







阅读顺序:标题->摘要->引言->结论->相关工作->模型整体架构->实验
文章目录
标题 title
Masked Autoencoders Are Scalable Vision Learners
可拓展,模型比较大,是bert的一个cv版本
摘要 abstract
训练方式:随机遮盖输入图像的patch,并重建缺失的patch。有两个核心的设计:
-
首先,这是一个非对称的编码-解码器架构,一个编码器只操作于patch的可见子集(没有掩码标记),以及一个轻量级解码器,从潜在表示和掩码标记重构原始图像。
-
其次,发现掩盖高比例的输入图像,例如75%,有助于训练。
结合这两种设计能够帮助有效地训练大型模型:加速训练(3×或更多)并提高准确性。这种可扩展方法允许学习能够很好地推广的高容量模型:例如,在只使用ImageNet-1K数据的方法中,一个普通的ViT-Huge模型达到了最好的精度(87.8%)。在下游任务中的转移性能优于监督预训练,并表现出良好的缩放行为。
引言 introduction
什么使得掩码自编码器在cv和NLP领域不同?
- 将mask tokens和位置编码插入到卷积网络中不易,但是随着ViT的引入,这一gap得到了解决
- 语言和视觉的信息密度:预测一个句子中缺失的单词复杂,但是图像含有大量空间冗余的信息,甚至一个缺失的patch可以从相邻的patch中恢复,为了解决这个gap并引导学习有用特征,采用屏蔽大量的patch这一简单的策略
- decoder:cv中重建的是像素,语义级别低;NLP中预测包含丰富语义信息的缺失单词,在bert中解码器可以是一个简单的MLP
MAE可以学习非常高容量的模型,并泛化得很好。通过MAE预训练,我们可以在ImageNet-1K上训练像ViT-Large/-Huge这样的数据饥饿模型,从而提高泛化性能。使用一个普通的ViT-Huge模型,当我们在ImageNet-1K上进行fintune时,达到了87.8%的精度。这优于之前所有只使用ImageNet-1K数据的结果。
此外,还评估了迁移学习的目标检测,实例分割,和语义分割。在这些任务中,我们的预训练比有监督的预训练取得了更好的结果。
结论 conclusion
在自然语言处理中,简单的自监督学习方法可以从指数尺度模型中获益。在这项研究中发现,一个类似于NLP的简单自监督方法提供了可伸缩的优势。
随机删除patch而不是对象实体,从MAE可以重建出复杂的结果表明他已经学到了许多语义信息,因此可以应用于下游任务。
在NLP领域自监督学习很火,但是在cv领域,有标号的预训练是主流,MAE在ImageNet数据集上,通过自编码器学习就可以媲美有标号的结果。
相关工作 related work
- Masked language modeling and its autoregressive counterparts如BERT、GPT这些预训练好的representation可以很好地应用到各种下游任务
- Autoencoding自动编码是学习表示法的一种经典方法。它有一个编码器,将输入映射到潜在表示,和一个重构输入的解码器。例如,PCA和k-means是自动编码器。去噪自动编码器(DAE)也是一类自动编码器
- Masked image encoding屏蔽图像编码方法从被屏蔽破坏的图像中学习表示。DAE的开创性工作将掩蔽作为DAE中的一种噪声类型。context encoder使用卷积网络来绘制大的缺失区域。由于NLP的成功,最近的相关方法是基于transformer。iGPT 处理像素序列并预测未知像素。ViT论文研究了自监督学习中的掩码补丁预测。最近,BEiT提出预测离散tokens。
MAE模型架构 model
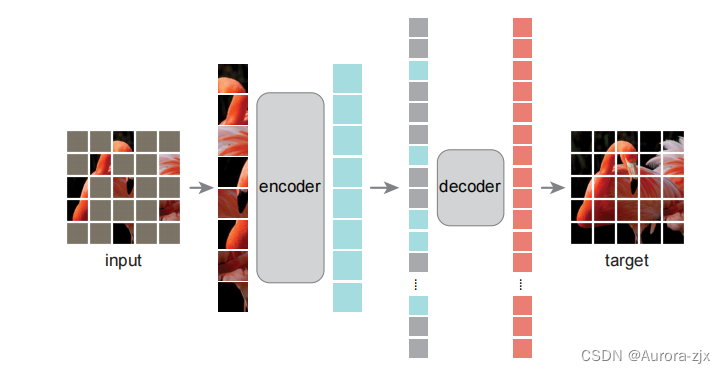
和经典自动编码器不同的是,采用一种非对称的设计,encoder只操作部分patch(没有mask tokens),以及一个轻量级的decoder,从潜在的表示和mask tokens中重构完整的信息
具体实现:参考link

