









From: https://github.com/L1aoXingyu/code-of-learn-deep-learning-with-pytorch
mnist 数据集是一个非常出名的数据集,基本上很多网络都将其作为一个测试的标准,其来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST)。 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员,一共有 60000 张图片。 测试集(test set) 也是同样比例的手写数字数据,一共有 10000 张图片。
每张图片大小是 28 x 28 的灰度图,所以我们的任务就是给出一张图片,我们希望区别出其到底属于 0 到 9 这 10 个数字中的哪一个。
数据集
train_set = mnist.MNIST('data/mnist_data/', train=True, download=True)
test_set = mnist.MNIST('data/mnist_data/', train=False, download=True)
one_pic, one_label = train_set[0]
print(one_label)
one_pic
one_data = np.array(one_pic, dtype='float32')
one_data.shape # (28, 28)
重载数据,转换格式
对于神经网络,我们第一层的输入就是 28 x 28 = 784,所以必须将得到的数据我们做一个变换,使用 reshape 将他们拉平成一个一维向量
def data_tf(x):
x = np.array(x, dtype='float32')
x = (x - 0.5) / 0.5 # 标准化
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = mnist.MNIST('data/mnist_data/', train=True, transform=data_tf, download=True)
test_set = mnist.MNIST('data/mnist_data/', train=False, transform=data_tf, download=True)
数据迭代器
使用这样的数据迭代器是非常有必要的,如果数据量太大,就无法一次将他们全部读入内存,所以需要使用 python 迭代器,每次生成一个批次的数据
from torch.utils.data import DataLoader
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)
one_df, one_df_label = next(iter(train_data))
print(one_df.shape)
print(one_df_label)
torch.Size([64, 784])
tensor([8, 5, 8, 0, 1, 6, 8, 6, 4, 1, 9, 9, 7, 6, 5, 9, 6, 3, 1, 9, 0, 1, 8, 6,
8, 4, 2, 2, 4, 1, 2, 0, 1, 9, 7, 1, 8, 2, 0, 3, 2, 6, 7, 6, 4, 0, 9, 5,
2, 6, 4, 5, 3, 2, 7, 0, 2, 0, 1, 9, 3, 6, 0, 6])
Sequence 定义网络
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = mnist.MNIST('./data/mnist_data/', train=True, transform=data_tf, download=True)
test_set = mnist.MNIST('./data/mnist_data/', train=False, transform=data_tf, download=True)
# 使用 pytorch 自带的 DataLoader 定义一个数据迭代器
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)
net = nn.Sequential(
nn.Linear(784, 400),
nn.ReLU(),
nn.Linear(400, 100),
nn.ReLU(),
nn.Linear(100, 10)
)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(net.parameters(), 1e-1)
losses = []
acces = []
eval_losses = []
eval_acces = []
for i in range(20):
train_loss = 0
train_acc = 0
net.train()
# 训练
for im, label in train_data:
# 每次循环, 取一个批次(64)的图片
im = Variable(im)
label = Variable(label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
_, predict = out.max(1)
num_correct = (predict == label).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
losses.append(train_loss / len(train_data))
acces.append(train_acc / len(train_data))
# 测试集上验证效果
eval_loss = 0
eval_acc = 0
net.eval() # 将模型改为预测模型
for im, label in test_data:
# 每次循环, 取一个批次(128)的图片
im = Variable(im)
label = Variable(label)
out = net(im)
# 误差
loss = criterion(out, label)
eval_loss += loss.item()
# 准确率
_, predict = out.max(1)
num_correct = (predict == label).sum().item()
acc = num_correct / im.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch:{}, train loss:{:.6f}, train acc:{:.6f}, eval loss:{:.6f}, eval acc:{:.6f}'
.format(i, train_loss/len(train_data), train_acc/len(train_data),
eval_loss/len(test_data), eval_acc/len(test_data)))
epoch:0, train loss:0.422101, train acc:0.864389, eval loss:0.194471, eval acc:0.936907
