






结构重参数化详解。(bn+conv)与(conv+bn)的融合
原理
如何理解结构重参数化?即 把结构 参数化 ,在训练的时候使用一种复杂的结构,在训练结束后,将多个结构的权重合并,从而在推理时采用另外一种更简单结构加载权重,达到减少计算量与参数量的目的。
比如下面的这个图,如果conv1和conv2的stride一致,那么conv1和conv2可以合并为一个卷积操作。
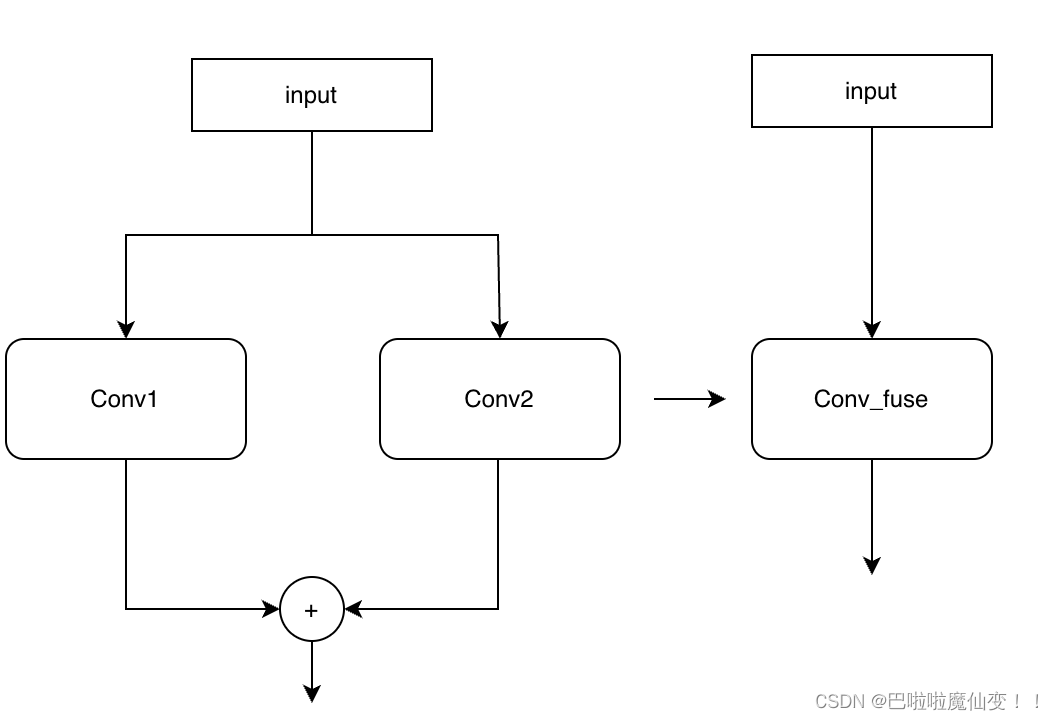
如何合并呢?将conv1的权重和conv2的权重相加即可合并为一个卷积层,如果kernel大小不一致,在小的kernel周围填充一圈圈的0,直到大小一致,即可完成合并。这里需要注意在推理阶段需要使用大小不一致的padding以确保生成的特征图一致,否则无法相加。这也是stride不一致的情况下无法合并的原因。而在推理阶段,已经确保将kernel大小一致,那么padding也一致
在公式上可表达为:
y
=
(
W
1
×
x
+
B
1
)
+
(
W
2
×
x
+
B
2
)
y
=
(
W
fuse
×
x
+
B
fuse
)
W
fuse
=
W
1
+
W
2
B
fuse
=
B
1
+
B
2
y = (W_1 \times x + B_1) + (W_2 \times x + B_2) \\ y = (W_{\text{fuse}} \times x + B_{\text{fuse}}) \\ W_{\text{fuse}} = W_1 + W_2 \\ B_{\text{fuse}} = B_1 + B_2
y=(W1×x+B1)+(W2×x+B2)y=(Wfuse×x+Bfuse)Wfuse=W1+W2Bfuse=B1+B2
融合后的结构:
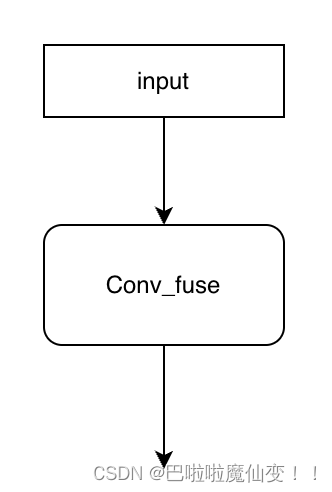
那么这就是结构重参数化原理,结构重参数化不仅可以合并水平方向上的分支,也可以合并垂直方向上的操作。残差结构可以被视为卷积核大小为1,并且值为1的卷积操作,那么同样也可以被合并
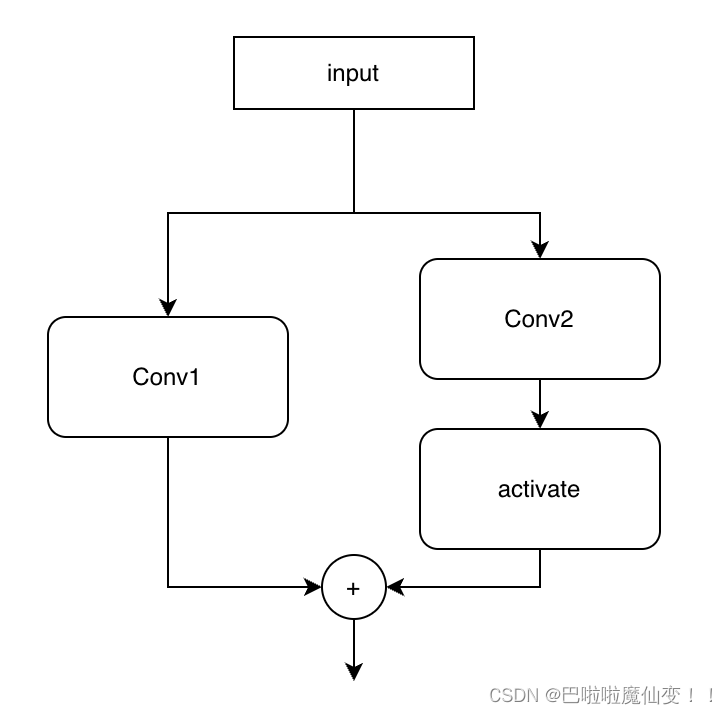
哪种情况不能合并?
问题来了,有哪些操作不能合并?上面能合并的操作中均不包括激活函数,如果经过激活函数,那么y的计算公式由
y
=
(
W
1
×
x
+
B
1
)
+
(
W
2
×
x
+
B
2
)
y = (W_1 \times x + B_1) + (W_2 \times x + B_2)
y=(W1×x+B1)+(W2×x+B2)
变为了
y
=
(
W
1
×
x
+
B
1
)
+
activate
(
W
2
×
x
+
B
2
)
y = (W_1 \times x + B_1) + \text{activate}(W_2 \times x + B_2) \\
y=(W1×x+B1)+activate(W2×x+B2)
导致conv2由线性操作变为了非线形操作,就无法合并。如下图
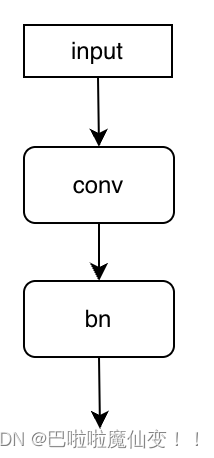
带bn的合并结构
(conv + bn)
先使用卷积层,后使用bn层,如下图。
这个结构在公式上可表达为:
y
=
bn
(
conv
(
x
)
)
y = \text{bn}(\text{conv}(x)) \\
y=bn(conv(x))
复习一下conv和bn的公式,其中mean是平均值,var是方差,eps是避免分母为0,W、B是需要学习的参数。mean、var和eps是不需要学习的
