








1 Logistic Regression
build a logistic regression model to predict whether a student gets admitted into a university
based on their results on two exams
training set:istorical data from previous applicants
1.1 Visualizing the data
Before starting to implement any learning algorithm, it is always good to visualize the data if possible.
ex2data1.txt(两科的成绩,和是否被录用)
34.62365962451697,78.0246928153624,0
30.28671076822607,43.89499752400101,0
35.84740876993872,72.90219802708364,0
60.18259938620976,86.30855209546826,1
。。。
%% Load Data
% The first two columns contains the exam scores and the third column
% contains the label.
data = load('ex2data1.txt');
X = data(:, [1, 2]); y = data(:, 3);
%% ==================== Part 1: Plotting ====================
% We start the exercise by first plotting the data to understand the
% the problem we are working with.
fprintf(['Plotting data with + indicating (y = 1) examples and o ' ...
'indicating (y = 0) examples.\n']);
plotData(X, y);
% Put some labels
hold on;
% Labels and Legend
xlabel('Exam 1 score')
ylabel('Exam 2 score')
% Specified in plot order
legend('Admitted', 'Not admitted')
hold off;
fprintf('\nProgram paused. Press enter to continue.\n');
pause;plotData.m
function plotData(X, y)
%PLOTDATA Plots the data points X and y into a new figure
% PLOTDATA(x,y) plots the data points with + for the positive examples
% and o for the negative examples. X is assumed to be a Mx2 matrix.
% Create New Figure
figure; hold on;
% ====================== YOUR CODE HERE ======================
% Instructions: Plot the positive and negative examples on a
% 2D plot, using the option 'k+' for the positive
% examples and 'ko' for the negative examples.
%
%Find Indices of Positive and Negative Examples
pos=find(y==1);%返回y==1的行标 组成的列向量
neg=find(y==0);%返回y==0的行标 组成的列向量
%plot Examples
plot(X(pos,1),X(pos,2),'k+','LineWidth',2,'MarkerSize',7);
plot(X(neg,1),X(neg,2),'ko','MarkerFaceColor','y','MarkerSize',7);
% =========================================================================
hold off;
end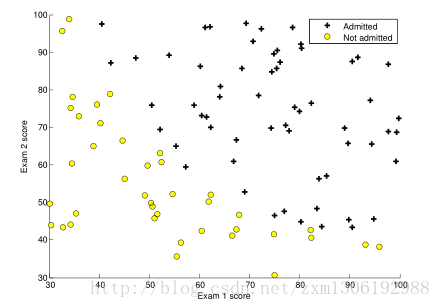
1.2 Implementation
1.2.1 Warmup exercixe:sigmoid function
logistic regression hypothesis is defined as:
hθ(x)=g(θTx)
g is the sigmoid funciton(S型函数),defined as:
g(z)=11+e−z
implement this function in sigmoid.m
function g = sigmoid(z)
%SIGMOID Compute sigmoid function
% g = SIGMOID(z) computes the sigmoid of z.
% You need to return the following variables correctly
g = zeros(size(z));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the sigmoid of each value of z (z can be a matrix,
% vector or scalar).
g=1./(1+exp(-z));
% =============================================================
end1.2.2 Cost function and gradient
the cost function in logistic regression is:
J(θ)=−1m∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
向量方式的实现是:
h=g(Xθ)J(θ)=1m⋅(−yTlog(h)−(1−y)Tlog(1−h))
梯度下降:
模板:
Repeat{θj:=θj−α∂∂θjJ(θ)}
求导后有:
Repeat{θj:=θj−αm∑i=1m(hθ(x(i))−y(i))x(i)j}
向量方式的实现是:
θ:=θ−αmXT(g(Xθ)−y⃗ )
求的导数值向量:
grad=
∂∂θjJ(θ)=1m∑i=1m(hθ(x(i))−y(i))x(i)j
costFunction.m
function [J, grad] = costFunction(theta, X, y)
%COSTFUNCTION Compute cost and gradient for logistic regression
% J = COSTFUNCTION(theta, X, y) computes the cost of using theta as the
% parameter for logistic regression and the gradient of the cost
% w.r.t. to the parameters.
% Initialize some useful values
m = length(y); % number of training examples
% You need to return the following variables correctly
J = 0;
grad = zeros(size(theta));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost of a particular choice of theta.
% You should set J to the cost.
