






GroupByKey和ReduceByKey两者都是spark中的Transformation算子,尽管二者通过操作可以实现相同的效果,但是二者有着很大的区别。
在shuffle操作上,ReduceByKey会在shuffle之前发生提前聚合,这样会大量的减少落盘的数据量,提高性能与效率,在开发中也是更偏向于使用ReduceByKey.然而GroupByKey不会在分区内提前聚合,只会在发生shuffle的时候进行分组聚合,并且还要搭配mapValues()使用,将需要的操作转到mapValues()里。
例:
Examples:使用reduceByKey统计数值
reduceByKey: 将数据按照value值累加(不是计数)
key2 = rdd3.reduceByKey(lambda x,y:x+y)
print(key2.collect())
[('b', 6), ('c', 3), ('a', 1)]
Examples:使用groupByKey+mapValues()统计词频个数
groupByKey: groupByKey搭配mapValues()使用:
>>> rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
>>> sorted(rdd.groupByKey().mapValues(len).collect())
[('a', 2), ('b', 1)]
>>> sorted(rdd.groupByKey().mapValues(list).collect())
[('a', [1, 1]), ('b', [1])]
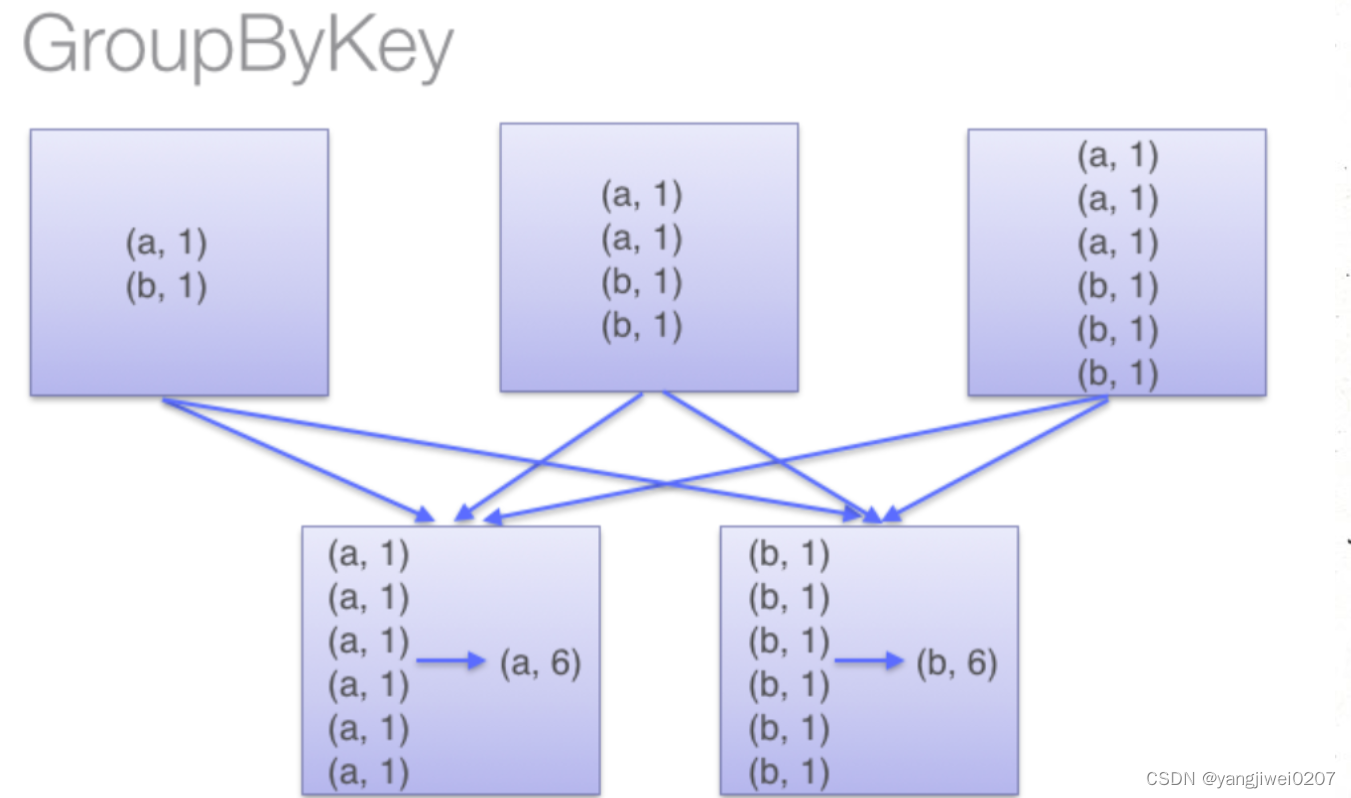
GroupBy:
ReduceBy:
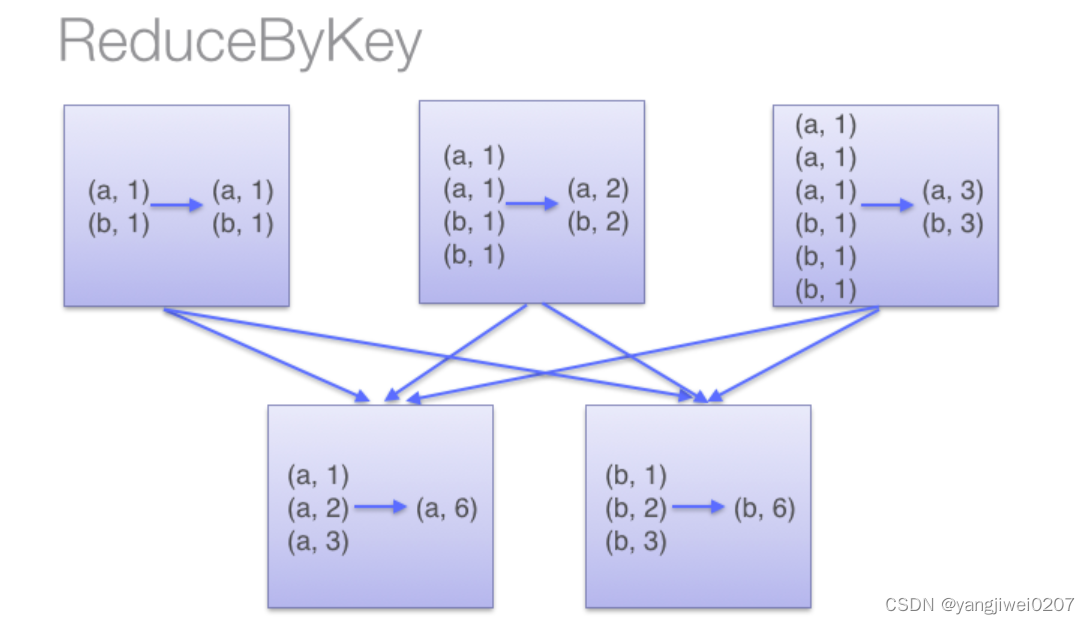
通过两张图片可知,两者的最主要的区别是否提前聚合,因为reduceByKey会提前聚合减少落盘的数据量,因此可以减少数据压力,可以使性能调优。
















 315
315











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











