







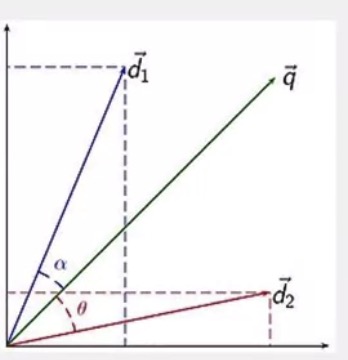
Document similarity
- Used in IR to determine which document(d1 or d2) is more similar to a given query q(the documents and queries are in the same space)
- The angle, or the cosine of the angle is used as a proxy of the similarity of the underlying documents
Cosine similarity
σ(D,Q)=(D,Q)∣D∣∣Q∣
A variant:Jaccard coeffecient
σ(D,Q)=∣D∩Q∣∣D∪Q∣
Example
- D = “cat, dog, dog” = <1,2,0>
Q = “cat, dog, mouse, mouse” = <1,1,2>
similarity
σ(D,Q)=1×2+2×1+0×212+22+02‾‾‾‾‾‾‾‾‾‾‾‾√12+12+22‾‾‾‾‾‾‾‾‾‾‾‾√=330‾‾‾√≈0.55
Distributional similarity
- Two words that appear in similar contexts are likely to be semantically related
You will know the word by the company that it keeps.
















 2704
2704

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