% Compute the partial derivatives and set grad to the partial
% derivatives of the cost w.r.t. each parameter in theta
%
% Note: grad should have the same dimensions as theta
%
h=sigmoid(X*theta);
J=1/m*(-y'*log(h)-(1-y)'*log(1-h));
grad = (X' * (sigmoid(X*theta) - y)) ./ m;
% =============================================================
end
%% ============ Part 2: Compute Cost and Gradient ============
% In this part of the exercise, you will implement the cost and gradient
% for logistic regression. You neeed to complete the code in
% costFunction.m
% Setup the data matrix appropriately, and add ones for the intercept term
[m, n] = size(X);
% Add intercept term to x and X_test
X = [ones(m, 1) X];
% Initialize fitting parameters
initial_theta = zeros(n + 1, 1);
% Compute and display initial cost and gradient
[cost, grad] = costFunction(initial_theta, X, y);
fprintf('Cost at initial theta (zeros): %f\n', cost);
fprintf('Expected cost (approx): 0.693\n');
fprintf('Gradient at initial theta (zeros): \n');
fprintf(' %f \n', grad);
fprintf('Expected gradients (approx):\n -0.1000\n -12.0092\n -11.2628\n');
% Compute and display cost and gradient with non-zero theta
test_theta = [-24; 0.2; 0.2];
[cost, grad] = costFunction(test_theta, X, y);
fprintf('\nCost at test theta: %f\n', cost);
fprintf('Expected cost (approx): 0.218\n');
fprintf('Gradient at test theta: \n');
fprintf(' %f \n', grad);
fprintf('Expected gradients (approx):\n 0.043\n 2.566\n 2.647\n');
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
1.2.3 Learning parameters using fminunc
In the previous assignment, you found the optimal parameters of a linear regression model by implementing gradent descent. You wrote a cost function and calculated its gradient, then took a gradient descent step accordingly.This time, instead of taking gradient descent steps, you will use an Octave/MATLAB built-in function called fminunc.

In this code snippet, we first defined the options to be used with fminunc.Specifically, we set the GradObj option to on, which tells fminunc that our function returns both the cost and the gradient. This allows fminunc to use the gradient when minimizing the function. Furthermore, we set the MaxIter option to 400, so that fminunc will run for at most 400 steps before it terminates.
To specify the actual function we are minimizing, we use a “short-hand”for specifying functions with the @(t) ( costFunction(t, X, y) ) . This creates a function, with argument t, which calls your costFunction. This allows us to wrap the costFunction for use with fminunc.
Notice that by using fminunc, you did not have to write any loops yourself, or set a learning rate like you did for gradient descent. This is all done by fminunc: you only needed to provide a function calculating the cost and the gradient.
%% ============= Part 3: Optimizing using fminunc =============
% In this exercise, you will use a built-in function (fminunc) to find the
% optimal parameters theta.
% Set options for fminunc
options = optimset('GradObj', 'on', 'MaxIter', 400);
% Run fminunc to obtain the optimal theta
% This function will return theta and the cost
[theta, cost] = ...
fminunc(@(t)(costFunction(t, X, y)), initial_theta, options);
% Print theta to screen
fprintf('Cost at theta found by fminunc: %f\n', cost);
fprintf('Expected cost (approx): 0.203\n');
fprintf('theta: \n');
fprintf(' %f \n', theta);
fprintf('Expected theta (approx):\n');
fprintf(' -25.161\n 0.206\n 0.201\n');
% Plot Boundary
plotDecisionBoundary(theta, X, y);
% Put some labels
hold on;
% Labels and Legend
xlabel('Exam 1 score')
ylabel('Exam 2 score')
% Specified in plot order
legend('Admitted', 'Not admitted')
hold off;
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
plotDecisionBoundary.m
function plotDecisionBoundary(theta, X, y)
%PLOTDECISIONBOUNDARY Plots the data points X and y into a new figure with
%the decision boundary defined by theta
% PLOTDECISIONBOUNDARY(theta, X,y) plots the data points with + for the
% positive examples and o for the negative examples. X is assumed to be
% a either
% 1) Mx3 matrix, where the first column is an all-ones column for the
% intercept.
