







XGBoost 参数介绍
XGBoost的参数一共分为三类(完整参数请戳官方文档):
- 通用参数:宏观函数控制。
- Booster参数:控制每一步的booster(tree/regression)。booster参数一般可以调控模型的效果和计算代价。我们所说的调参,很这是大程度上都是在调整booster参数。
- 学习目标参数:控制训练目标的表现。我们对于问题的划分主要体现在学习目标参数上。比如我们要做分类还是回归,做二分类还是多分类,这都是目标参数所提供的。
1.通用参数
booster:我们有两种参数选择,gbtree和gblinear。gbtree是采用树的结构来运行数据,而gblinear是基于线性模型。silent:静默模式,为1时模型运行不输出。nthread: 使用线程数,一般我们设置成-1,使用所有线程。如果有需要,我们设置成多少就是用多少线程。
2.Booster参数
-
n_estimator: 也作num_boosting_rounds这是生成的最大树的数目,也是最大的迭代次数。
-
learning_rate: 有时也叫作eta,系统默认值为0.3,。每一步迭代的步长,很重要。太大了运行准确率不高,太小了运行速度慢。我们一般使用比默认值小一点,
0.1左右就很好。 -
gamma:系统默认为0,我们也常用0。在节点分裂时,只有分裂后损失函数的值下降了,才会分裂这个节点。
gamma指定了节点分裂所需的最小损失函数下降值。 这个参数的值越大,算法越保守。因为gamma值越大的时候,损失函数下降更多才可以分裂节点。所以树生成的时候更不容易分裂节点。范围:[0,∞] -
subsample:系统默认为1。这个参数控制对于每棵树,随机采样的比例。减小这个参数的值,算法会更加保守,避免过拟合。但是,如果这个值设置得过小,它可能会导致欠拟合。 典型值:
0.5-1,0.5代表平均采样,防止过拟合. 范围:(0,1],注意不可取0 -
colsample_bytree:系统默认值为1。我们一般设置成0.8左右。用来控制每棵随机采样的列数的占比(每一列是一个特征)。 典型值:
0.5-1范围:(0,1] -
colsample_bylevel:默认为1,我们也设置为1.这个就相比于前一个更加细致了,它指的是每棵树每次节点分裂的时候列采样的比例
-
max_depth: 系统默认值为6我们常用
3-10之间的数字。这个值为树的最大深度。这个值是用来控制过拟合的。max_depth越大,模型学习的更加具体。设置为0代表没有限制,范围:[0,∞] -
max_delta_step:默认0,我们常用0.这个参数限制了每棵树权重改变的最大步长,如果这个参数的值为
0,则意味着没有约束。如果他被赋予了某一个正值,则是这个算法更加保守。通常,这个参数我们不需要设置,但是当个类别的样本极不平衡的时候,这个参数对逻辑回归优化器是很有帮助的。 -
lambda:也称reg_lambda,默认值为0。权重的L2正则化项。(和Ridge regression类似)。这个参数是用来控制XGBoost的正则化部分的。这个参数在减少过拟合上很有帮助。
-
alpha:也称reg_alpha默认为0,
权重的L1正则化项。(和Lasso regression类似)。 可以应用在很高维度的情况下,使得算法的速度更快。 -
scale_pos_weight:默认为1
在各类别样本十分不平衡时,把这个参数设定为一个正值,可以使算法更快收敛。通常可以将其设置为负样本的数目与正样本数目的比值。
3.学习目标参数
objective [缺省值=reg:linear]
reg:linear– 线性回归reg:logistic– 逻辑回归binary:logistic– 二分类逻辑回归,输出为概率binary:logitraw– 二分类逻辑回归,输出的结果为wTxcount:poisson– 计数问题的poisson回归,输出结果为poisson分布。在poisson回归中,max_delta_step的缺省值为0.7 (used to safeguard optimization)multi:softmax– 设置 XGBoost 使用softmax目标函数做多分类,需要设置参数num_class(类别个数)multi:softprob– 如同softmax,但是输出结果为ndata*nclass的向量,其中的值是每个数据分为每个类的概率。
eval_metric [缺省值=通过目标函数选择]
rmse: 均方根误差mae: 平均绝对值误差logloss: negative log-likelihooderror: 二分类错误率。其值通过错误分类数目与全部分类数目比值得到。对于预测,预测值大于0.5被认为是正类,其它归为负类。 error@t: 不同的划分阈值可以通过 ‘t’进行设置merror: 多分类错误率,计算公式为(wrong cases)/(all cases)mlogloss: 多分类log损失auc: 曲线下的面积ndcg: Normalized Discounted Cumulative Gainmap: 平均正确率
