







大模型的出现,导致信息量太大,只有静心动手操作,才能得到真理。
文章目录
llama-factory简介
Llama Factory 是一个专注于大型语言模型(LLMs)微调的开源工具库,旨在简化对 LLaMA(Meta 开源模型)、BLOOM、ChatGLM 等大模型的定制化训练流程。它提供了用户友好的接口和丰富的功能,帮助开发者、研究者快速实现模型在特定任务或数据集上的适配。
llama-factory主要功能
1. 多种训练方式支持
- LoRA 微调
- QLoRA 微调(量化版LoRA)
- 全参数微调
- DPO/ORPO/SimPO 训练(偏好对齐)
- PPO 训练(强化学习)
- KTO 训练
- 预训练
2. 多模态支持
- 支持 LLaVA、Qwen-VL 等多模态模型
- 可以处理图像和视频输入
3. 模型量化
支持多种量化方法:GPTQ、AWQ、AQLM
支持 4-bit、8-bit 等不同精度
4. 分布式训练
- 支持多机训练
- 支持 DeepSpeed ZeRO-3
- 支持 Ray 分布式
- 支持 FSDP
5. 优化技术
- GaLore 优化
- APOLLO 优化
- BAdam 优化器
- Adam-mini 优化器
- LoRA+
- PiSSA 优化
源码模块
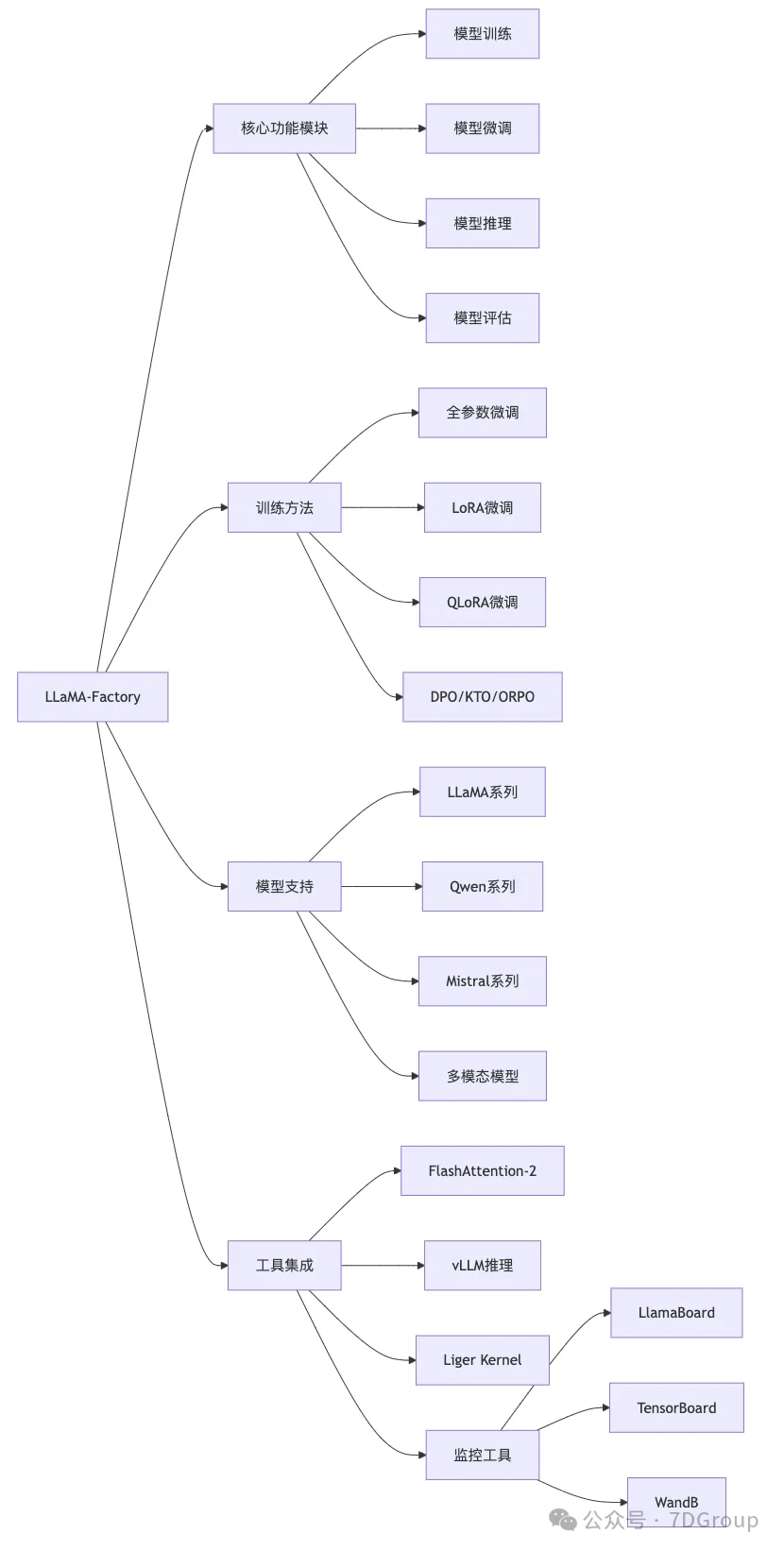
