






目录
一、基础知识
数据压缩指的是减少表示给的信息量所需数据量的处理。数据和信息是不相同的事情,数据是信息传递的手段;包含不相同或重复信息的表示叫做冗余数据。压缩率公式为,b通常用二维灰度值阵列表示一幅图像所需的比特数。二维灰度值阵列受下面三种可被识别和利用的三种主要类型的数据冗余,一为编码冗余,二为空间和时间冗余,三为不相关的信息。
1.冗余
编码冗余:使用来表示每个
值的比特数,那么表示每个像素所需的平均比特数为
,即给各个灰度级分配的码字的平均长度可以通过对用于表示每个灰度的比特数与该灰度出现的概率的乘积求和得到。对当前事件集合分配码时,如果不取全部时间概率的优势,就会出现编码冗余。
空间冗余和时间冗余:为减少空间与时间相关的像素涉及的冗余,二维灰度值阵列必须变换为更有效但通常不可见的表示,即映射。如果二维灰度阵列的像素可以根据变换后的数据集合无误的重建,那么就是可逆映射,否则就是不可逆映射。
不相关的信息:压缩数据集最简单的方法是从集合中消除多余的数据。因为去除不相关的信息会导致定量信息的损失,因此称之为量化。
2.度量
信息论提供了回答存储一幅图像实际需要多少比特等相关的问题,其前提是信息的产生可以用一个概率过程建模,这个过程可以用一种与直觉一致的方式加以度量。因此一个概率为P(E)的随机事件E包含单位的信息。如果以m为底数,那么就叫m元单位,如果底数为2则单位为比特。
每个信源输出的平均信息称为该信源的熵。信源本身叫做零记忆信源。
山农第一定理也叫做无噪声编码定理,山农使用一个单一码字考察了n个连续信源符号表示的组合。它告诉我们每信源符号H信息单位的平均来表示零记忆信源的输出是有可能的。当信息源的输出依赖于前面有限数量的输出时,那么就称其为马尔可夫信源或有限记忆信源。
3.保真度准则
需要有一种量化信息丢失的本质的方法,分为主观保真度准则和客观保真度准则。当信息损失可以表示为压缩处理的输入和输出的数学函数时就是以客观保真度准则为基础的。主观保真度准则是以人的主观评估来衡量图像的质量,这种方法更加恰当。它是通过向观察者显示解压缩的图像,并将他们的评估结果进行评估得到的。
4.图像压缩模型
下图为一个图像压缩系统的功能流程图,其有一个编码器和一个解码器组成。编码器进行压缩操作,解码器进行解压缩的互补操作。
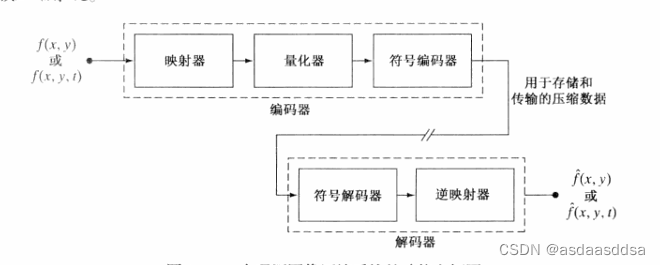
如果能过精确进行复制那么就称其为无误差的、无损的或信息保持的压缩系统;如果不能精确复制那么重建的图像会失真,称为有损压缩系统。
图像文件格式是组织和存储图像数据的标准方法,定义了所使用的数据排列的方式和压缩的类型;图像容器类似于文件格式,主要是处理多类型的图像数据;图像压缩标准定义减少表示一幅图像所需数据量的过程。
二、压缩方法
1.霍夫曼编码
霍夫曼编码对每个信源符号产生了可能最小数量的编码符号。实践中信浓符号不是图像的灰度就是一个灰度映射操作的输出。霍夫曼方法的步骤:1.通过对所考虑符号的概率进行排序,并将具有最小概率的符号合并为一个符号来替代下次信源化简过程中的符号,从而创建一个简化信源系列 2.对每个化简后的信源进行编码。