一般来说,我们都会使用xgboost.train(params, dtrain)函数来训练我们的模型。这里的params指的是booster参数。
LightGBM 参数介绍
XGBoost 一共有三类参数通用参数,学习目标参数,Booster参数,那么对于LightGBM,我们有核心参数,学习控制参数,IO参数,目标参数,度量参数,网络参数,GPU参数,模型参数,这里我常修改的便是核心参数,学习控制参数,度量参数等。更详细的请看LightGBM中文文档
1.核心参数
-
boosting:也称boost,boosting_type.默认是gbdt。LGB里面的boosting参数要比xgb多不少,我们有传统的
gbdt,也有rf,dart,doss,最后两种不太深入理解,但是试过,还是gbdt的效果比较经典稳定gbdt, 传统的梯度提升决策树rf, Random Forest (随机森林)dart, Dropouts meet Multiple Additive Regression Treesgoss, Gradient-based One-Side Sampling (基于梯度的单侧采样)
-
num_thread:也称作num_thread,nthread.指定线程的个数。这里官方文档提到,数字设置成cpu内核数比线程数训练效更快(考虑到现在cpu大多超线程)。并行学习不应该设置成全部线程,这反而使得训练速度不佳。
-
application:默认为regression。,也称objective,app这里指的是任务目标- regression
regression_l2, L2 loss, alias=regression, mean_squared_error, mseregression_l1, L1 loss, alias=mean_absolute_error, maehuber, Huber lossfair, Fair losspoisson, Poisson regressionquantile, Quantile regressionquantile_l2, 类似于 quantile, 但是使用了 L2 loss
- binary, binary log loss classification application
- multi-class classification
multiclass, softmax 目标函数, 应该设置好num_classmulticlassova, One-vs-All 二分类目标函数, 应该设置好num_class
- cross-entropy application
xentropy, 目标函数为 cross-entropy (同时有可选择的线性权重), alias=cross_entropyxentlambda, 替代参数化的 cross-entropy, alias=cross_entropy_lambda- 标签是 [0, 1] 间隔内的任意值
- lambdarank, lambdarank application
- 在 lambdarank 任务中标签应该为 int type, 数值越大代表相关性越高 (e.g. 0:bad, 1:fair, 2:good, 3:perfect)
label_gain可以被用来设置 int 标签的增益 (权重)
- regression
-
valid:验证集选用,也称test,valid_data,test_data.支持多验证集,以,分割 -
learning_rate:也称shrinkage_rate,梯度下降的步长。默认设置成0.1,我们一般设置成0.05-0.2之间 -
num_leaves:也称num_leaf,新版lgb将这个默认值改成31,这代表的是一棵树上的叶子数 -
num_iterations:也称num_iteration,num_tree,num_trees,num_round,num_rounds,num_boost_round。迭代次数 -
device:default=cpu, options=cpu, gpu- 为树学习选择设备, 你可以使用 GPU 来获得更快的学习速度
- Note: 建议使用较小的 max_bin (e.g. 63) 来获得更快的速度
- Note: 为了加快学习速度, GPU 默认使用32位浮点数来求和. 你可以设置 gpu_use_dp=true 来启用64位浮点数, 但是它会使训练速度降低
- Note: 请参考 安装指南 来构建 GPU 版本
2.学习控制参数
max_depth
- default=
-1, type=int限制树模型的最大深度. 这可以在#data小的情况下防止过拟合. 树仍然可以通过 leaf-wise 生长. < 0意味着没有限制.
