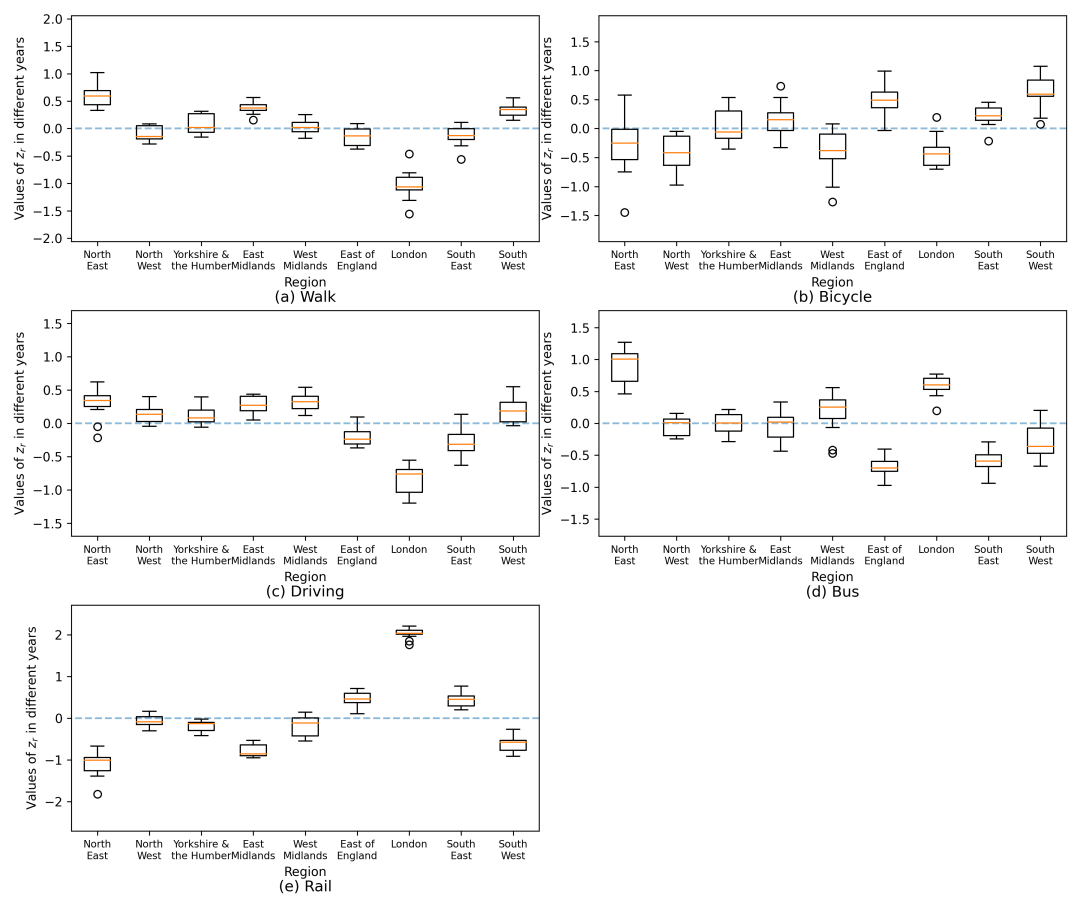
图 4
2.2 跨区域选择概率函数
根据效用最大化理论,各种备选方案带来的地区差异直接导致出行方式选择概率的地区异质性。每个备选方案的选择概率函数可以通过数值模拟可视化。图5和图6可视化了RE-BNN和BNN中的选择概率如何发挥作用(2016年数据集训练)。在不同地区,当保持所有其他特征值与行程值一致时,随着行程时间的增加而变化。灰色曲线表示每个子图中的每个训练结果,彩色曲线是所有训练结果的平均值。可以看到,图5a中灰色曲线的显著变化,5c和5d表明,尽管使用相同的数据集进行训练并显示出相似的预测能力,但RE-BNN模型中这些备选方案的选择概率函数却截然不同。然而,值得注意的是,这些不规则的行为模式并不一定是负面的,因为它们可能存在于其他文献中,可以被视为成功识别了灵活的行为模式。
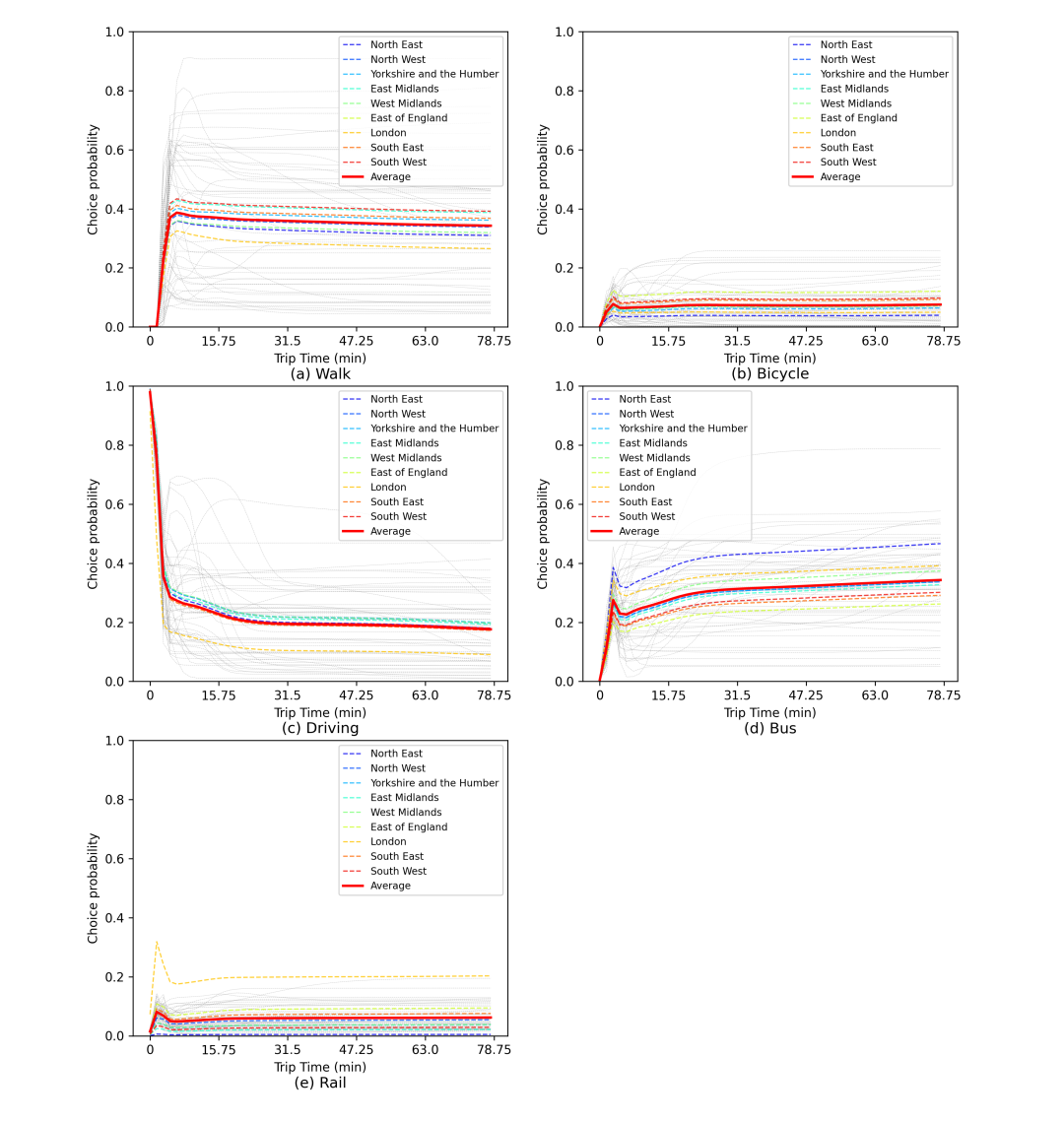
图 5