编码是一种瞬时的、唯一可解码的块编码。块编码在于其每个信源符号都映射到了一个编码符号的固定序列中,瞬时在于其编码符号串中的每个码字无须参考后续符号就可以进行解码,唯一可解码在于其任何编码符号串只能以一种方式进行解码。
2.Golomb编码
它是具有指数衰减概率分布输入的非负的整数编码,计算上比霍夫曼编码还简单,可以被最佳化编码。产生Golomb编码所要求的除法变成二进制移位操作和计算上更简单的编码,这种编码叫做Golomb-Rice码。Golomb码只能表示非负整数,很少用于灰度编码。表示的n关于m的Golomb编码是商
的一元编码和n mod m 的二进制表示的一个合并。其构建为1.形成商
的一元编码 2.令
r=n mod m,计算截短的余数
3.连接1和2的结果。
k阶指数Golomb编码计算为1.寻找一个整数i,满足
,形成i的一元码. 2.把二进制表示
截短到k+i个最低阶比特 3.连接1和2的结果。
也是一种瞬时的、唯一可解码的块编码。
3.算术编码
算术编码生成的是非块码,它给信源符号的整个序列分配了一个单一的算术码字。其次它不要求将每个信源符号转化为这些编码符号的整数,所以(仅在理论上)达到了山农第一定理所设定的界限。下图为算术编码的基本过程图:
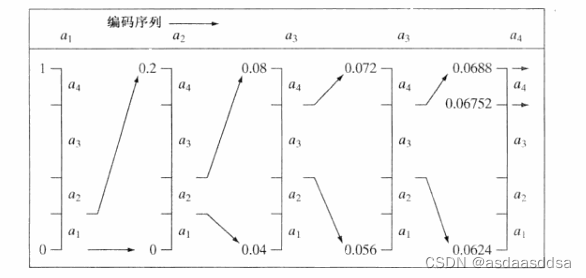
实际中导致算术编码无法达到了山农第一定理所设定的界限的原因有1.为了将一个消息和其他消息分开增加了消息提示符。 2.所用算法的精度是有限的。通过引入一种缩放策略和一种舍入策略解决第二个问题。
缩放策略:在根据符号出现的概率细分每个子区间之前,将每个子区间重新归一化到区间[0,1)。
舍入策略:保证根据算法的有限精度进行截短,不会妨碍被编码子区间的准确表示。
使用自适应、上下文相关的概率模型来改进所采用概率精确性。自适应概率模型像符号已被编码或变得已知那样更新符号的概率;上下文相关的模型提供了概率,该概率基于被编码符号周围的预定义的领域像素。
4.LZW编码
LZW编码将定长码字分配给变成信源符号序列,致力于图像中的空间冗余的无误差压缩方法。其关键特点在于不需要被编码符号出现的概率的先验知识。特点在于编码字典或码书是在对数据进行编码的同时创建的。
处理字典溢出的策略:1.当字典已满时,刷新或重新初始化该字典,并使用一个新初始化后的字典继续编码 2.监控压缩性能,并在性能变得低下或不可接受时刷新字典。
5.行程编码
行程编码指的是沿其行或列的重复灰度的图像,可以用相同灰度的行程表示为行程对来压缩,其中每个行程对指定一个新灰度的开始和具有该灰度的连续像素的数量。成为了传真标准的压缩方法。对于压缩二值图像特别有效。
CCITT Group3和4标准是两种最古老、应用最广的二值图像压缩标准,Group3标准使用一维行程编码技术,Group4是Group3标准的简化或改进版本,只允许进行二维编码。
一维CCITT压缩中一幅图像的每一行被编码为一系列变长的霍夫曼码字,在从左到右的扫描中,表示交替的白色和黑色行程,采用的压缩方法叫做改进的霍夫曼编码方法。码字有终结码和补偿码两种。