-
feature_fraction:default=1.0, type=double, 0.0 < feature_fraction < 1.0, 也称sub_feature,colsample_bytree- 如果 feature_fraction 小于 1.0, LightGBM 将会在每次迭代中随机选择部分特征. 例如, 如果设置为 0.8, 将会在每棵树训练之前选择 80% 的特征
- 可以用来加速训练
- 可以用来处理过拟合
-
bagging_fraction:default=1.0, type=double, 0.0 < bagging_fraction < 1.0, 也称sub_row,subsample- 类似于 feature_fraction, 但是它将在不进行重采样的情况下随机选择部分数据
- 可以用来加速训练
- 可以用来处理过拟合
- Note: 为了启用 bagging, bagging_freq 应该设置为非零值
-
bagging_freq: default=0, type=int, 也称subsample_freq- bagging 的频率, 0 意味着禁用 bagging. k 意味着每 k 次迭代执行bagging
- Note: 为了启用 bagging, bagging_fraction 设置适当
-
lambda_l1:默认为0,也称reg_alpha,表示的是L1正则化,double类型 -
lambda_l2:默认为0,也称reg_lambda,表示的是L2正则化,double类型 -
cat_smooth: default=10, type=double- 用于分类特征
- 这可以降低噪声在分类特征中的影响, 尤其是对数据很少的类别
-
min_data_in_leaf, 默认为20。 也称min_data_per_leaf,min_data,min_child_samples。
一个叶子上数据的最小数量。可以用来处理过拟合。 -
min_sum_hessian_in_leaf, default=1e-3, 也称min_sum_hessian_per_leaf,min_sum_hessian,min_hessian,min_child_weight。- 一个叶子上的最小 hessian 和. 类似于
min_data_in_leaf, 可以用来处理过拟合. - 子节点所需的样本权重和(hessian)的最小阈值,若是基学习器切分后得到的叶节点中样本权重和低于该阈值则不会进一步切分,在线性模型中该值就对应每个节点的最小样本数,该值越大模型的学习约保守,同样用于防止模型过拟合
- 一个叶子上的最小 hessian 和. 类似于
-
early_stopping_round, 默认为0, type=int, 也称early_stopping_rounds,early_stopping。
如果一个验证集的度量在early_stopping_round循环中没有提升, 将停止训练、 -
min_split_gain, 默认为0, type=double, 也称min_gain_to_split`。执行切分的最小增益。 -
max_bin:最大直方图数目,默认为255,工具箱的最大数特征值决定了容量 工具箱的最小数特征值可能会降低训练的准确性, 但是可能会增加一些一般的影响(处理过拟合,越大越容易过拟合)。- 针对直方图算法tree_method=hist时,用来控制将连续值特征离散化为多个直方图的直方图数目。
- LightGBM 将根据
max_bin自动压缩内存。 例如, 如果 maxbin=255, 那么 LightGBM 将使用 uint8t 的特性值。
12.subsample_for_binbin_construct_sample_cnt, 默认为200000, 也称subsample_for_bin。用来构建直方图的数据的数量。
3.度量函数
metric: default={l2 for regression}, {binary_logloss for binary classification}, {ndcg for lambdarank}, type=multi-enum, options=l1, l2, ndcg, auc, binary_logloss, binary_error …l1, absolute loss, alias=mean_absolute_error, mael2, square loss, alias=mean_squared_error, msel2_root, root square loss, alias=root_mean_squared_error, rmsequantile, Quantile regressionhuber, Huber