根据图5,总体而言,平均线(图中用红色表示)代表概率变化的总体趋势。当行程时间值非常接近零时,驾驶的概率相对较高。随着出行时间的增加,驾驶概率呈下降趋势;乘车和步行的可能性增加,然后趋于平稳;然而,骑乘和乘坐铁路的可能性仍然保持在较低的水平。BNN所了解到的概率函数也有类似的趋势(图6),只是灵活性较差。大多数曲线都是直观合理的,尤其是驾驶和乘坐公交车。人们可能更喜欢短途自驾,但当出行时间过长时,他们可能更倾向于乘坐公共交通工具,如公共汽车。同时,轨道和自行车的选择概率对出行时间的敏感性较低。然而,步行概率函数可能会遇到可解释性问题,尤其是BNNS学习到的。这一问题可能归因于出行时间变量不是特定的,根据本研究中使用的数据集提供的数据。
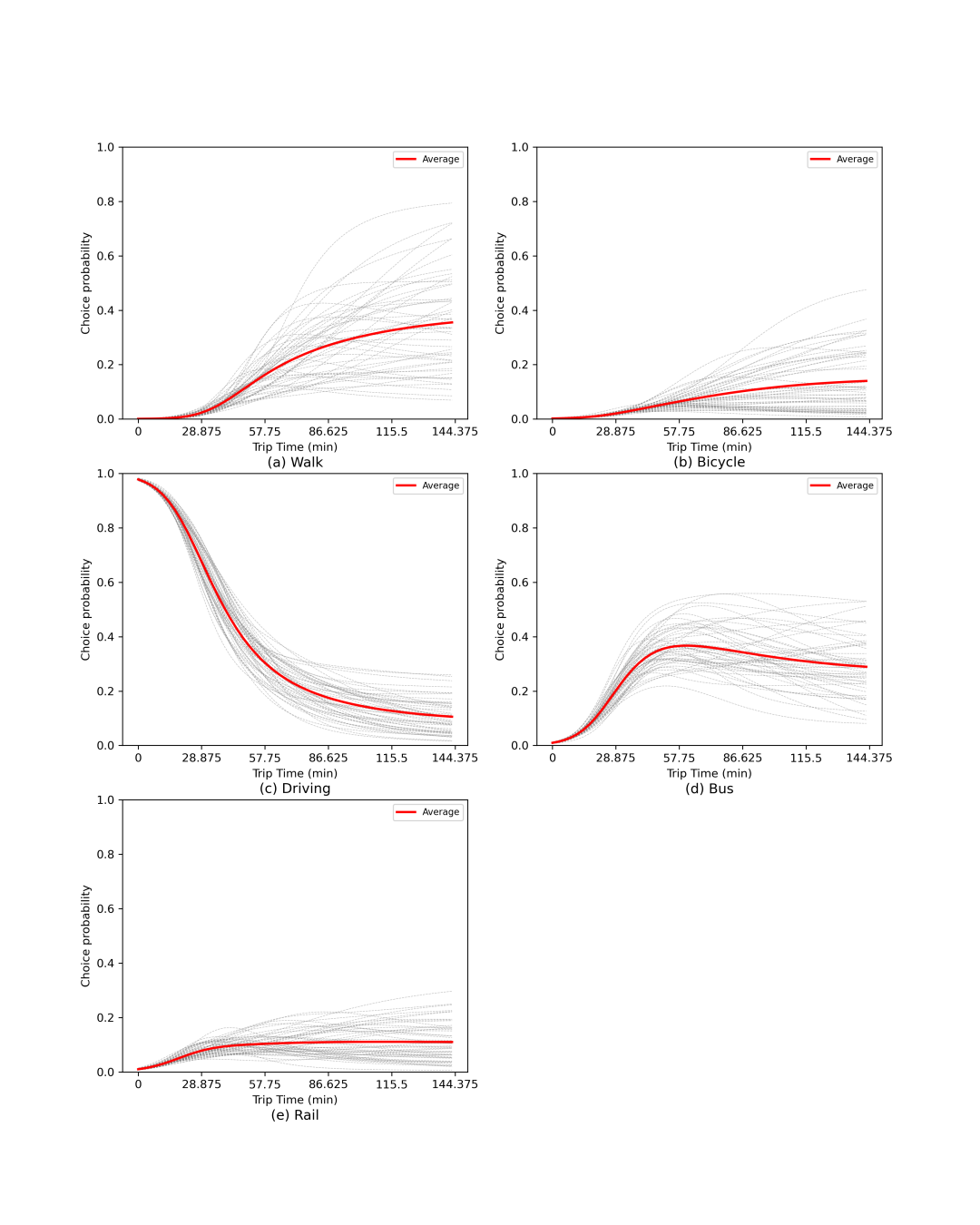
图 6
根据地区差异,彩色曲线描述了不同地区乘客的选择概率函数,展示了RE-BNN在不同区域自动学习所选概率函数的能力。对于相同的出行模式,曲线越分散。出行模式行为的区域差异越显著。高于区域平均曲线的曲线(在每个子图中用红色曲线表示)表明,选择此出行模式可以带来更多这一地区的乘客效用与其他地区的乘客相比,反之亦然。