epoch:1, train loss:0.158420, train acc:0.951176, eval loss:0.272349, eval acc:0.906250
epoch:2, train loss:0.110557, train acc:0.965552, eval loss:0.095524, eval acc:0.970530
epoch:3, train loss:0.087599, train acc:0.973398, eval loss:0.093888, eval acc:0.971519
epoch:4, train loss:0.070228, train acc:0.978178, eval loss:0.085099, eval acc:0.974980
epoch:5, train loss:0.060921, train acc:0.980377, eval loss:0.180690, eval acc:0.946301
epoch:6, train loss:0.051192, train acc:0.983809, eval loss:0.067430, eval acc:0.977156
epoch:7, train loss:0.043570, train acc:0.985941, eval loss:0.251171, eval acc:0.934335
epoch:8, train loss:0.038641, train acc:0.987390, eval loss:0.063761, eval acc:0.979925
epoch:9, train loss:0.032362, train acc:0.989606, eval loss:0.070411, eval acc:0.979430
epoch:10, train loss:0.028192, train acc:0.991021, eval loss:0.077044, eval acc:0.975376
epoch:11, train loss:0.024043, train acc:0.992104, eval loss:0.067841, eval acc:0.978145
epoch:12, train loss:0.020144, train acc:0.993637, eval loss:0.070436, eval acc:0.978046
epoch:13, train loss:0.016769, train acc:0.994636, eval loss:0.057463, eval acc:0.983287
module 定义网络
class model(nn.Module):
def __init__(self, num_in, num_hidden1, num_hidden2, num_out):
super(model, self).__init__()
self.layer1 = nn.Linear(num_in, num_hidden1)
self.layer2 = nn.ReLU()
self.layer3 = nn.Linear(num_hidden1, num_hidden2)
self.layer4 = nn.ReLU()
self.layer5 = nn.Linear(num_hidden2, num_out)
def forward(self, x):
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
return x
def data_tf(x):
x = np.array(x, dtype='float32') / 255
x = (x - 0.5) / 0.5 # 标准化,这个技巧之后会讲到
x = x.reshape((-1,)) # 拉平
x = torch.from_numpy(x)
return x
train_set = mnist.MNIST('./data/mnist_data/', train=True, transform=data_tf, download=True)
test_set = mnist.MNIST('./data/mnist_data/', train=False, transform=data_tf, download=True)
# 使用 pytorch 自带的 DataLoader 定义一个数据迭代器
train_data = DataLoader(train_set, batch_size=64, shuffle=True)
test_data = DataLoader(test_set, batch_size=128, shuffle=False)
model1 = model(784, 400, 100, 10)
optimizer = torch.optim.SGD(model1.parameters(), 1e-1)
criterion = nn.CrossEntropyLoss()
losses = []
acces = []
eval_losses = []
eval_acces = []
for i in range(20):
train_loss = 0
train_acc = 0
model1.train()
# 训练
for im, label in train_data:
# 每次循环, 取一个批次(64)的图片
im = Variable(im)
label = Variable(label)
# 前向传播
out = model1(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 记录误差
train_loss += loss.item()
_, predict = out.max(1)
num_correct = (predict == label).sum().item()
acc = num_correct / im.shape[0]
train_acc += acc
losses.append(train_loss / len(train_data))
acces.append(train_acc / len(train_data))
# 测试集上验证效果
eval_loss = 0
eval_acc = 0
model1.eval() # 将模型改为预测模型
for im, label in test_data:
# 每次循环, 取一个批次(128)的图片
im = Variable(im)
label = Variable(label)
out = model1(im)
# 误差
loss = criterion(out, label)
eval_loss += loss.item()
# 准确率
_, predict = out.max(1)
num_correct = (predict == label).sum().item()
acc = num_correct / im.shape[0]
eval_acc += acc
eval_losses.append(eval_loss / len(test_data))
eval_acces.append(eval_acc / len(test_data))