% 2) MxN, N>3 matrix, where the first column is all-ones
% Plot Data
plotData(X(:,2:3), y);
hold on
if size(X, 2) <= 3
% Only need 2 points to define a line, so choose two endpoints
plot_x = [min(X(:,2))-2, max(X(:,2))+2];
% Calculate the decision boundary line
plot_y = (-1./theta(3)).*(theta(2).*plot_x + theta(1));
% Plot, and adjust axes for better viewing
plot(plot_x, plot_y)
% Legend, specific for the exercise
legend('Admitted', 'Not admitted', 'Decision Boundary')
axis([30, 100, 30, 100])
else
% Here is the grid range
u = linspace(-1, 1.5, 50);
v = linspace(-1, 1.5, 50);
z = zeros(length(u), length(v));
% Evaluate z = theta*x over the grid
for i = 1:length(u)
for j = 1:length(v)
z(i,j) = mapFeature(u(i), v(j))*theta;
end
end
z = z'; % important to transpose z before calling contour
% Plot z = 0
% Notice you need to specify the range [0, 0]
contour(u, v, z, [0, 0], 'LineWidth', 2)
end
hold off
end
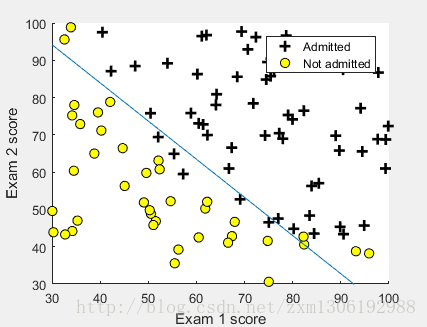
1.2.4 Evaluating logistic regression
%% ============== Part 4: Predict and Accuracies ==============
% After learning the parameters, you'll like to use it to predict the outcomes
% on unseen data. In this part, you will use the logistic regression model
% to predict the probability that a student with score 45 on exam 1 and
% score 85 on exam 2 will be admitted.
%
% Furthermore, you will compute the training and test set accuracies of
% our model.
%
% Your task is to complete the code in predict.m
% Predict probability for a student with score 45 on exam 1
% and score 85 on exam 2
prob = sigmoid([1 45 85] * theta);
fprintf(['For a student with scores 45 and 85, we predict an admission ' ...
'probability of %f\n'], prob);
fprintf('Expected value: 0.775 +/- 0.002\n\n');
% Compute accuracy on our training set
p = predict(theta, X);
fprintf('Train Accuracy: %f\n', mean(double(p == y)) * 100);%将所有数据放入模型计算,看是否和真实注解一直,来计算模型的准确性
fprintf('Expected accuracy (approx): 89.0\n');
fprintf('\n');predict.m
function p = predict(theta, X)
%PREDICT Predict whether the label is 0 or 1 using learned logistic
%regression parameters theta
% p = PREDICT(theta, X) computes the predictions for X using a
% threshold at 0.5 (i.e., if sigmoid(theta'*x) >= 0.5, predict 1)
m = size(X, 1); % Number of training examples
% You need to return the following variables correctly
p = zeros(m, 1);
% ====================== YOUR CODE HERE ======================
% Instructions: Complete the following code to make predictions using
% your learned logistic regression parameters.
% You should set p to a vector of 0's and 1's
%
s=sigmoid(X*theta);
for i=1:m
if s(i)>= 0.5
p(i)=1;
else
p(i)=0;
end
end
%方法二:
% p = floor(sigmoid(X*theta) .* 2)
% =========================================================================
end
2 Regularized logistic regression
预测工厂生产的芯片是否合格
predict whether microchips from a fabrication plant passes quality assurance (QA).
2.1 Visualizing the data
ex2data2.txt
0.051267,0.69956,1
-0.092742,0.68494,1
-0.21371,0.69225,1
-0.375,0.50219,1
-0.51325,0.46564,1
…
数据特征为两种测试的分数,标签为 是否可以接受
%% Initialization
clear ; close all; clc
%% Load Data
% The first two columns contains the X values and the third column
% contains the label (y).
data = load('ex2data2.txt');
X = data(:, [1, 2]); y = data(:, 3);
plotData(X, y);
% Put some labels
hold on;
% Labels and Legend
xlabel('Microchip Test 1')
ylabel('Microchip Test 2')
% Specified in plot order
legend('y = 1', 'y = 0')
hold off;
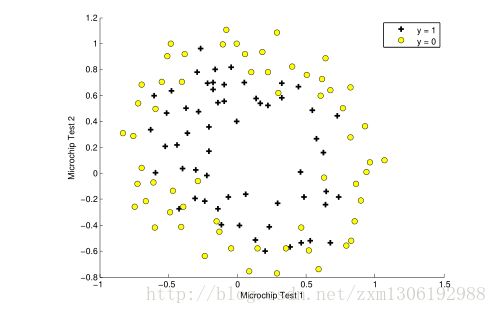
Figure 3 shows that our dataset cannot be separated into positive and negative examples by a straight-line through the plot. Therefore, a straightforward application of logistic regression will not perform well on this dataset since logistic regression will only be able to find a linear decision boundary.