lossfair, Fair losspoisson, Poisson regressionndcg, NDCGmap, MAPauc, AUCbinary_logloss, log lossbinary_error, 样本: 0 的正确分类, 1 错误分类multi_logloss, mulit-class 损失日志分类multi_error, error rate for mulit-class 出错率分类xentropy, cross-entropy (与可选的线性权重), alias=cross_entropyxentlambda, “intensity-weighted” 交叉熵, alias=cross_entropy_lambdakldiv, Kullback-Leibler divergence, alias=kullback_leibler- 支持多指标, 使用 , 分隔
4. IO参数
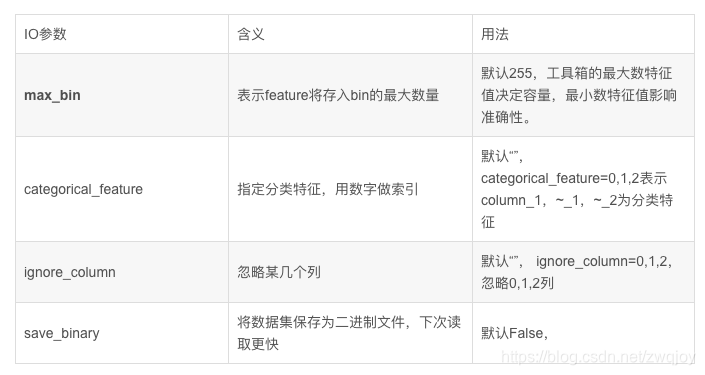
总的来说,我还是觉得LightGBM比XGBoost用法上差距不大。参数也有很多重叠的地方。很多XGBoost的核心原理放在LightGBM上同样适用。 同样的,Lgb也是有train()函数和LGBClassifier()与LGBRegressor()函数。后两个主要是为了更加贴合sklearn的用法,这一点和XGBoost一样。
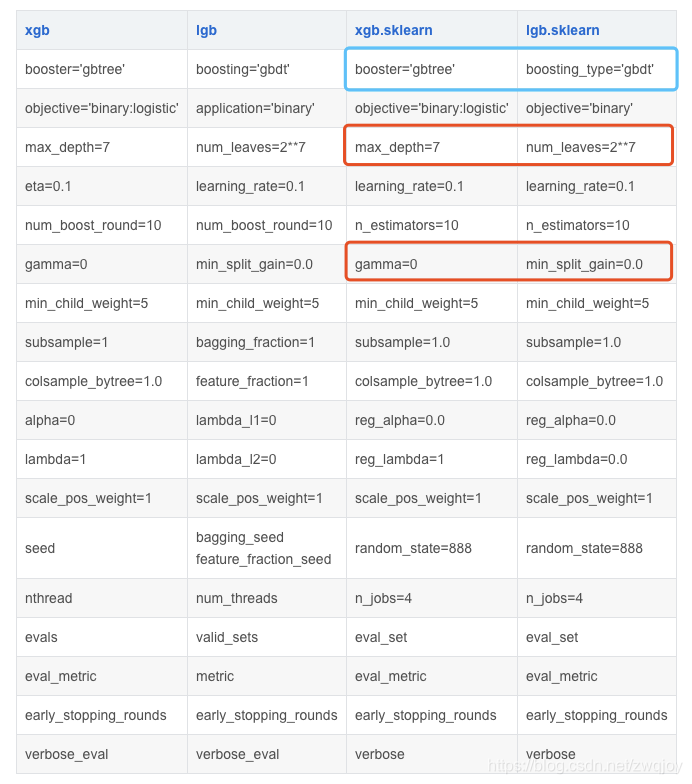
两者参数对比

1. 使用num_leaves
因为LightGBM使用的是leaf-wise的算法,因此在调节树的复杂程度时,使用的是num_leaves而不是max_depth。
大致换算关系:num_leaves = 2^(max_depth)。它的值的设置应该小于2^(max_depth),否则可能会导致过拟合。
2.对于非平衡数据集:可以param['is_unbalance']='true’
3. Bagging参数:bagging_fraction+bagging_freq(必须同时设置)、feature_fraction。bagging_fraction可以使bagging的更快的运行出结果,feature_fraction设置在每次迭代中使用特征的比例。
4. min_data_in_leaf:这也是一个比较重要的参数,调大它的值可以防止过拟合,它的值通常设置的比较大。
5.max_bin:调小max_bin的值可以提高模型训练速度,调大它的值和调大num_leaves起到的效果类似。
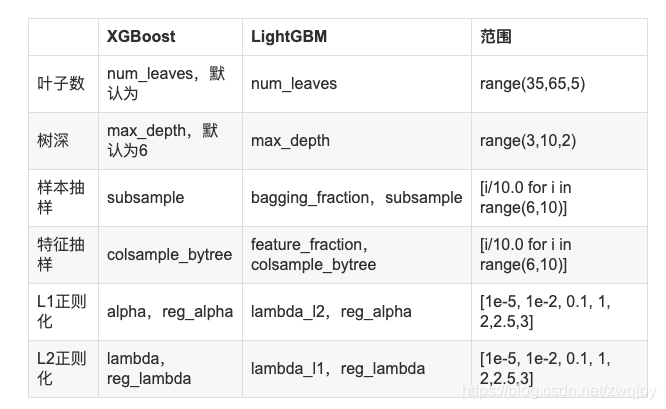
调参核心
- 调参1:提高准确率":num_leaves, max_depth, learning_rate
- 调参2:降低过拟合 max_bin min_data_in_leaf
- 调参3:降低过拟合 正则化L1, L2
- 调参4:降低过拟合 数据抽样 列抽样
调参方向:处理过拟合(过拟合和准确率往往相反)
- 使用较小的
max_bin - 使用较小的
num_leaves - 使用
min_data_in_leaf和min_sum_hessian_in_leaf - 通过设置
bagging_fraction和bagging_freq来使用 bagging - 通过设置
feature_fraction<1来使用特征抽样 - 使用更大的训练数据
- 使用
lambda_l1,lambda_l2和min_gain_to_split来使用正则 - 尝试
max_depth来避免生成过深的树
imbalanced数据集的参数
lightGBM和XGBoost都提供了 scale_pos_weight 参数来处理正样本和负样本的不平衡问题。
1. lightGBM通过增加正样本标签的权重,即label_weights_[1] *= scale_pos_weight_ 来处理样本不平衡的问题
一个简单的方法是设置is_unbalance参数为True或者设置scale_pos_weight, 二者只能选一个。
设置is_unbalance参数为True时会把负样本的权重设为:正样本数/负样本数。这个参数只能用于二分类。
void Init(const Metadata& metadata, data_size_t num_data) override {
num_data_ = num_data;
label_ = metadata.label();
weights_ = metadata.weights();
data_size_t cnt_positive = 0;
data_size_t cnt_negative = 0;
// count for positive and negative samples