print('epoch:{}, train loss:{:.6f}, train acc:{:.6f}, eval loss:{:.6f}, eval acc:{:.6f}'
.format(i, train_loss/len(train_data), train_acc/len(train_data),
eval_loss/len(test_data), eval_acc/len(test_data)))
epoch:0, train loss:0.426959, train acc:0.865822, eval loss:0.197170, eval acc:0.940071
epoch:1, train loss:0.158264, train acc:0.951926, eval loss:0.156362, eval acc:0.950158
epoch:2, train loss:0.112939, train acc:0.964969, eval loss:0.094992, eval acc:0.970332
epoch:3, train loss:0.086615, train acc:0.971915, eval loss:0.099875, eval acc:0.969541
epoch:4, train loss:0.070733, train acc:0.977129, eval loss:0.098983, eval acc:0.969640
epoch:5, train loss:0.061764, train acc:0.980560, eval loss:0.105964, eval acc:0.965487
epoch:6, train loss:0.051666, train acc:0.983276, eval loss:0.213732, eval acc:0.942346
epoch:7, train loss:0.045266, train acc:0.985108, eval loss:0.075728, eval acc:0.976661
epoch:8, train loss:0.037531, train acc:0.987507, eval loss:0.114805, eval acc:0.961432
epoch:9, train loss:0.030402, train acc:0.990438, eval loss:0.068435, eval acc:0.979134
epoch:10, train loss:0.028149, train acc:0.991105, eval loss:0.062838, eval acc:0.980815
epoch:11, train loss:0.024067, train acc:0.992271, eval loss:0.065962, eval acc:0.981309
epoch:12, train loss:0.019952, train acc:0.993853, eval loss:0.065837, eval acc:0.980815
epoch:13, train loss:0.017938, train acc:0.994803, eval loss:0.079923, eval acc:0.976068
epoch:14, train loss:0.015751, train acc:0.995502, eval loss:0.111906, eval acc:0.970728
epoch:15, train loss:0.013665, train acc:0.995469, eval loss:0.073133, eval acc:0.979035
epoch:16, train loss:0.012365, train acc:0.996219, eval loss:0.068478, eval acc:0.979628
epoch:17, train loss:0.009216, train acc:0.997418, eval loss:0.071945, eval acc:0.981013
epoch:18, train loss:0.007811, train acc:0.997884, eval loss:0.062639, eval acc:0.984276
epoch:19, train loss:0.005954, train acc:0.998484, eval loss:0.067063, eval acc:0.983683
结果可视化
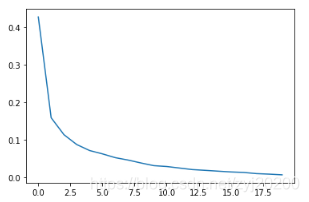
plt.title('train loss')
plt.plot(np.arange(len(losses)), losses)
plt.show()
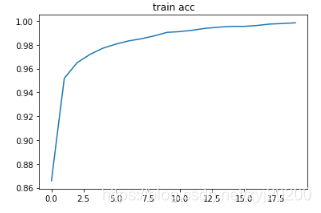
plt.title('train acc')
plt.plot(np.arange(len(acces)), acces)
plt.show()
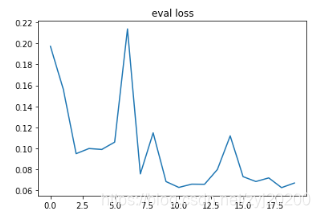
plt.title('eval loss')
plt.plot(np.arange(len(eval_losses)), eval_losses)
plt.show()
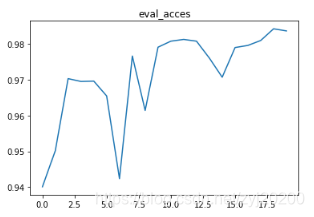
plt.title('eval_acces')
plt.plot(np.arange(len(eval_acces)), eval_acces)
plt.show()
参数初始化
参数初始化对模型具有较大的影响,不同的初始化方式可能会导致截然不同的结果,所幸的是很多深度学习的先驱们已经帮我们探索了各种各样的初始化方式,所以我们只需要学会如何对模型的参数进行初始化的赋值即可。
PyTorch 的初始化方式并没有那么显然,如果你使用最原始的方式创建模型,那么你需要定义模型中的所有参数,当然这样你可以非常方便地定义每个变量的初始化方式,但是对于复杂的模型,这并不容易,而且我们推崇使用 Sequential 和 Module 来定义模型,所以这个时候我们就需要知道如何来自定义初始化方式
使用 NumPy 来初始化
Sequential模型
net1 = nn.Sequential(
nn.Linear(30, 40),
nn.ReLU(),
nn.Linear(40, 50),
nn.ReLU(),
nn.Linear(50, 10)
)
w1 = net1[0].weight
b1 = net1[0].bias
print(net1[0])
print(w1.shape)
print(w1)
print(b1.shape)
print(b1)
Linear(in_features=30, out_features=40, bias=True)
torch.Size([40, 30])
Parameter containing:
tensor([[-0.0235, 0.1183, 0.1749, ..., -0.1638, 0.1608, 0.1609],