conv
=
W
conv
×
x
+
B
conv
bn
=
W
bn
x
−
mean
var
+
eps
+
B
BN
\text{conv} = W_{\text{conv}} \times x + B_{\text{conv}} \\ \text{bn} = W_{\text{bn}} \frac{x - \text{mean}}{\sqrt{\text{var} + \text{eps}}} + B_{\text{BN}} \\
conv=Wconv×x+Bconvbn=Wbnvar+epsx−mean+BBN
将conv带入到bn的x,可得下式
y
=
W
b
n
×
W
c
o
n
v
v
a
r
+
e
p
s
×
x
+
B
b
n
+
W
b
n
v
a
r
+
e
p
s
×
(
B
c
o
n
v
−
m
e
a
n
)
y = \frac{ W_{bn} \times W_{conv} }{\sqrt{var+eps}}\times x + B_{bn} + \frac{ W_{bn} }{\sqrt{var+eps}} \times (B_{conv} - mean) \\
y=var+epsWbn×Wconv×x+Bbn+var+epsWbn×(Bconv−mean)
那么可以得到,融合后conv的Wfuse和Bfuse
W
f
u
s
e
=
W
b
n
×
W
c
o
n
v
v
a
r
+
e
p
s
B
f
u
s
e
=
B
b
n
+
W
b
n
v
a
r
+
e
p
s
×
(
B
c
o
n
v
−
m
e
a
n
)
W_{fuse} = \frac{ W_{bn} \times W_{conv} }{\sqrt{var+eps}} \\ B_{fuse} = B_{bn} + \frac{ W_{bn} }{\sqrt{var+eps}} \times (B_{conv} - mean)
Wfuse=var+epsWbn×WconvBfuse=Bbn+var+epsWbn×(Bconv−mean)
(bn + conv)
先使用bn层,后使用conv层,如下图:
这个结构在公式上可表达为:
y
=
conv
(
bn
(
x
)
)
y = \text{conv}(\text{bn}(x)) \\
y=conv(bn(x))
依旧贴一下bn和conv的公式
bn
=
W
bn
x
−
mean
var
+
eps
+
B
BN
conv
=
W
conv
×
x
+
B
conv
\text{bn} = W_{\text{bn}} \frac{x - \text{mean}}{\sqrt{\text{var} + \text{eps}}} + B_{\text{BN}} \\ \text{conv} = W_{\text{conv}} \times x + B_{\text{conv}} \\
bn=Wbnvar+epsx−mean+BBNconv=Wconv×x+Bconv
将bn代入conv可得
y
=
W
c
o
n
v
×
(
W
b
n
×
(
x
−
m
e
a
n
v
a
r
+
e
p
s
)
+
B
b
n
)
+
B
c
o
n
v
y
=
W
c
o
n
v
×
W
b
n
v
a
r
+
e
p
s
×
x
+
(
−
W
c
o
n
v
×
W
b
n
v
a
r
+
e
p
s
×
m
e
a
n
+
W
c
o
n
