







在对GAN进行学习的过程中参考了一些好的文章,在此总结出来自己认为有意义的学习笔记。
参考原文:http://blog.csdn.net/zouxy09/article/details/8195017
http://blog.csdn.net/on2way/article/details/72773771
Generative Adversarial Nets
GAN的鼻祖之作是2014年NIPS一篇文章:Generative Adversarial Net,可以细细品味。
GAN的思想是是一种二人零和博弈思想(two-player game),博弈双方的利益之和是一个常数,比如两个人掰手腕,假设总的空间是一定的,你的力气大一点,那你就得到的空间多一点,相应的我的空间就少一点,相反我力气大我就得到的多一点,但有一点是确定的就是,我两的总空间是一定的,这就是二人博弈。
引申到GAN里面就是可以看成,GAN中有两个这样的博弈者,一个人名字是生成模型(G),另一个人名字是判别模型(D)。他们各自有各自的功能。
一个简单的例子如下图所示:假设在训练开始时,真实样本分布、生成样本分布以及判别模型分别是图中的黑线、绿线和蓝线。可以看出,在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成模型,而优化判别模型时,优化结果如第二幅图所示,可以看出,这个时候判别模型已经可以较好的区分生成数据和真实数据了。第三步是固定判别模型,改进生成模型,试图让判别模型无法区分生成图片与真实图片,在这个过程中,可以看出由模型生成的图片分布与真实图片分布更加接近,这样的迭代不断进行,直到最终收敛,生成分布和真实分布重合。
判别网络说,我很强,来一个样本我就知道它是来自真样本集还是假样本集。生成网络就不服了,说我也很强,我生成一个假样本,虽然我生成网络知道是假的,但是你判别网络不知道呀,我包装的非常逼真,以至于判别网络无法判断真假,那么用输出数值来解释就是,生成网络生成的假样本进去了判别网络以后,判别网络给出的结果是一个接近0.5的值,极限情况就是0.5,也就是说判别不出来了,这就是纳什平衡了。
详细的实现过程:
初始化阶段:
初始化生成模型G、判别模型D。
前向传播阶段:
一. 可以有两种输入1. 随机产生一个随机向量作为生成模型的数据,然后经过生成模型后产生一个新的向量,作为Fake Image,记作z。
2. 从数据集中随机选择一张图片,将图片转化成向量,作为Real Image,记作x。
二. 将由1或者2产生的输出,作为判别网络的输入,经过判别网络后输出一个0到1之间的数,用于表示输入图片为Real Image的概率,real为1,fake为0。
根据输入的图片类型是Fake Image或Real Image将判别模型的输入数据的label标记为0或者1。即判别模型的输入类型为 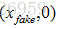

判别模型的损失函数:
当输入的是从数据集中取出的Real Image时,只需要考虑第二部分。D(x)为判别模型的输出,表示输入x为real 数据的概率,目的是让判别模型的输出D(x)的输出尽量靠近1。
当输入的是fake时,只计算第一部分,G(z)是生成模型的输出,输出的是一张Fake Image。我们要做的是让D(G(z))的输出尽可能趋向于0。这样的判别模型是有区分力的。
生成模型的损失函数:
对于生成模型来说,我们要做的是让G(z)产生的数据尽可能的和数据集中的数据一样。就是所谓的同样的数据分布。那么我们要做的就是最小化生成模型的误差,即只将由G(z)产生的误差传给生成模型。
最终的损失函数为:
其中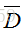
优化函数:
需要注意的是生成模型与对抗模型可以说是完全独立的两个模型,好比就是完全独立的两个神经网络模型,他们之间没有什么联系。那么训练这样的两个模型的大方法就是:单独交替迭代训练。
假设现在生成网络模型已经有了,那么给一堆随机数组,就会得到一堆假的样本集,真样本集一直都有。现在我们人为的定义真假样本集的标签,因为我们希望真样本集的输出尽可能为1,假样本集为0,很明显这里我们就已经默认真样本集所有的类标签都为1,而假样本集的所有类标签都为0。这样单就判别网络来说,此时问题就变成了一个再简单不过的有监督的二分类问题了,直接送到神经网络模型中训练就完事了。假设训练完了,下面我们来看生成网络。
对于生成网络,想想我们的目的,是生成尽可能逼真的样本。那么原始的生成网络生成的样本你怎么知道它真不真呢?就是送到判别网络中,所以在训练生成网络的时候,我们需要联合判别网络一起才能达到训练的目的。所以对于生成网络的训练其实是对生成-判别网络串接的训练。
对于生成网络的训练,我们有了样本集(只有假样本集,没有真样本集),有了对应的label(全为1),就可以训练了。有人说,你这样一训练,判别网络的网络参数不是也跟着变吗?没错,这很关键,所以在训练这个串接的网络的时候,一个很重要的操作就是不要判别网络的参数发生变化,也就是不让它参数发生更新,只是把误差一直传,传到生成网络那块后更新生成网络的参数。这样就完成了生成网络的训练了。
完成生成网络训练后,那么我们可以根据目前新的生成网络再对先前的那些噪声Z生成新的假样本,并且训练后的假样本应该是更真了才对。然后又有了新的真假样本集(其实是新的假样本集),这样又可以重复上述过程。我们把这个过程称作为单独交替训练。我们可以实现定义一个迭代次数,交替迭代到一定次数后停止即可。这个时候我们再去看一看噪声Z生成的假样本会发现,原来它已经很真了。
原始论文中的目标公式吧:
上述这个公式说白了就是一个最大最小优化问题,其实对应的也就是上述的两个优化过程。
拆解就如同下面两个公式:
优化D:
优化G:
优化D的时候,也就是判别网络,其实没有生成网络什么事,后面的G(z)这里就相当于已经得到的假样本。优化D的公式的第一项,使的真样本x输入的时候,得到的结果越大越好,可以理解,因为需要真样本的预测结果越接近于1越好。对于假样本,需要优化是的其结果越小越好,也就是D(G(z))越小越好,因为它的标签为0。但是呢第一项是越大,第二项是越小,这就矛盾了,所以呢把第二项改成1-D(G(z)),这样就是越大越好,两者合起来就是越大越好。
优化G的时候,这个时候没有真样本什么事,所以把第一项直接去掉了。这个时候只有假样本,但是我们说这个时候是希望假样本的标签是1的,所以是D(G(z))越大越好,但是呢为了统一成1-D(G(z))的形式,那么只能是最小化1-D(G(z))。
本质上没有区别,只是为了形式的统一。之后这两个优化模型可以合并起来写,就变成了最开始的那个最大最小目标函数了。
GAN强大之处在于可以自动的学习原始真实样本集的数据分布,不管这个分布多么的复杂,只要训练的足够好就可以学出来。
生成模型最后可以通过噪声生成一个完整的真实数据(比如人脸),说明生成模型已经掌握了从随机噪声到人脸数据的分布规律了,有了这个规律,想生成人脸还不容易。然而这个规律我们开始知道吗?显然不知道,如果让你说从随机噪声到人脸应该服从什么分布,你不可能知道。这是一层层映射之后组合起来的非常复杂的分布映射规律。然而GAN的机制可以学习到,也就是说GAN学习到了真实样本集的数据分布。















 2492
2492

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









