






目录
序言
并行规约是一种适用于GPU平台的并行算法,主要提高求和、最值、均值、逻辑与和逻辑或等一类运算的并行度。若使用CPU计算,需要串行遍历所有元素得到上述运算的结果,但在GPU平台可以使用规约操作并行实现上述运算。
规约算法介绍
首先,表达式可表示如下:
其中res为运算结果,L为数据长度,为符合结合律的运算符,代表求和、最值、均值、逻辑与和逻辑或等。
下面以16个元素求最大值为例,说明规约算法的流程,如下图所示,其中图(a)为交错寻址规约求最大值方式,第一轮迭代完成相邻两个数的运算,并将结果原位覆盖,第二轮迭代再对第一轮计算结果执行对应的运算得到下一级的结果,此时相邻两个数的跨度翻倍,以此类推得到最终结果。图(b)为连续寻址规约求和方式,计算过程与交错寻址方式类似,该计算方式将计算复杂度由原来的O(L)降为O(logL)。需要注意的是,若在运算之前将元素存至共享内存并在每次迭代之后更新共享内存中的数据,则可以进一步提高数据存取的效率。

(a)交错寻址规约
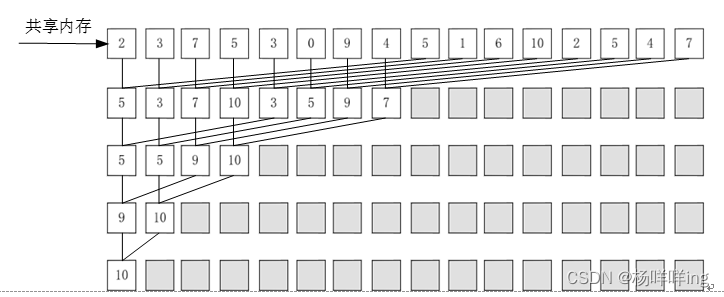
(b)连续寻址规约
GPU实现规约算法
#include <stdio.h>
#include <stdlib.h>
#define N 1000 // 数组大小
__global__ void sumArray(int *array, int *result) {
__shared__ int sdata[256];
unsigned int tid = threadIdx.x;
unsigned int idx = blockIdx.x * blockDim.x + threadIdx.x;
// 将数组元素拷贝到共享内存中
sdata[tid] = array[idx];
__syncthreads();
// 执行并行累加操作
for (unsigned int s = blockDim.x / 2; s > 0; s >>= 1) {
if (tid < s) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// 线程块的第一个线程将累加结果写回全局内存
if (tid == 0) {
result[blockIdx.x] = sdata[0];
}
}
int main() {
int array[N]; // 定义数组
int *dev_array, *dev_result; // 定义CUDA变量
int result[N / 256 + 1]; // 存储每个线程块的累加结果以及最终的总和
int finalResult = 0; // 最终的累加结果
// 在设备上分配内存
cudaMalloc((void**)&dev_array, N * sizeof(int));
cudaMalloc((void**)&dev_result, (N / 256 + 1) * sizeof(int));
// 初始化数组
for (int i = 0; i < N; i++) {
array[i] = i + 1; // 初始化数组元素为1至N
}
// 将数组拷贝到设备
cudaMemcpy(dev_array, array, N * sizeof(int), cudaMemcpyHostToDevice);
// 调用内核函数
sumArray<<<(N-1)/256+1, 256>>>(dev_array, dev_result);
// 将结果从设备拷贝回主机
cudaMemcpy(result, dev_result, (N / 256 + 1) * sizeof(int), cudaMemcpyDeviceToHost);
// 计算最终的累加结果
for (int i = 0; i < N / 256 + 1; i++) {
finalResult += result[i];
}
printf("数组元素的累加结果为: %d\n", finalResult);
// 释放设备上分配的内存
cudaFree(dev_array);
cudaFree(dev_result);
return 0;
}
核函数实现规约求和时使用了一个循环,每次循环将当前线程的数据与与其相邻的另一半线程的数据进行相加,直到最终只剩下一个元素。然后每个线程块的第一个线程(线程索引为0)将局部累加结果写回到全局内存中。最后将每个线程块的累加结果从设备拷贝回主机,并且在主机端进行最终的累加,得到整个数组元素的累加结果。















 3725
3725











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