在图5e中,橙色曲线(代表伦敦乘客的选择概率)比所有其他曲线高出约10%至20%。该值意味着当其他变量相同时(如年龄、收入、出行距离等),100名乘客中,与其他地区相比,伦敦选择铁路的人数要多出10至20人。在选择步行和驾驶作为出行方式的行为中可以观察到相反的情况(如图5a和5c所示)。虽然不同地区的骑行行为差异不大,但图5b中的彩色曲线与选择概率函数的学习相比非常集中。相比于RE-BNN,BNN无法捕获不同区域的概率函数。
2.3.跨地区的出行方式份额预测
本小节显示了本地市场份额或每种出行方式的预测结果。上一节的研究的预测能力可以视作是在个人层面上,而本小节讨论的出行方式份额可以被视为总水平预测能力。
表1描述了预测的出行方式市场份额的平均预测结果。括号中的值是50次训练结果的标准差。根据表中所示,RE-BNN预测结果的值与实际出行方式份额非常接近。表2量化了预测误差。表2括号中的粗体值和数字分别表示各地区预测的总市场面积的平均值和标准差。RE-BNN模型各地区的平均值总和(1.38%)是四个模型中最小的,表明RE-BNN对总市场份额的预测结果是最准确的,优于其他模型。RE-BNN模型的标准偏差(0.72%)也小于其他三个模型,表明其对各地区总市场份额具有稳定的预测能力。
表 1
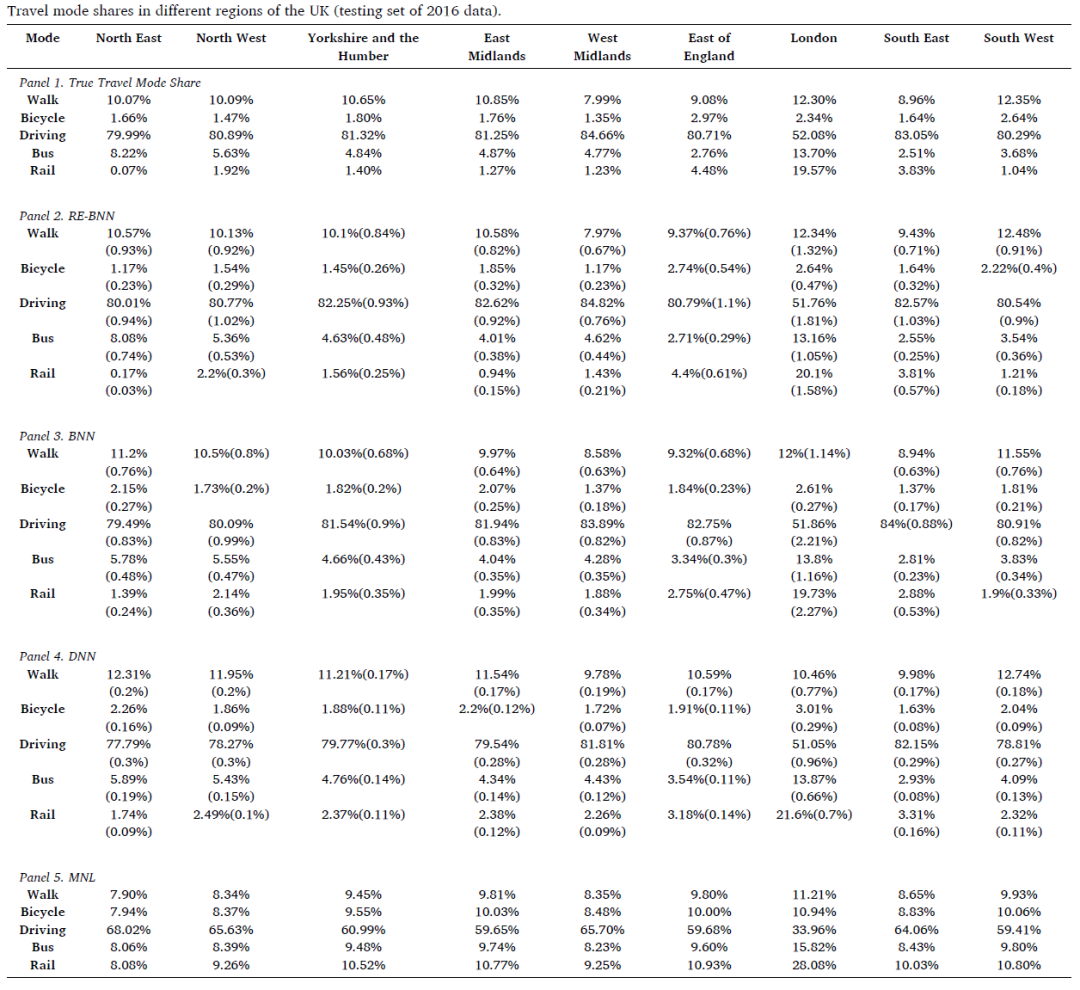
表 2

6.结论
虽然许多研究使用深度学习方法预测出行方式选择,但没有一项研究揭示出行方式选择的区域异质性。为了填补这一研究空白,本研究设计了一种随机效应贝叶斯神经网络(RE-BNN)来预测跨区域的出行方式选择并揭示区域异质性,与全连接神经网络模型相比,RE-BNN模型在结构上有两个改进:(1)引入了区域特定偏移效用的随机效应项;(2)引入了贝叶斯不确定性以增强模型预测准确性的稳定性。本研究通过在2005年至2016年英国国家出行方式选择的数据集上,展示了RE-BNN模型的优点。最重要的是,RE-BNN模型能够自动学习并揭示出行方式偏好的区域异质性,这是模型无法办到的。例如,从RE-BNN模型导出的偏移效用项和选择概率函数可以看出,与其他地区相比,伦敦居民对铁路的偏好更高,对驾驶的偏好更低。除了其对地区出行偏好的良好的解释力外,RE-BNN模型在个人层面和聚集层面的角度上也比DNN和MNL模型取得了更好的预测性能。此外,RE-BNN模型对不同年份的数据集更为稳健,优于DNN和MNL模型。
这项研究为未来的研究方向提供了线索。首先,RE-BNN模型有潜力探索其他不同的社会群体之间的旅游偏好,包括不同的年龄组,不同年代之间,尤其是千禧一代的旅行行为已经得到研究人员越来越多的关注。第二,可以加入一些与地区相关的因素作为变量来使得RE-BNN在多个地区具有更好的预测性能。
Attention
欢迎关注微信公众号《当交通遇上机器学习》!如果你和我一样是轨道交通、道路交通、城市规划相关领域的,也可以加微信:Dr_JinleiZhang,备注“进群”,加入交通大数据交流群!希望我们共同进步!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











