









文章目录
0. 前言
一方面,大量研究表明,多分支网络架构的性能普遍优于单分支架构;另一方面,相比多分支架构,单分支架构更有利于部署。那么有没有可能训练时采用多分支架构,而推理时使用单分支呢?我只想说,Re-parameterization is All You Need !!!
1. Re-parameterization Universe
1.1 RepVGG
为什么要使用VGG式单分支架构:
-
快:并行度高,单分支架构中的运算是大而整的,而多分支是小而碎的,同样的计算量,“大而整”的运算效率远超“小而碎”
-
省内存:在add或concat之前,每个分支都占用一份内存来缓存运算结果,add或concat后才能释放

-
硬件友好:VGG式网络架构只有3×3卷积这一种算子,无需额外设计
结构重参数化的核心思想:卷积运算是线性运算,具有可加性。
为了实现结构重参数化,需要特殊设计一种多分支模块,其内部只有线性运算,例如卷积和BN,激活函数需要放到多分支模块外面,如下图所示:

那么如何将多分支转换为单分支呢?下图解释的很清楚,如果能看懂就可以跳过后面的解释。

转换过程可以分为3个步骤:
-
将1×1卷积和identity转换为3×3卷积:
1×1卷积通过pad可以直接转换为3×3卷积,这里着重解释一下identity如何转换为3×3卷积。identity的作用是保持输出与输入一致,当输入和输出的通道数均为2时,假设输入分别为 x 1 x_1 x1和 x 2 x_2 x2,输出分别为 y 1 y_1 y1和 y 2 y_2 y2,在不考虑bias的情况下,有:
x 1 = y 1 = w 1 1 ∗ x 1 + w 1 2 ∗ x 2 x_1=y_1 = w_1^1*x_1+w_1^2*x_2 x1=y1=w11∗x1+w12∗x2 x 2 = y 2 = w 2 1 ∗ x 1 + w 2 2 ∗ x 2 x_2=y_2 = w_2^1*x_1+w_2^2*x_2 x2=y2=w21∗x1+w22∗x2显然,为了使上式成立, w 1 1 w_1^1 w11是一个权重为1的1×1卷积, w 1 2 w_1^2 w12是一个权重为0的1×1卷积; w 2 1 w_2^1 w21是一个权重为0的1×1卷积, w 2 2 w_2^2 w22是一个权重为1的1×1卷积。通过填充0就可以转换为3×3卷积,论文中也给出了对应的示意图:

依此类推,若输入和输出通道为 C C C,则identity可以表示为下图,其实就是单位矩阵中的每个元素扩展为3×3卷积,文中所提到的单位矩阵就是这个意思。

-
对于每个分支,融合3×3卷积和BN:
由于每个分支都有个BN层,所以需要将卷积和BN进行融合,也是算子折叠中的常规操作,原理如下:
卷积可以表示为: C o n v ( x ) = W ( x ) + b Conv(x)=W(x)+b Conv(x)=W(x)+bBN可以表示为: B N ( x ) = γ ∗ x − μ σ 2 + ϵ + β BN(x)=\gamma*\frac{x-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta BN(x)=γ∗σ2+ϵx−μ+β将卷积代入BN中,则有: C o n v B N ( x ) = γ ∗ W ( x ) + b − μ σ 2 + ϵ + β = γ ∗ W ( x ) σ 2 + ϵ + γ ∗ ( b − μ ) σ 2 + ϵ + β ConvBN(x)=\gamma*\frac{W(x)+b-\mu}{\sqrt{\sigma^2+\epsilon}}+\beta=\frac{\gamma*W(x)}{\sqrt{\sigma^2+\epsilon}}+\frac{\gamma*(b-\mu)}{\sqrt{\sigma^2+\epsilon}}+\beta ConvBN(x)=γ∗σ2+ϵW(x)+b−μ+β=σ2+ϵγ∗W(x)+σ2+ϵγ∗(b−μ)+β
conv后接BN时,bias通常设置为False,因此,上式可简化为以下形式:
C o n v B N ( x ) = γ ∗ W ( x ) σ 2 + ϵ + ( β − γ ∗ μ σ 2 + ϵ ) ConvBN(x)=\frac{\gamma*W(x)}{\sqrt{\sigma^2+\epsilon}}+(\beta-\frac{\gamma*\mu}{\sqrt{\sigma^2+\epsilon}}) ConvBN(x)=σ2+ϵγ∗W(x)+(β−σ2+ϵγ∗μ)
官方代码如下:
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, nn.Sequential):
# 取出卷积层的权重
kernel = branch.conv.weight
# 取出BN层的参数
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
# 将Identity分支转换为3*3卷积
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = np.zeros((self.in_channels, input_dim, 3, 3), dtype=np.float32)
for i in range(self.in_channels):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
# 获取卷积权重
kernel = self.id_tensor
# 获取BN层的参数
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
# 计算融合卷积和BN后的weight和bias
return kernel * t, beta - running_mean * gamma / std
- 融合多分支的weight和bias:
因为每个分支内执行的都是线性运算,因此融合时直接线性求和即可:
y
=
(
W
1
x
+
b
1
)
+
(
W
2
x
+
b
2
)
+
(
W
3
x
+
b
3
)
=
(
W
1
+
W
2
+
W
3
)
x
+
(
b
1
+
b
2
+
b
3
)
y=(W_1x+b_1)+(W_2x+b_2)+(W_3x+b_3)=(W_1+W_2+W_3)x+(b_1+b_2+b_3)
y=(W1x+b1)+(W2x+b2)+(W3x+b3)=(W1+W2+W3)x+(b1+b2+b3)官方代码如下:
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.rbr_dense)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.rbr_1x1)
kernelid, biasid = self._fuse_bn_tensor(self.rbr_identity)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
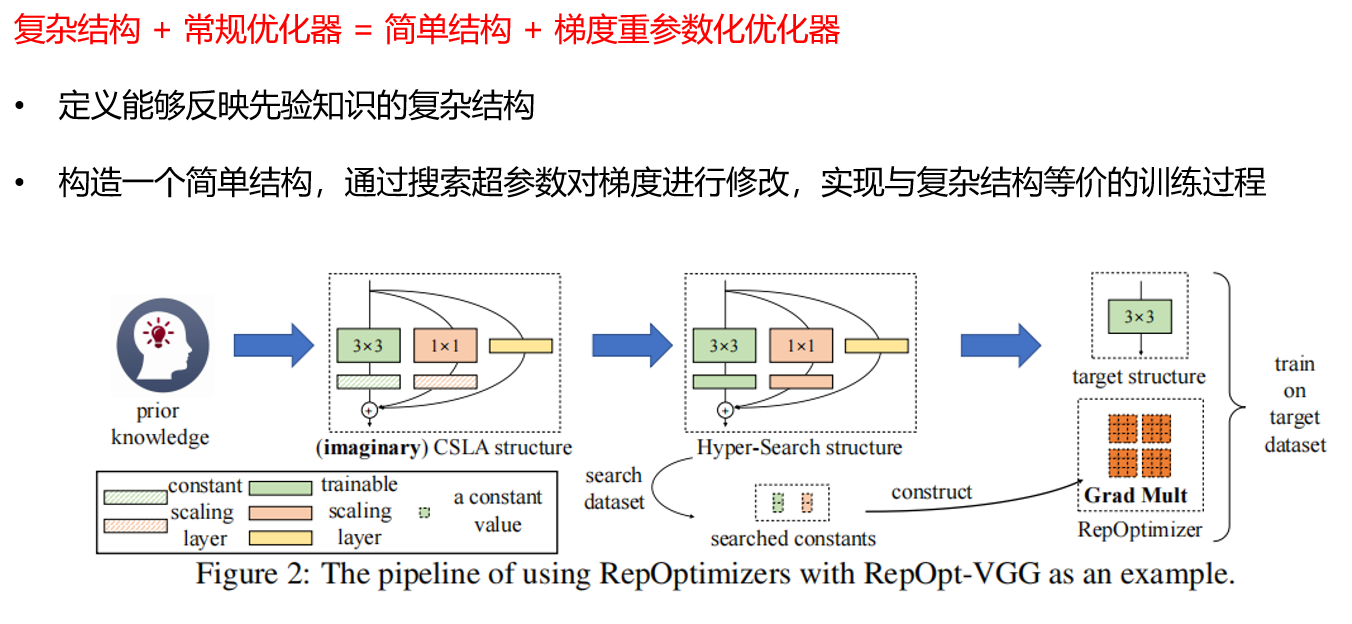
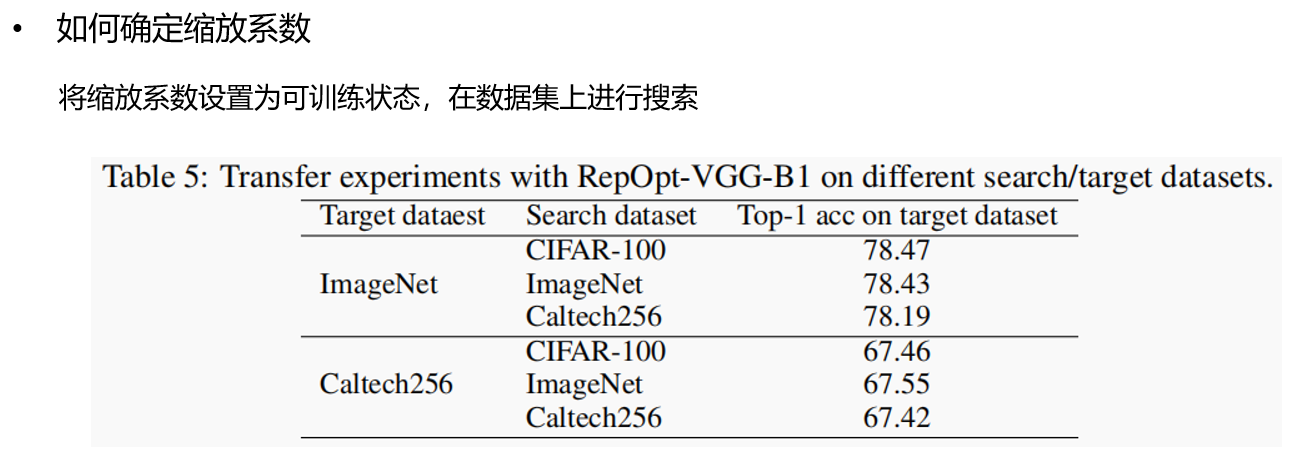
1.2. RepOptimizer




1.3 Diverse Branch Block(DBB)

2. 应用
2.1 差分卷积

2.2 MobileOne
训练时增加额外的分支数(图中的k Blocks),推理时重参数化为单分支结构,既有多分支的性能,又有单分支的推理速度。

2.3 VanillaNet
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