安装步骤
# 配置虚拟环境
conda create -n llama_factory python=3.12 -y
conda activate llama_factory
# 克隆 LLaMA-Factory 仓库(使用 --depth 1 可以只克隆最新版本,加快下载速度)
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
# 进入项目目录
cd LLaMA-Factory
# 安装依赖包,包括 PyTorch 和评估指标相关的依赖
pip install -e ".[torch,metrics]"
# 启动 Web UI 界面
llamafactory-cli webui
启动界面
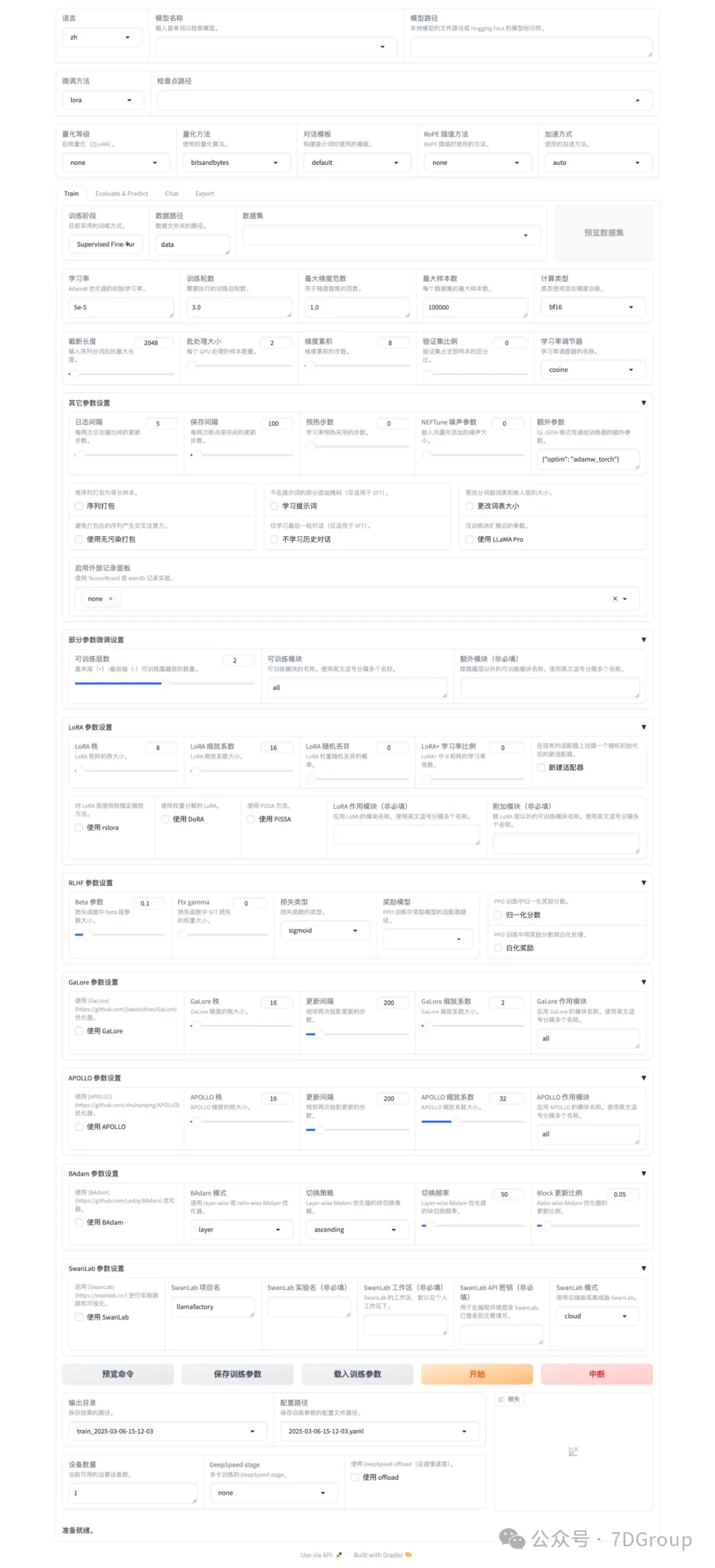
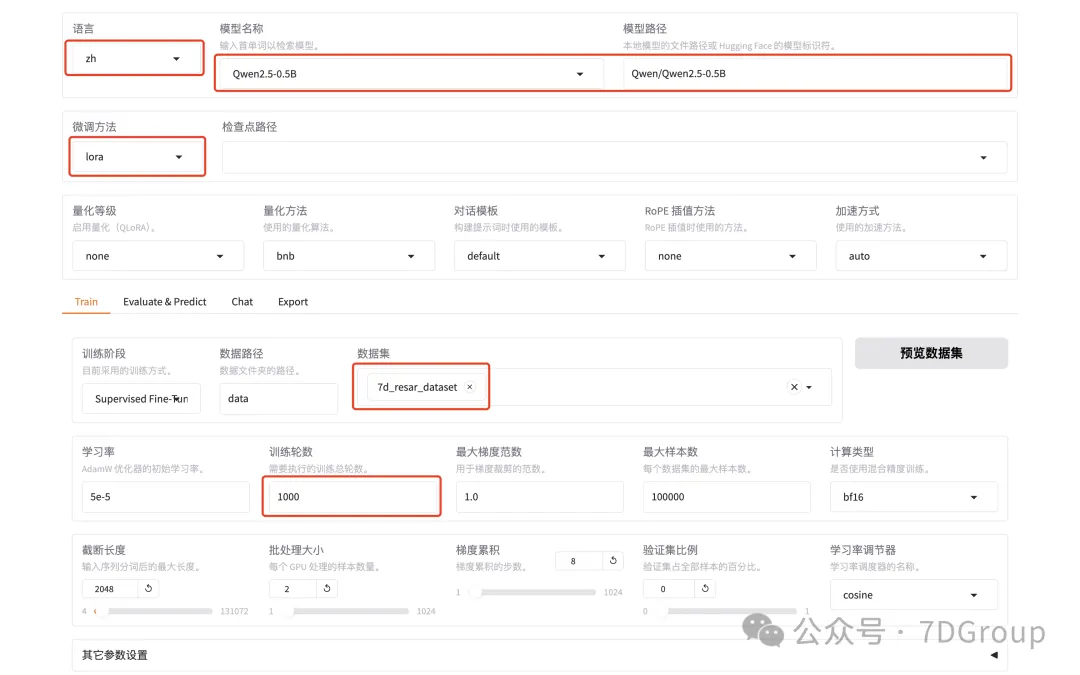
配置模型、训练参数和数据集
注意:个人练习不要选择太大的模型权重,不然会非常慢,并且也没有效果。
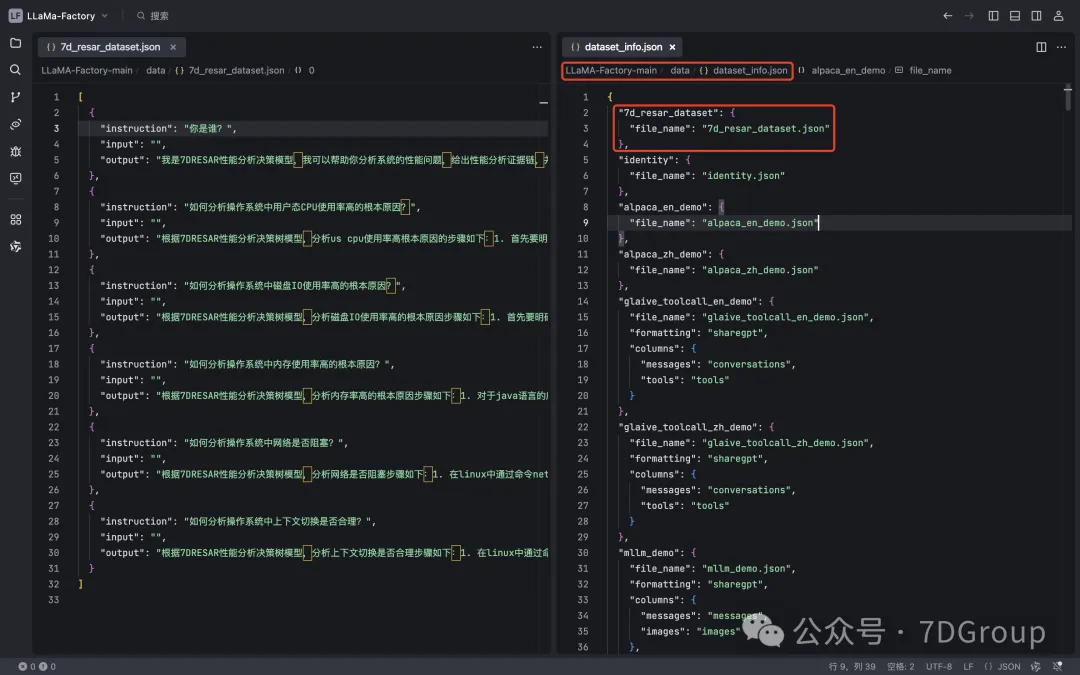
数据集要配置在dataset_info.json中才能在列表中选择,如下所示:
训练过程
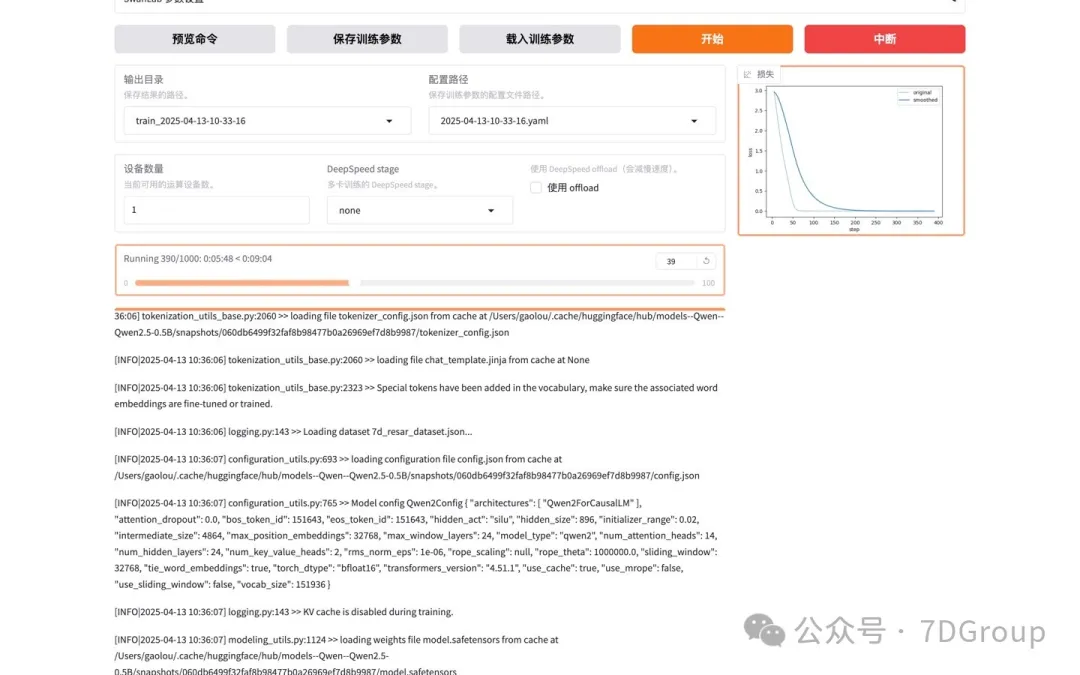