2.2 Feature mapping
One way to fit the data better is to create more features from each data point. In the provided function mapFeature.m, we will map the features into all polynomial terms of x1 and x2 up to the sixth power.
mapFeature(x)= ⎡⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢1x1x2x21x1x2x22x31...x1x52x62⎤⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥
As a result of this mapping, our vector of two features (the scores on two QA tests) has been transformed into a 28-dimensional vector. A logistic regression classifier trained on this higher-dimension feature vector will have a more complex decision boundary and will appear nonlinear(非线性) when drawn in our 2-dimensional plot.
特征映射可以让我们构造更富表现力的分类器,但也更易过拟合。
2.3 Cost function and gradient
the regularized cost function in logistic regression is:
J(θ)=−1m∑i=1m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+λ2m∑j=1nθ2j
Note that you should not regularize the parameter θ0 . (注:根据惯例,我们不对 θ0 进行惩罚。)
要最小化该代价函数,通过求导,得出梯度下降算法为:
Repeat { θ0:=θ0−α 1m ∑i=1m(hθ(x(i))−y(i))x(i)0 θj:=θj−α [(1m ∑i=1m(hθ(x(i))−y(i))x(i)j)+λmθj]} j∈{1,2...n}
注:看上去同线性回归一样,但是知道 hθ(x)=g(θTX),所以与线性回归不同。
%% =========== Part 1: Regularized Logistic Regression ============
% In this part, you are given a dataset with data points that are not
% linearly separable. However, you would still like to use logistic
% regression to classify the data points.
%
% To do so, you introduce more features to use -- in particular, you add
% polynomial features to our data matrix (similar to polynomial
% regression).
%
% Add Polynomial Features
% Note that mapFeature also adds a column of ones for us, so the intercept
% term is handled
X = mapFeature(X(:,1), X(:,2));
% Initialize fitting parameters
initial_theta = zeros(size(X, 2), 1);
% Set regularization parameter lambda to 1
lambda = 1;
% Compute and display initial cost and gradient for regularized logistic
% regression
[cost, grad] = costFunctionReg(initial_theta, X, y, lambda);
fprintf('Cost at initial theta (zeros): %f\n', cost);
fprintf('Expected cost (approx): 0.693\n');
fprintf('Gradient at initial theta (zeros) - first five values only:\n');
fprintf(' %f \n', grad(1:5));
fprintf('Expected gradients (approx) - first five values only:\n');
fprintf(' 0.0085\n 0.0188\n 0.0001\n 0.0503\n 0.0115\n');
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
% Compute and display cost and gradient
% with all-ones theta and lambda = 10
test_theta = ones(size(X,2),1);
[cost, grad] = costFunctionReg(test_theta, X, y, 10);
fprintf('\nCost at test theta (with lambda = 10): %f\n', cost);
fprintf('Expected cost (approx): 3.16\n');
fprintf('Gradient at test theta - first five values only:\n');
fprintf(' %f \n', grad(1:5));
fprintf('Expected gradients (approx) - first five values only:\n');
fprintf(' 0.3460\n 0.1614\n 0.1948\n 0.2269\n 0.0922\n');
fprintf('\nProgram paused. Press enter to continue.\n');
pause;
costFunctionReg.m
function [J, grad] = costFunctionReg(theta, X, y, lambda)
%COSTFUNCTIONREG Compute cost and gradient for logistic regression with regularization
% J = COSTFUNCTIONREG(theta, X, y, lambda) computes the cost of using
% theta as the parameter for regularized logistic regression and the
% gradient of the cost w.r.t. to the parameters.
% Initialize some useful values
m = length(y); % number of training examples
% You need to return the following variables correctly
J = 0;
grad = zeros(size(theta));
% ====================== YOUR CODE HERE ======================
% Instructions: Compute the cost of a particular choice of theta.