二维CCITT压缩:两个标准采用的二维压缩方法是逐行方法,即对每个黑到白或白到黑的行程转换的位置根据位于当前编码行上的参考元素的位置进行编码。所用的二维编码技术叫做相对元素地址指派(READ)编码。Group 3里面使用的为相继的MH编码行间允许1个或3个READ编码行叫做改进的READ(MR)编码;Group 4里面允许较大数量的READ编码行叫做改进的REDA(MMR)编码。
6.基于符号的编码
符号:一幅图像被表示为多幅频繁发生的子图像的一个集合。把图像以一个三元组的集合来编码,每一个三元组表示图像中一个字典符号的一个实例,仅存储一次重复的符号。
JBIG2是针对二级图像压缩的国际标准,将一幅图像分割成正文、半色调和普通内容的重叠和/或不重叠区域,针对每种类型采用特定的最佳压缩技术。
对于字符组成的正文区域,采用基于符号的编码方式。在有损JBIG2压缩中,通常称为感知无损或视觉无损的JBIG2,忽略字典位图和图像中相应字符的特例之间的差别。位图使用MMR编码;用于访问字典条目的三元组使用算术编码或者霍夫曼编码。
半色调区域类似正文区域,有按规则网格排列的模式组成。通过抖动来产生用于打印的两灰度级图像。
普通区域包含非正文、非半色调信息,使用算术编码方式或者MMR编码进行压缩。
7.比特平面编码
比特平面编码就是把一幅多级图像分解为一系列二值图像,并使用几种熟知的二值压缩方法之一来压缩每幅二值图像。一共有两种分解方法。
方法一:一幅m比特单色图像的灰度可以用如下形式的基2的多项式表示:
可以使用把该多项式的m个系数分离为m个1比特的比特平面来将其分解为二值图像集。缺点是灰度的较小变化会对比特平面的复杂性产生显著的影响。
另一种方法是首先用一个m比特格雷码表示图像。特性是连续码字只有1个比特位不同。
8.块变换编码
首先定义了一种压缩技术,该技术可以把图像分成大小相等且不重叠的小块,并使用二维变换单独的处理这些块。其次在块变换编码中,用一种可逆线性变换把每个块或子图映射为变换系数集合,然后对变换系数进行量化和编码。一个典型的块编码系统如下图所示:
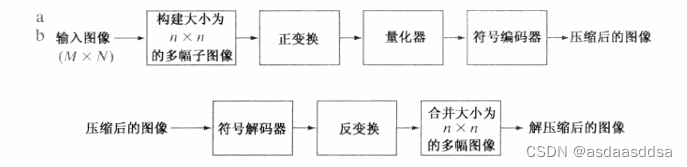
任何或所有的变换编码步骤都可以根据局部图像内容进行适应性调整,叫做自适应变换编码;如果这些步骤对子图像是固定的那就是非自适应变换编码。
变换的选择取决于可容忍的重建误差的大小和可用的计算资源。离散变换可以表示为:
离散反变换公式为:
r和s称为正变换核和反变换核,也叫做基函数或基图像。变换编码中有用且计算简单的一个变换是Walsh-Hadamard变换(WHT),它的核由棋盘模式交替排列的+1和-1组成。此外还有离散余弦变换(DCT)。
多数变换编码系统都基于DCT,DCT在信息携带能力和计算复杂性之间提供了好的折中。DCT的优点有:用单片集成电路就可以实现,可将最多信息装入最少的系数中,在子图像间的边界变得可见时,可使块效应最小化。
子图像尺寸也会影响变换编码的误差和计算复杂度。压缩水平和计算复杂性会随子图像尺寸的增加而增大。
在变换编码中,区域编码指的是保留的系数是根据最大方差进行选择的;阈值编码指的是根据最大幅度进行选择;比特分配指的是对变换后的子图像的系数进行截取、量化和编码的过程。
区域编码是以信息论中观察信息为不确定性的概念为基础的。区域取样过程中保留的系数必须被量化和编码。
