







 这篇博客介绍了随机森林算法,包括它与集成学习和决策树的关系,随机性的体现,如样本的有放回抽样和特征随机抽样,以及如何处理缺失值。博主分享了用Python实现随机森林的基本思想,并指出了一些待完善的功能,如回归分析、特征重要性估计、样本权重不平衡和概率输出等。
这篇博客介绍了随机森林算法,包括它与集成学习和决策树的关系,随机性的体现,如样本的有放回抽样和特征随机抽样,以及如何处理缺失值。博主分享了用Python实现随机森林的基本思想,并指出了一些待完善的功能,如回归分析、特征重要性估计、样本权重不平衡和概率输出等。
第一次写博客,水平有限,恳请指正交流.
接触机器学习也有一段时间了,以前只是看看理论,调调sklearn的包,感觉并没有真正的明白算法的具体细节。
现在开始利用空闲时间,把自己学过的算法用python实现一下,代码学习时间很短,所以代码结构不是很好,也没优化,以后我会努力写出优秀的代码的。
一 前言:随机森林(Random Forests)真正被系统性的提出是 BREIMAN 2001年的论文。
1 随机森林与集成学习的关系:
说到随机森林,就不得不提一下机器学习中的集成学习方法。这里参考周志华老师的西瓜书简单总结一下集成学习。
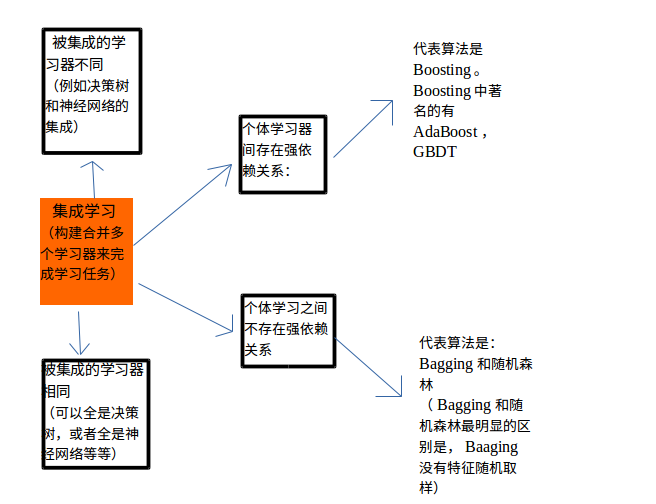
2.随机森林与决策树的关系
二.随机森林特点:
1.随机性:随机体现在两个方面,生成单颗决策树时,需要进行样本的有放回抽样(自助采样法),
在生成单颗决策树时,每个结点处,进行特征的随机抽样。
2.out-of-bag估计:每颗决策树的生成都需要自助采样,这时就会有1/3的数据未被选中,这部分数据称为袋外数据。
可以根据这部分数据进行 森林泛化误差(BREIMAN论文中介绍说袋外估计的泛化误差近似==测试集大小和训练集大小相同时的测试误差)特征重要性的估计。在代码中实现了泛化误差的估计,特征重要性有时间再补上。
(特征重要性的估计通常有两种方法:一是使用uniform或者gaussian抽取随机值替换原特征;一是通过permutation的方式将原来的所有N个样本的第i个特征值重新打乱分布。,第二种方法更加科学,保证了特征替代值与原特征的分布是近似的。这种方法叫做permutation test,即在计算第i个特征的重要性的时候,将N个样本的第i个特征重新洗牌,然后比较D和 D(p) 表现的差异性。如果差异很大,则表明第i个特征是重要的。)
3.随机森林未用到决策树的剪枝,那怎样控制模型的过拟合呢?主要通过控制 树的深度(max_depth),结点停止分裂的最小样本数(min_size)等参数。
4.缺失值处理:缺失值可以分为出现在训练集中,出现在测试集中两种情况。(本文代码只实现了测试集中缺失值的自动处理)
决策树(C4.5,CART等)具有缺失值自动处理能力。西瓜书中介绍了C4.5的缺失值处理原理。我对随机森林中的缺失值处理机制没有深究(个人理解:缺失值的处理需要针对不同的数据集和测试结果进行相应调整)。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 527
527

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