[ 0.0688, 0.1802, -0.1818, ..., 0.0555, 0.0050, 0.0386],
[-0.0152, -0.0888, 0.0830, ..., -0.1556, -0.0245, -0.0396],
...,
[ 0.1619, -0.1301, 0.0987, ..., -0.1299, -0.0752, -0.0538],
[ 0.0750, 0.1513, 0.0934, ..., -0.0019, 0.0671, -0.0333],
[-0.0121, 0.0352, -0.1181, ..., 0.1601, -0.1795, 0.1320]],
requires_grad=True)
torch.Size([40])
Parameter containing:
tensor([ 0.0892, -0.1112, 0.0690, 0.0494, 0.1187, -0.0833, 0.1485, 0.1562,
-0.1198, 0.0005, -0.1179, 0.0847, -0.0495, -0.0913, -0.0533, -0.1464,
0.1049, 0.0807, 0.0900, -0.1809, -0.1443, -0.0045, -0.0992, -0.1727,
-0.0748, -0.0285, 0.0682, 0.0618, 0.0276, -0.0468, -0.1417, -0.0941,
-0.0914, -0.1210, -0.1790, -0.1400, -0.1147, -0.0196, 0.1591, 0.1472],
这是一个 Parameter,也就是一个特殊的 Variable,我们可以访问其 .data属性得到其中的数据,然后直接定义一个新的 Tensor 对其进行替换
net1[0].weight.data = torch.from_numpy(np.random.uniform(3, 5, size=(40, 30)))
使用循环, 修改所有的默认参数
for layer in net1:
if isinstance(layer, nn.Linear): #判断是否为线性模型
param_shape = layer.weight.shape
# 定义均值为0, 方差为0.5的正态分布
layer.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape))
Module 模型
children, modules 属性
children 只会访问到模型定义中的第一层,因为上面的模型中定义了三个 Sequential,所以只会访问到三个 Sequential,而 modules 会访问到最后的结构,比如上面的例子,modules 不仅访问到了 Sequential,也访问到了 Sequential 里面
class sim_net(nn.Module):
def __init__(self):
super(sim_net, self).__init__()
self.l1 = nn.Sequential(
nn.Linear(30, 40),
nn.ReLU()
)
self.l2 = nn.Sequential(
nn.Linear(40, 50),
nn.ReLU()
)
self.l3 = nn.Sequential(
nn.Linear(50, 10),
nn.ReLU()
)
def forward(self, x):
x = self.l1(x)
x = self.l2(x)
x = self.l3(x)
return x
net2 = sim_net()
for i in net2.children():
print(i)
for i in net2.modules():
print(i)
Sequential(
(0): Linear(in_features=30, out_features=40, bias=True)
(1): ReLU()
)
Sequential(
(0): Linear(in_features=40, out_features=50, bias=True)
(1): ReLU()
)
Sequential(
(0): Linear(in_features=50, out_features=10, bias=True)
(1): ReLU()
)
-----------------------------------------------------------------
sim_net(
(l1): Sequential(
(0): Linear(in_features=30, out_features=40, bias=True)
(1): ReLU()
)
(l2): Sequential(
(0): Linear(in_features=40, out_features=50, bias=True)
(1): ReLU()
)
(l3): Sequential(
(0): Linear(in_features=50, out_features=10, bias=True)
(1): ReLU()
)
)
Sequential(
(0): Linear(in_features=30, out_features=40, bias=True)
(1): ReLU()
)
Linear(in_features=30, out_features=40, bias=True)
ReLU()
Sequential(
(0): Linear(in_features=40, out_features=50, bias=True)
(1): ReLU()
)
Linear(in_features=40, out_features=50, bias=True)
ReLU()
Sequential(
(0): Linear(in_features=50, out_features=10, bias=True)
(1): ReLU()
)
Linear(in_features=50, out_features=10, bias=True)
ReLU()
参数初始化
for layer in net2.modules():
if isinstance(layer, nn.Linear):
param_shape = layer.weight.shape
layer.weight.data = torch.from_numpy(np.random.normal(0, 0.5, size=param_shape))
torch.nn.init 初始化参数
Sequential
for layer in net1:
if isinstance(layer, nn.Linear):
init.xavier_uniform_(layer.weight)
Module
for layer in net2.modules():
if isinstance(layer, nn.Linear):
init.xavier_uniform_(layer.weight)














 1837
1837











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