阈值编码在为每幅彼此不同的子图像保留变换系数的位置方面具有固定的自适应性。方法是对于任何子图像,最大幅值的变换系数对重建后的子图像的质量贡献最大。有三种途径可以对一幅变换后的子图像进行阈值处理,其一为对所有子图像使用单一的全局阈值,其二为对每幅子图像使用不同的阈值,其三为阈值可以随子图像内每个系数的位置的变换而变化。
JPEG是使用最为普遍且广泛的连续色调静止帧压缩标准,定义了三种不同的编码系统:(1)一种有损的基本编码系统,以DCT为基础,对大多数压缩足够使用。(2)一种扩展的编码系统,面向更大压缩、更高精度或渐进的重建应用。(3)一种面向可逆压缩的无损独立编码系统。
9.预测编码
预测编码通过消除紧邻像素在空间和时间上的冗余来实现的,仅对每个像素中的新信息进行提取和编码。它不需要较大的计算开销以及压缩可以是无误差或有损的压缩。
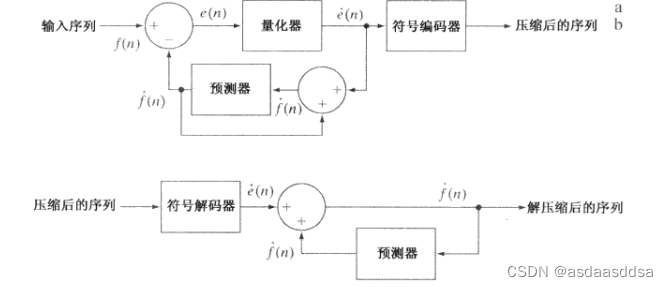
无损预测编码由一个编码器和一个解码器组成,如下图所示:
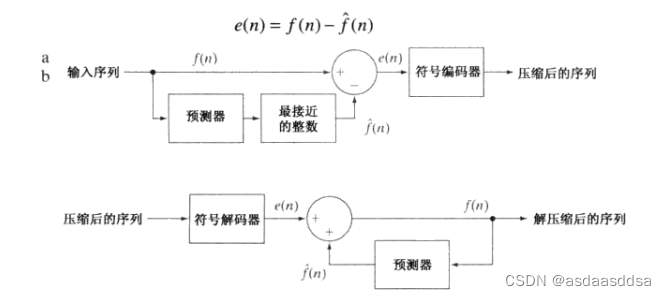
一维线性预测仅是当前行上前几个像素的函数;二维预测编码中,是一幅图像从左到右、从上到下扫描的前几个像素的函数;三维情况下,是以这些像素和前几帧图像的前几个像素为基础的。预测编码达到的压缩与将输入图像映射到一个预测误差序列所得到的熵的减少直接相关,叫做预测残差。
当处理有很少时间冗余的图像时,就会发生数据扩展。其解决方法有两种:(1)在预测和差分处理期间,跟踪目标运动并对其进行补偿。(2)当存在帧间相关而不足以发挥预测编码的优点时,转换为另一种编码。没有预测残差的帧称为内帧或独立帧(I帧),它是生成预测残差的理想起点。最常用的一种误差度量是平均绝对失真(MAD),公式为:
其次还有绝对失真和(SAD),忽略了上式的1/mn。
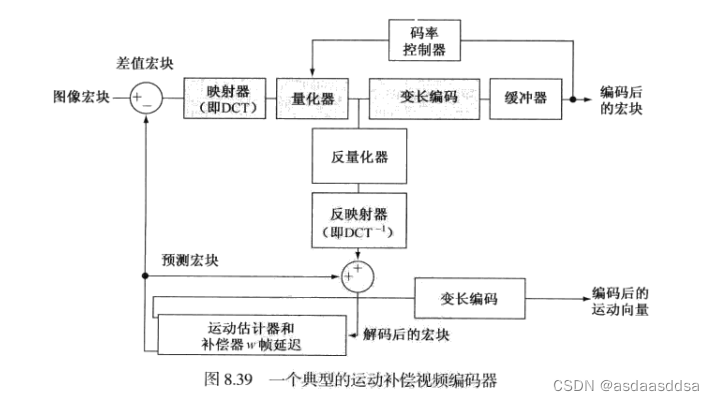
运动估计是一个要求计算量的任务,只有编码器必须估计宏块运动,解码器只需要简单的访问编码器中用于形成预测残差的参考帧的区域。下图为一个典型的运动补偿视频编码器,主要利用帧内和相邻视频帧间的冗余度、帧间的运动均匀性以及人类视觉系统的心理视觉特性。被设计用于产生于预期的视频信道容量相匹配的压缩比特流。
有损预测编码在无损预测编码模型中加入了一个量化器,并在空间预测器的上下文中,探讨重建精度和压缩性能间的折中,其结构如下图所示:
调制是简单并且知名的有损预测编码形式,当变换过程中太小而不足以表示输入的最大变化,会产生斜率过载的失真;
太大而不足以表示输入的最小变化会出现颗粒噪声。两种现象会导致模糊的物体边缘和颗粒表面或噪声表面。
最佳的准则是最小的均方差误差,最佳预测器设计问题简化为了相对简单的选择m个预测系数的问题。差分脉冲编码调制(DPCM)指的是量化误差假设可以忽略,且预测被约束为前m个样本的一个线性组合,通过这样得到的预测编码。劳埃德-马克斯和最佳均匀量化器不是自适应的,是以图像的局部特性为基础来调整量化级别的。它可以降低颗粒噪声和斜率过载。
10.小波编码