v
×
B
b
n
+
B
c
o
n
v
)
y = W_{conv} \times (W_{bn}\times(\frac{x-mean}{\sqrt{var+eps}})+B_{bn})+B_{conv} \\ y = \frac{W_{conv} \times W_{bn}}{\sqrt{var+eps}}\times x + (- \frac{ W_{conv}\times W_{bn}}{\sqrt{var+eps}}\times mean + W_{conv} \times B_{bn} + B_{conv})
y=Wconv×(Wbn×(var+epsx−mean)+Bbn)+Bconvy=var+epsWconv×Wbn×x+(−var+epsWconv×Wbn×mean+Wconv×Bbn+Bconv)
即融合后conv的Wfuse、Bfuse为:
W
f
u
s
e
=
W
c
o
n
v
×
W
b
n
v
a
r
+
e
p
s
B
f
u
s
e
=
−
W
c
o
n
v
×
W
b
n
v
a
r
+
e
p
s
×
m
e
a
n
+
W
c
o
n
v
×
B
b
n
+
B
c
o
n
v
W_{fuse} = \frac{W_{conv} \times W_{bn}}{\sqrt{var+eps}} \\ B_{fuse} = - \frac{ W_{conv}\times W_{bn}}{\sqrt{var+eps}}\times mean + W_{conv} \times B_{bn} + B_{conv}
Wfuse=var+epsWconv×WbnBfuse=−var+epsWconv×Wbn×mean+Wconv×Bbn+Bconv
需要注意:
- 以上的公式中忽略了W和B的shape,即他们是矩阵,但在公式中仅以符号代表。先使用bn和后使用bn,bn的channels跟着in_channels 和out_channels走,并且先使用bn层的情况下,还需要考虑groups。稍微复杂一点点
- 通常在后面接bn的conv层中,不会添加Bconv
pytorch代码
如正常卷积层一样使用,重点是传入rbr_conv_kernel_list参数。是每个分支结构的卷积核大小。调用reparameterize()会自动合并多分支,结构重参数化后仅有一个conv和激活函数。详情可见https://github.com/balala8/FastViT_pytorch
class RepBlock(nn.Module):
"""
MobileOne-style residual blocks, including residual joins and re-parameterization convolutions
"""
def __init__(
self,
in_channels: int,
out_channels: int,
stride: int = 1,
groups: int = 1,
inference_mode: bool = False,
rbr_conv_kernel_list: List[int] = [7, 3],
use_bn_conv: bool = False,
act_layer: nn.Module = nn.ReLU,
skip_include_bn: bool = True,
) -> None:
"""Construct a Re-parameterization module.
