







一.全连接层:
全连接层需要把输入拉成一个列项向量,如下图所示:
比如你的输入的feature map是2X2,那么就需要把这个feature map 拉成4X1的列向量,如果你的feature map 的channels是3,也就是你的输入是3X2X2,也就是相当于有了12个像素点,你就需要把feature map 拉成12X1的列向量,这时候,再乘一个权重,这个权重要把12个像素点都包含进去,所以这个权重的矩阵形式应该是1X12,所以经过一个全连接层后的输出就是1X12X12X1=1X1,这时候需要看你的需要多少个1X1的神经元了,如果是3个的话,那么输出就是3X(1X12X12X1)=3X(1X1).这个3在权重矩阵中代表3行,即每一行与输入相乘,得到一个输出:
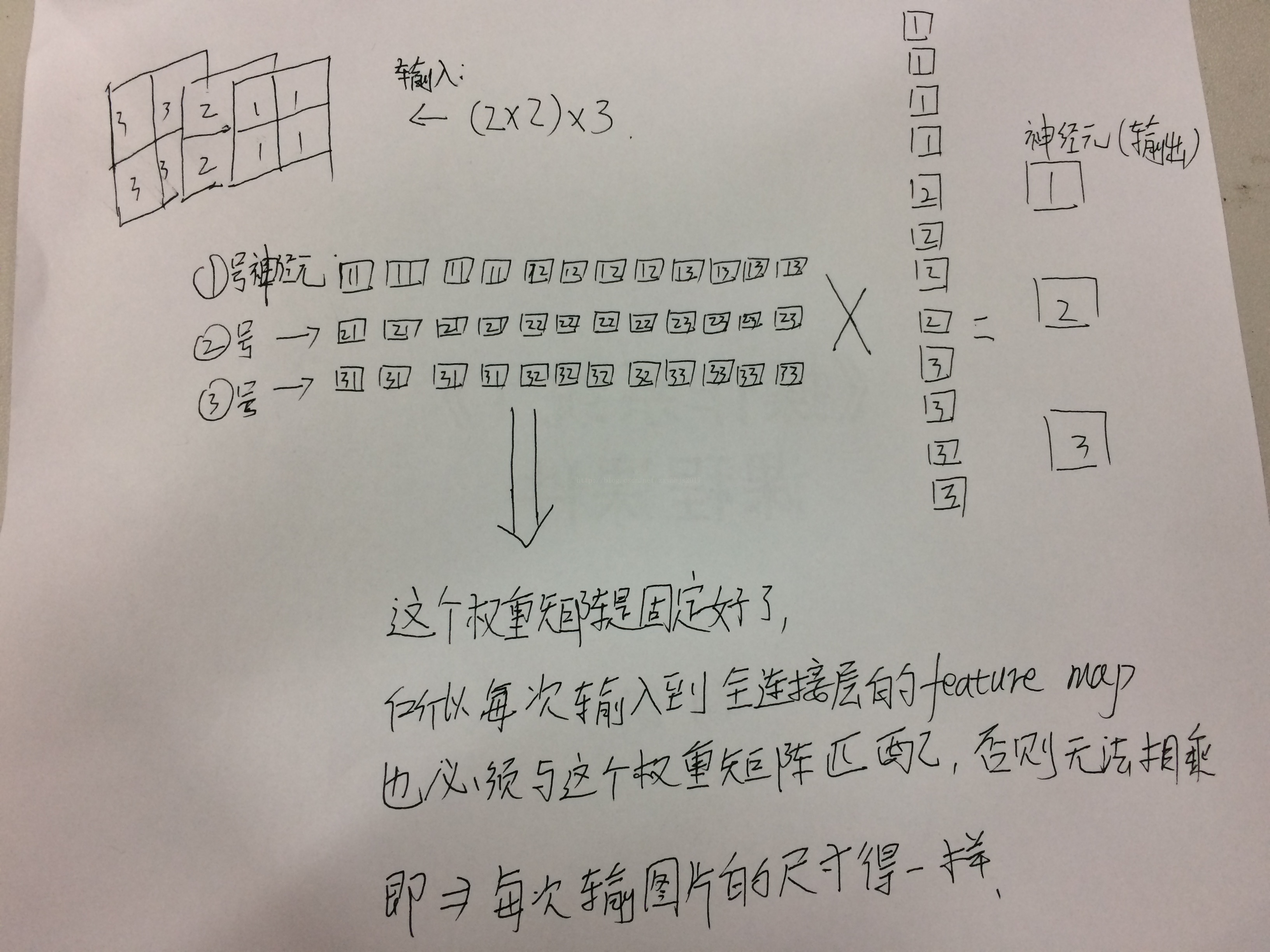
二.卷积层:转载&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 909
909

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