小波编码对图像的像素解除相关的变换系数进行编码比对原图像像素本身进行编码的效率更高。下图为一个典型的小波编码系统,它与变换编码系统之间的主要区别为省略了变换编码器的子图像处理阶段,这是因为小波变换的计算效率和固有的局部性,没必要对原图像进行细分。
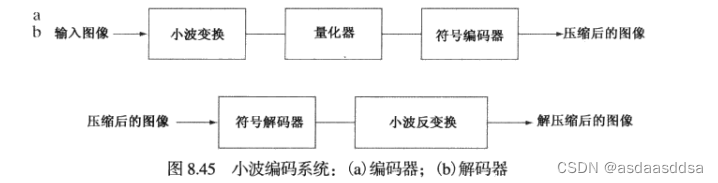
小波的选择将会直接影响到变换的计算复杂性或者间接的影响到压缩和重建具有可接受误差的图像系统的能力。基于小波的压缩广泛使用的展开函数为Daubechies小波和双正交小波。
实现小波编码的实验,这里使用的是haar小波,其代码为:
import cv2
import numpy as np
import matplotlib.pyplot as plt
from pywt import dwt2, idwt2
img = cv2.imread(r'D:\test\huidu.jpg',0)
cA, (cH, cV, cD) = dwt2(img, 'haar')
rimg = idwt2((cA, (cH, cV, cD)), 'haar')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.subplot(121), plt.imshow(img, 'gray'), plt.title('原始图像'), plt.axis('off')
plt.subplot(122), plt.imshow(rimg, 'gray'), plt.title('重构图像'), plt.axis('off')
cv2.imwrite(r'D:\test\huidu_huiyin.jpg', rimg)
plt.show()
结果为:


可以看到经过小波变换之后的图片被压缩为了原图片的大约1/11倍,代码中使用的是pyrhon里面的小波分析库PyWavelets来进行小波的分解和重构。
变换分解级别的数量也会影响小波编码计算复杂性和重建误差的因素。其次最重要的因素为系数量化。量化的效率可以通过以下方法改进:(1)引入一个以0为中心的较大量化间隔,称为死区。(2)从一个尺度到另一个尺度自适应调整量化间隔的大小。但是其选择的量化间隔必须随着编码图像的比特流传送给解码器。
JPEG-2000是JPEG技术的扩充,在连续色调静止图像的压缩和压缩数据的访问方面提供了更大的灵活性。该标准以小波编码技术为基础。对于不可逆压缩必须以子带为基础像解码器提供指数和尾数的比特数,叫做解释式量化;或者仅对子带叫做导出式量化。
三、数字图像水印
水印是为了阻止图像被非法复制的一种方法,主要是将一条或多条信息项插入潜在的易受攻击的图像。他以多种的方法来保护权益,包括:(1)版权识别(2)用户识别或指纹(3)著作权认定(4)自动监视(5)复制保护
水印处理和压缩有些地方是相对的,压缩的目的是减少用于表示图像的数据量;水印处理的目的是在图像上添加信息和数据。不可见水印的一个重要特性是它抵抗偶然的和故意删除它们的企图,对于嵌入了易碎的不可见水印的图像的任何修改,都会破坏这种水印。鲁棒的不可见水印设计用于是图像能经受修改,不管攻击是有意的还是无意的。下图为一个图像水印处理系统。
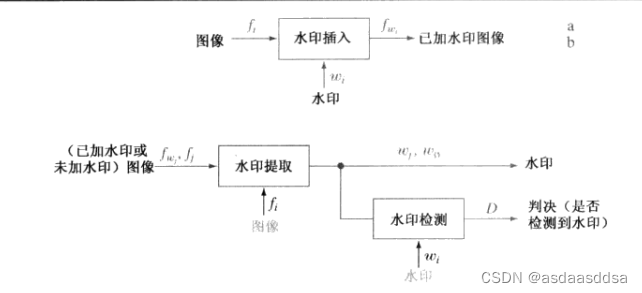
如果使用了其中的和/或
