







【论文阅读】Formal Verification of Intelligent Hybrid Systems that are Modeled with Simulink and the Reinforcement Learning Toolbox
FM 2021: Formal Methods pp 349-366

同一批作者另一篇发表在International Conference on Formal Engineering Methods
ICFEM 2018
文章目录
摘要
强化学习(RL)是一种在动态和不确定环境下控制自主混合系统(HSs)的强大技术,但很难保证其在安全关键应用中的正确行为。为了正式保证安全行为,需要一个形式化系统描述,这在工业设计过程中通常是不可用的,而且在RL的不可预测、试错学习过程中难以获得。
本文提出了一种在 Simulink 中与 RL Toolbox 一起建模的具有嵌入式 RL 组件的智能 HS 的半自动演绎验证方法。
关键思想:
- 首先,以差分动态逻辑的方式捕获具有混合契约的RL组件的安全相关行为。
- 其次,利用交互定理证明器KeYmaeraX演绎地验证了被RL组件取代的整个系统的安全特性。为了使这成为可能,通过将现有的从 Simulink 转换扩展到差分动态逻辑以支持 RL 组件来精确捕获工业设计的智能 HS 的语义。
- 第三,通过从混合合约中自动派生运行时监视器(automatically deriving runtime monitors from our hybrid contracts.) 来确保合约在运行时得到遵守。 通过在工厂环境中验证自主智能机器人的碰撞自由来证明方法的实际适用性、可扩展性和灵活性。
背景
混成系统:混合系统(HSs)结合了离散的和连续的行为。在工业中已经广泛使用MATLAB Simulink来对HS进行建模,以处理它的复杂性。
强化学习:RL是一类机器学习技术,其中代理通过与环境的交互获得经验来学习行为策略。它允许学习适应性强的智能控制器,通常能够优于手动设计的控制器。然而,RL组件通常在试错方法中学习,因此它们本身是不安全的组件,这与HSs的安全关键特性相矛盾。 虽然有一些安全的带RL组件的方法,但它们在工业上都是不可用的。而且工业上使用的建模语言,如simulink和RL toolbox,也没有正式定义的语义。目前有一些方法可以克服这个问题,但它们不考虑RL。
而本文的目的就是用simulink及其RLtoolbox建模的智能混成系统。
预备知识
强化学习
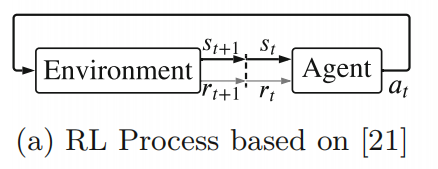
强化学习是一类机器学习方法,通过动作[21]与环境交互,以试错方法进行学习。大多数RL算法的数学基础是马尔可夫决策过程(MDPs)
Simulink & the RL Toolbox
Simulink 是一种工业上完善的 HS 图形建模语言。 Simulink 模型由通过信号线连接的模块组成。 信号可以携带离散值或连续值。 Simulink 模块库提供了大量预定义模块,范围从控制流模块的算术到积分器和复杂的转换。 与 MATLAB 库一起,可以对线性和非线性微分方程进行建模和仿真。 Simulink 模型可以通过定义工作区变量来参数化。

RL toolbox 提供了一个 RL 代理块,它可以执行预定义或用户定义的 RL 算法。 RL 主体在离散采样时间内起作用。 它将观察 st、奖励 rt 和一个标志 isdone 作为输入,并产生由 RL 算法选择的动作,如图 b 所示。

 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3244
3244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