#pragma omp parallel for schedule(static) reduction(+:cnt_positive, cnt_negative)
for (data_size_t i = 0; i < num_data_; ++i) {
if (is_pos_(label_[i])) {
++cnt_positive;
} else {
++cnt_negative;
}
}
if (cnt_negative == 0 || cnt_positive == 0) {
Log::Warning("Contains only one class");
// not need to boost.
num_data_ = 0;
}
Log::Info("Number of positive: %d, number of negative: %d", cnt_positive, cnt_negative);
// use -1 for negative class, and 1 for positive class
label_val_[0] = -1;
label_val_[1] = 1;
// weight for label
label_weights_[0] = 1.0f;
label_weights_[1] = 1.0f;
// if using unbalance, change the labels weight
if (is_unbalance_ && cnt_positive > 0 && cnt_negative > 0) {
if (cnt_positive > cnt_negative) {
label_weights_[1] = 1.0f;
label_weights_[0] = static_cast<double>(cnt_positive) / cnt_negative;
} else {
label_weights_[1] = static_cast<double>(cnt_negative) / cnt_positive;
label_weights_[0] = 1.0f;
}
}
label_weights_[1] *= scale_pos_weight_;
}
2. XGBoost 使用增大CART树叶子的分数w,即w += y * ((param_.scale_pos_weight * w) - w);;来处理样本不平衡的问题。
#pragma omp parallel for schedule(static)
for (omp_ulong i = 0; i < n - remainder; i += 8) {
avx::Float8 y(&info.labels_[i]);
avx::Float8 p = Loss::PredTransform(avx::Float8(&preds_h[i]));
avx::Float8 w = info.weights_.empty() ? avx::Float8(1.0f)
: avx::Float8(&info.weights_[i]);
// Adjust weight
w += y * (scale * w - w);
avx::Float8 grad = Loss::FirstOrderGradient(p, y);
avx::Float8 hess = Loss::SecondOrderGradient(p, y);
avx::StoreGpair(gpair_ptr + i, grad * w, hess * w);
}
for (omp_ulong i = n - remainder; i < n; ++i) {
auto y = info.labels_[i];
bst_float p = Loss::PredTransform(preds_h[i]);
bst_float w = info.GetWeight(i);
w += y * ((param_.scale_pos_weight * w) - w);
gpair[i] = GradientPair(Loss::FirstOrderGradient(p, y) * w,
Loss::SecondOrderGradient(p, y) * w);
}
}scale_pos_weight 是用来调节正负样本不均衡问题的,用助于样本不平衡时训练的收敛。 如何你仅仅关注预测问题的排序或者AUC指标,那么你尽管可以调节此参数。用 scale_pos_weights 调节后预测的结果所表示概率确实已经没有参考意义了

















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