,则这个水印处理系统是已知的私钥系统或受限密钥系统;如果不用那就是公钥系统或不受限密钥系统。
基于DCT的水印处理方法可以完全抵抗水印攻击。
四、实验
添加水印代码如下:
from PIL import Image
from matplotlib import pyplot as plt
def addWatermark(input, watermark, output, position=(0.95, 0.95)):
image = Image.open(input)
watermark = Image.open(watermark)
width, height = image.size
watermark_width, watermark_height = watermark.size
left = int((width - watermark_width) * position[0])
top = int((height - watermark_height) * position[1])
plt.subplot(131), plt.imshow(image, 'gray'), plt.title('Origin'), plt.axis('off')
image.paste(watermark, (left, top), watermark)
plt.subplot(132), plt.imshow(watermark, 'gray'), plt.title('watermark'), plt.axis('off')
plt.subplot(133), plt.imshow(image, 'gray'), plt.title('result'), plt.axis('off')
plt.show()
image.save(output)
addWatermark(r'D:\test\111.jpeg', r'D:\test\222.jpeg',r'D:\test\result.png')可以得到如下的结果:

这是一个可见的数字水印的实验 。使用的是PIL库来处理图片,需要给添加水印的函数输入要添加水印图片的路径,水印图片的路径还有水印的位置,这里是(0.95,0.95)将在图片的右下角添加水印信息。代码中的left是计算其水印的横坐标,top是就算其纵坐标,然后使用paste函数将水印图片按照计算出来的横纵坐标粘贴到源图像上。最终就能得到水印的图片信息。
总结
本章主要讲解了图像压缩的一系列的方法以及数字图像水印的基本原理以及应用。首先开门见山的先为我们讲解了图像压缩一些相关的知识点,了解了图像压缩是数字图像处理中至关重要的一环,旨在减少图像数据的存储空间和传输带宽,同时保持图像的视觉质量。紧接着就是我们应当如何去实现图像压缩,以及对于常见的多种的编码方法进行了概述,并且还用许多的例子来方便我们去理解这些方法。在我们的实际应用中,可以根据具体需求选择合适的压缩方法和标准,以实现图像数据的高效存储和传输。

















 5186
5186

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