% You should set J to the cost.
% Compute the partial derivatives and set grad to the partial
% derivatives of the cost w.r.t. each parameter in theta
h=sigmoid(X*theta);
J=1/m*(-y'*log(h)-(1-y)'*log(1-h))+lambda/(2*m)*(sum(theta.^2) - theta(1)^2);
grad(1)=(X(:,1)' * (h - y)) ./ m;
for i = 2:size(theta)
grad(i) = (X(:,i)' * (h - y)) ./ m+lambda/m*theta(i);
% =============================================================
end2.3.1 Learning parameters using fminunc
Similar to the previous parts, you will use fminunc to learn the optimal parameters θ.
%% ============= Part 2: Regularization and Accuracies =============
% Optional Exercise:
% In this part, you will get to try different values of lambda and
% see how regularization affects the decision coundart
%
% Try the following values of lambda (0, 1, 10, 100).
%
% How does the decision boundary change when you vary lambda? How does
% the training set accuracy vary?
%
% Initialize fitting parameters
initial_theta = zeros(size(X, 2), 1);
% Set regularization parameter lambda to 1 (you should vary this)
lambda = 1;
% Set Options
options = optimset('GradObj', 'on', 'MaxIter', 400);
% Optimize
[theta, J, exit_flag] = ...
fminunc(@(t)(costFunctionReg(t, X, y, lambda)), initial_theta, options);
% Plot Boundary
plotDecisionBoundary(theta, X, y);
hold on;
title(sprintf('lambda = %g', lambda))
% Labels and Legend
xlabel('Microchip Test 1')
ylabel('Microchip Test 2')
legend('y = 1', 'y = 0', 'Decision boundary')
hold off;
% Compute accuracy on our training set
p = predict(theta, X);
fprintf('Train Accuracy: %f\n', mean(double(p == y)) * 100);
fprintf('Expected accuracy (with lambda = 1): 83.1 (approx)\n');
plotDecisionBoundary.m
function plotDecisionBoundary(theta, X, y)
%PLOTDECISIONBOUNDARY Plots the data points X and y into a new figure with
%the decision boundary defined by theta
% PLOTDECISIONBOUNDARY(theta, X,y) plots the data points with + for the
% positive examples and o for the negative examples. X is assumed to be
% a either
% 1) Mx3 matrix, where the first column is an all-ones column for the
% intercept.
% 2) MxN, N>3 matrix, where the first column is all-ones
% Plot Data
plotData(X(:,2:3), y);
hold on
if size(X, 2) <= 3
% Only need 2 points to define a line, so choose two endpoints
plot_x = [min(X(:,2))-2, max(X(:,2))+2];
% Calculate the decision boundary line
plot_y = (-1./theta(3)).*(theta(2).*plot_x + theta(1));
% Plot, and adjust axes for better viewing
plot(plot_x, plot_y)
% Legend, specific for the exercise
legend('Admitted', 'Not admitted', 'Decision Boundary')
axis([30, 100, 30, 100])
else
% Here is the grid range
u = linspace(-1, 1.5, 50);
v = linspace(-1, 1.5, 50);
z = zeros(length(u), length(v));
% Evaluate z = theta*x over the grid
for i = 1:length(u)
for j = 1:length(v)
z(i,j) = mapFeature(u(i), v(j))*theta;
end
end
z = z'; % important to transpose z before calling contour
% Plot z = 0
% Notice you need to specify the range [0, 0]
contour(u, v, z, [0, 0], 'LineWidth', 2)
end
hold off
end
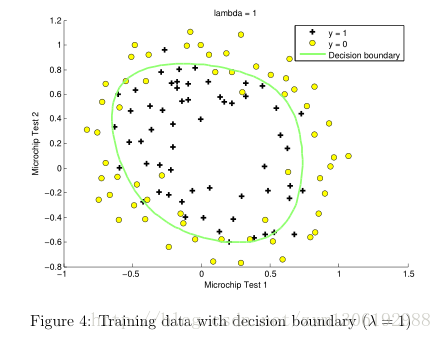
改变 正则化参数 (regularization parameters) λ的值,发现
如果过小,训练数据拟合的很好,边界会很复杂,容易过拟合(over fitting),见Figure 5
如果过大,会出现欠拟合(under fitting),见Figure 6















 1931
1931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









