







.requires_grad == False
有无梯度的计算(不用计算和存储gradient,节省显存)
tensor的requires_grad 默认设置为False,若一个节点(叶子变量:自己创建的tensor)的requires_grad 被设置为True,那么所有依赖它的节点的requires_grad 都会被设置为True
设置为False的时候反向传播的时候不会自动求导了

如果只想通过loss更新model1,可以使用如下操作:
for p in net2.parameters():
p.requires_grad = False
这样不再去计算model2的网络权重w的梯度,而只使用它的值去更新model1的梯度。
.requires_grad只针对叶子结点,在网络中这个结点对应的参数不是由更上一层tensor计算得到的
with torch.no_grad()
有无梯度的计算(不用计算和存储gradient,节省显存)
在该模块下,所有计算得出的tensor的requires_grad都自动设置为False
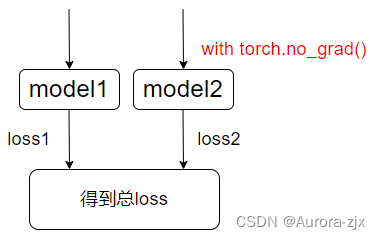
右部分的model计算得到的tensor没有grad_fn,也就是不带梯度(因为没有上一级的函数),因此loss无法从这些tensor向上传递,产生这些tensor的网络参数不会更新。也就是说只使用了model2输出来计算了loss,没有让loss去更新model2的参数,使用with torch.no_grad()使得loss被阻断在loss.backward过程中
model.eval()
有无梯度的反传
- 主要用于dropout和BN层在train和val模式之间切换
- train模式下,drpout层会按照概率p保留激活单元;BN层也会继续计算数据的mean和var等参数并进行更新
- val模式下,dropout会让所有的激活单元通过,并乘p;BN层会停止计算和更新mean和var,直接使用在训练阶段已经学到的mean和var值
- 不会影响梯度的计算,区别是train阶段有梯度的反传,而eval阶段没有
retain_graph
如果设置为False,计算图的中间变量在计算之后就会被释放(默认设置为False来提高效率)
x = torch.randn((1,4),dtype=torch.float32,requires_grad=True)
y = x ** 2
z = y * 4
loss1 = z.mean()
loss2 = z.sum()
print(loss1,loss2)
loss1.backward() # 这个代码执行正常,但是执行完中间变量都free了,所以下一个出现了问题
print(loss1,loss2)
loss2.backward() # 这时会引发错误
原因:计算节点数值保存之后,计算图x-y-z结构释放,但是loss2的backward仍然需要利用x-y-z的结构,因此报错
需要retain_graph为True去保留中间参数从而使得两个loss的反向传播不会受到影响
# 假设需要执行两次backward,先执行第一个的backward,再执行第二个backward
loss1.backward(retain_graph=True)# 这里参数表明保留backward后的中间参数。
loss2.backward() # 执行完这个后,所有中间变量都会被释放,以便下一次的循环
明保留backward后的中间参数。
loss2.backward() # 执行完这个后,所有中间变量都会被释放,以便下一次的循环














 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