MAE的编码器
使用一个ViT,只作用于可见块
和ViT一样,每一个patch提取出来,做一个线性投影+位置信息->token
MAE的解码器
通过一个共享的可以学习到的向量来表示each mask token,每一个被盖住的块都表示为同样一个向量,此向量可以学习
解码器是另一个transformer,需要位置信息,不然无法区分对应哪一个mask tokens
在预训练时对预测像素做一次normalization,使得像素均值为0方差为1,数值更稳定,在预测的时候,可使用预训练有标号的样本的均值方差
实验 experiments
ImageNet 的实验
在 ImageNet-1K 100万张图片 数据集上,先做自监督的预训练(不用标号,只拿图片),然后再在同样的数据集上做有标号的监督训练
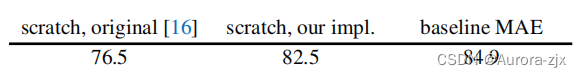
scratch, original: 76.5, ViT 所有的内容在 ImageNet-1K上训练
scratch, our impl.: 82.5 加入 strong regularization
baseline MAE: 84.9 先使用 MAE 做预训练,再在 ImageNet 上微调 50 epoches
ablation study
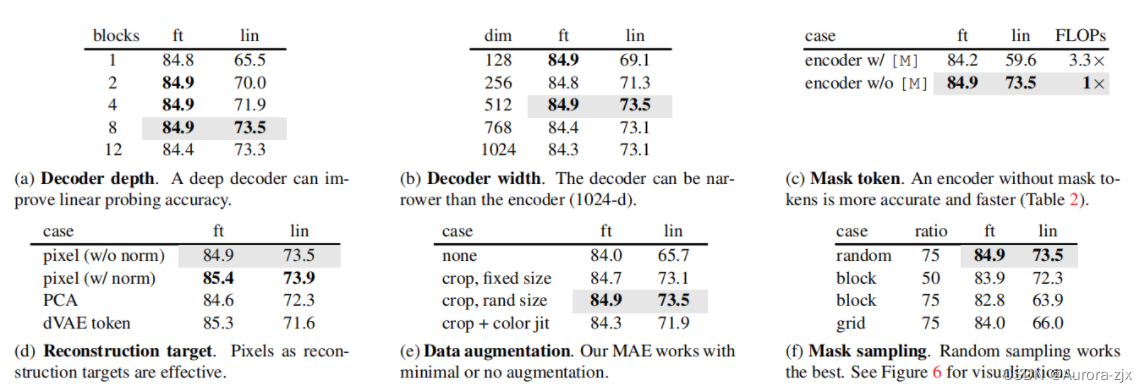
- 解码器的深度
全部ft,深度和效果关系不大;对于lin 深度深一些好
- 解码器的宽度
每一个token表示成长为512的向量效果比较好
- 编码器要不要加入被盖住的masked块
不加的话精度高,计算量少,非对称的架构,精度高,性能好
- 重构的目标
每个像素的MSE
每个像素的MSE+normalization 均值为0方差为1效果好
PCA做一次降维
dVAE: BEiT 的做法,通过 ViT 把每一个块映射到一个离散的 token,像 BERT 一样的去做预测
- 如何去做数据增强
什么都不做
固定大小的裁剪
随机大小的裁剪
裁剪 + 颜色变化
MAE 对数据增强不敏感
- 怎么采样被盖住的块
随机采样 最简单最好
按一块块的采样 50 %
按一块块的采样 75 %
网格采样
其他实验
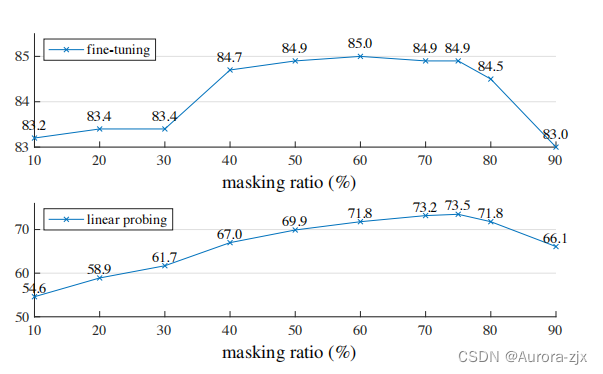
- 不同掩码率
- 训练时间

ViT-Large + 解码器只使用一层 Transformer 的块:84.8% 精度不错,耗时最少
带掩码的块 + 大的解码器,加速 3.7倍
ViT huge 加速也比较多
- 训练策略
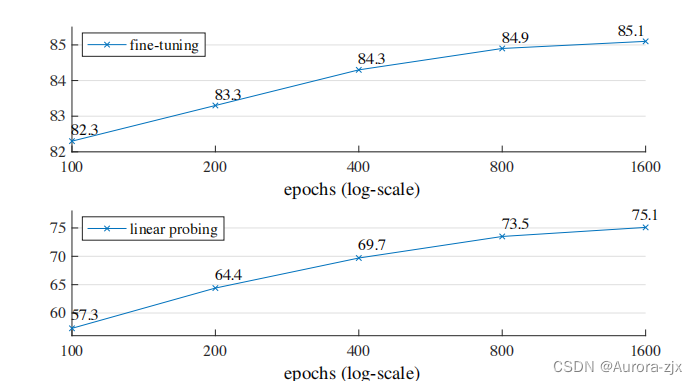
不同 training epochs 的影响:在 training epochs=1600 时 MAE 还没有达到饱和。
- 结果对比

- partial ft
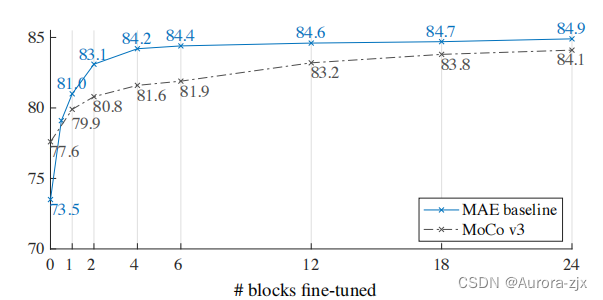
只训练最后模型的若干层的参数















 2418
2418











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