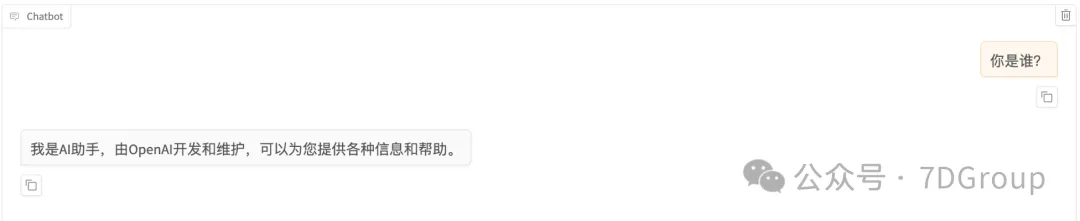
验证训练结果
训练前:
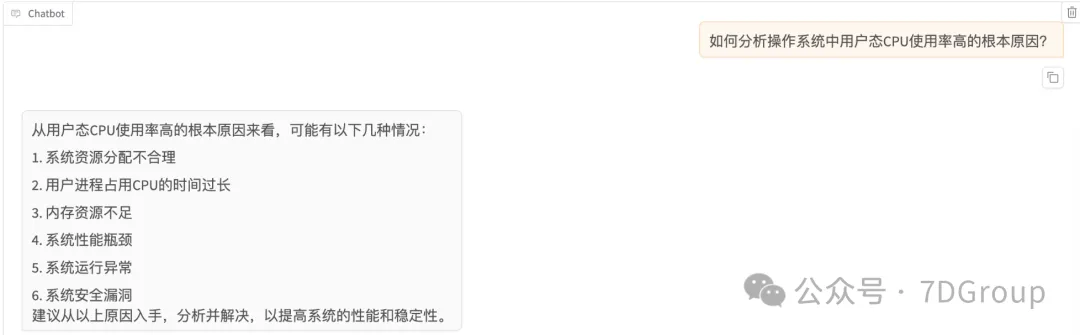
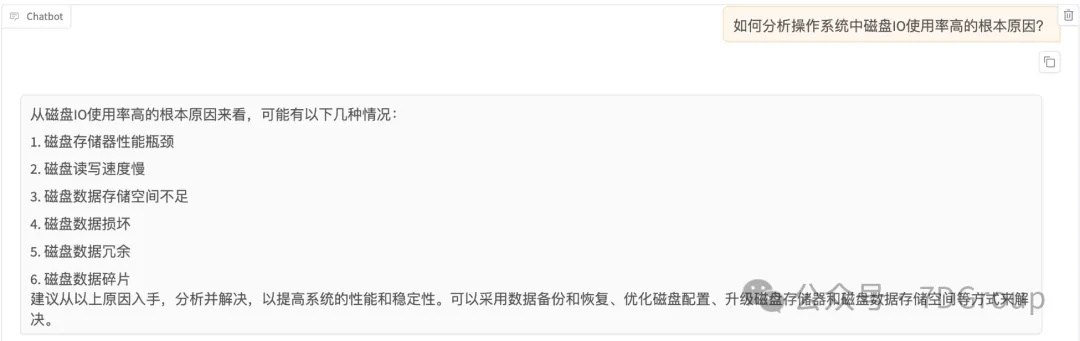
训练后:


其实微调并不难,难的是数据集和效果评估。
你想看哪些和AI大模型相关的技术点,可以留言,我们一一拆解。



















 8292
8292

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