:param in_channels: Number of input channels.
:param out_channels: Number of output channels.
:param stride: Stride for convolution.
:param groups: Number of groups for convolution.
:param inference_mode: Whether to use inference mode.
:param rbr_conv_kernel_list: List of kernel sizes for re-parameterizable convolutions.
:param use_bn_conv: Whether the bn is in front of conv, if false, conv is in front of bn
:param act_layer: Activation layer.
:param skip_include_bn: Whether to include bn in skip connection.
"""
super(RepBlock, self).__init__()
self.inference_mode = inference_mode
self.groups = groups
self.stride = stride
self.in_channels = in_channels
self.out_channels = out_channels
self.rbr_conv_kernel_list = sorted(rbr_conv_kernel_list, reverse=True)
self.num_conv_branches = len(self.rbr_conv_kernel_list)
self.kernel_size = self.rbr_conv_kernel_list[0]
self.use_bn_conv = use_bn_conv
self.skip_include_bn = skip_include_bn
self.activation = act_layer()
if inference_mode:
self.reparam_conv = nn.Conv2d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=self.kernel_size,
stride=stride,
padding=self.kernel_size // 2,
groups=groups,
bias=True,
)
else:
# Re-parameterizable skip connection
if out_channels == in_channels and stride == 1:
if self.skip_include_bn:
# Use residual connections that include BN
self.rbr_skip = nn.BatchNorm2d(num_features=in_channels)
else:
# Use residual connections
self.rbr_skip = nn.Identity()
else:
# Use residual connections
self.rbr_skip = None
# Re-parameterizable conv branches
rbr_conv = list()
for kernel_size in self.rbr_conv_kernel_list:
if self.use_bn_conv:
rbr_conv.append(
self._bn_conv(
in_chans=in_channels,
out_chans=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=kernel_size // 2,
groups=groups,
)
)
else:
rbr_conv.append(
self._conv_bn(
in_chans=in_channels,
out_chans=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=kernel_size // 2,
groups=groups,
)
)
self.rbr_conv = nn.ModuleList(rbr_conv)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""Apply forward pass."""
# Inference mode forward pass.
if self.inference_mode:
return self.activation(self.reparam_conv(x))
# Multi-branched train-time forward pass.
# Skip branch output
identity_out = 0
if self.rbr_skip is not None:
identity_out = self.rbr_skip(x)
# Other branches
out = identity_out
for ix in range(self.num_conv_branches):
out = out + self.rbr_conv[ix](x)
return self.activation(out)
def reparameterize(self):
"""Following works like `RepVGG: Making VGG-style ConvNets Great Again` -
https://arxiv.org/pdf/2101.03697.pdf. We re-parameterize multi-branched
architecture used at training time to obtain a plain CNN-like structure
for inference.
"""
if self.inference_mode:
return
kernel, bias = self._get_kernel_bias()
self.reparam_conv = nn.Conv2d(
in_channels=self.rbr_conv[0].conv.in_channels,
out_channels=self.rbr_conv[0].conv.out_channels,
kernel_size=self.rbr_conv[0].conv.kernel_size,
stride=self.rbr_conv[0].conv.stride,
padding=self.rbr_conv[0].conv.padding,
dilation=self.rbr_conv[0].conv.dilation,
groups=self.rbr_conv[0].conv.groups,
bias=True,
)
self.reparam_conv.weight.data = kernel
self.reparam_conv.bias.data = bias
# Delete un-used branches
for para in self.parameters():
para.detach_()
self.__delattr__("rbr_conv")
if hasattr(self, "rbr_skip"):
self.__delattr__("rbr_skip")
self.inference_mode = True
def _get_kernel_bias(self) -> Tuple[torch.Tensor, torch.Tensor]:
"""Method to obtain re-parameterized kernel and bias.
Reference: https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py#L83
:return: Tuple of (kernel, bias) after fusing branches.
"""
# get weights and bias of skip branch
kernel_identity = 0
bias_identity = 0
if self.rbr_skip is not None:
kernel_identity, bias_identity = self._fuse_skip_tensor(self.rbr_skip)
# get weights and bias of conv branches
kernel_conv = 0
bias_conv = 0
for ix in range(self.num_conv_branches):
if self.use_bn_conv:
_kernel, _bias = self._fuse_bn_conv_tensor(self.rbr_conv[ix])
else:
_kernel, _bias = self._fuse_conv_bn_tensor(self.rbr_conv[ix])
# pad kernel
if _kernel.shape[-1] < self.kernel_size:
pad = (self.kernel_size - _kernel.shape[-1]) // 2
_kernel = torch.nn.functional.pad(_kernel, [pad, pad, pad, pad])
kernel_conv += _kernel
bias_conv += _bias
kernel_final = kernel_conv + kernel_identity
bias_final = bias_conv + bias_identity
return kernel_final, bias_final
def _fuse_skip_tensor(self, branch) -> Tuple[torch.Tensor, torch.Tensor]:
"""
:param branch: skip branch, maybe include bn layer
:return: Tuple of (kernel, bias) after fusing batchnorm.
"""
if not hasattr(self, "id_tensor"):
input_dim = self.in_channels // self.groups
kernel_value = torch.zeros(
(self.in_channels, input_dim, self.kernel_size, self.kernel_size),
dtype=self.rbr_conv[0].conv.weight.dtype,
device=self.rbr_conv[0].conv.weight.device,
)
for i in range(self.in_channels):
kernel_value[
i, i % input_dim, self.kernel_size // 2, self.kernel_size // 2
] = 1
self.id_tensor = kernel_value
if isinstance(branch, nn.Identity):
kernel = self.id_tensor
return kernel, torch.zeros(
(self.in_channels),
dtype=self.rbr_conv[0].conv.weight.dtype,
device=self.rbr_conv[0].conv.weight.device,
)
else:
assert isinstance(
branch, nn.BatchNorm2d
), "Make sure the module in skip is nn. BatchNorm2d"
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def _fuse_bn_conv_tensor(self, branch) -> Tuple[torch.Tensor, torch.Tensor]:
"""先bn,后conv
:param branch:
:return: Tuple of (kernel, bias) after fusing batchnorm.
"""
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
std = (running_var + eps).sqrt()
t = gamma / std
t = torch.stack([t] * (kernel.shape[0] * kernel.shape[1]//t.shape[0]),dim=0).reshape(-1, self.in_channels // self.groups, 1, 1)
t_beta = torch.stack([beta] * (kernel.shape[0] * kernel.shape[1]//beta.shape[0]),dim=0).reshape(-1, self.in_channels // self.groups, 1, 1)
t_running_mean = torch.stack([running_mean] * (kernel.shape[0] * kernel.shape[1]//running_mean.shape[0]),dim=0).reshape(-1, self.in_channels // self.groups, 1, 1)
return kernel * t, torch.sum(
kernel
* (
t_beta - t_running_mean * t
),
dim=(1, 2, 3),
)
def _fuse_conv_bn_tensor(self, branch) -> Tuple[torch.Tensor, torch.Tensor]:
"""First conv, then bn
:param branch:
:return: Tuple of (kernel, bias) after fusing batchnorm.
"""
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def _conv_bn(
self,
in_chans: int,
out_chans: int,
kernel_size: int,
stride: int,
padding: int,
groups: int,
) -> nn.Sequential:
"""First conv, then bn
:param kernel_size: Size of the convolution kernel.
:param padding: Zero-padding size.
:return: Conv-BN module.
"""
mod_list = nn.Sequential()
mod_list.add_module(
"conv",
nn.Conv2d(
in_channels=in_chans,
out_channels=out_chans,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False,
),
)
mod_list.add_module("bn", nn.BatchNorm2d(num_features=out_chans))
return mod_list
def _bn_conv(
self,
in_chans: int,
out_chans: int,
kernel_size: int,
stride: int,
padding: int,
groups: int,
) -> nn.Sequential:
"""Add bn first, then conv"""
mod_list = nn.Sequential()
mod_list.add_module("bn", nn.BatchNorm2d(num_features=in_chans))
mod_list.add_module(
"conv",
nn.Conv2d(
in_channels=in_chans,
out_channels=out_chans,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False,
),
)
return mod_list

















 1064
1064

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









