







Problems with the simple vector approaches to similarity

Dimensionality reduction
- looking for hidden similarities in data
- based on matrix decomposition
Matrix decomposition

SVD

Example
Assume that we have 7 Documents with 9 terms.
e.g. Document 1 contains term 6 and term9.The document term matrix should be ℝ9×7 , a column represents a document and a raw represents a term.

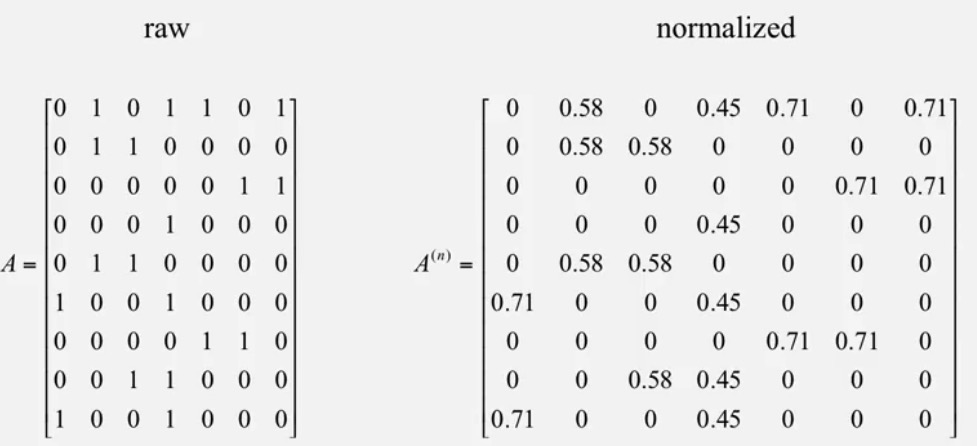
Remark: we have to normalize our matrix before svd.
Apply the svd decomposition
M9×7=U9×9Σ9×7VTΣ
Rank 2 Σ
UΣ2 is the 2 rank approximation of the TERM(2 dimension),
Σ2VT is the 2 rank approximation of the DOCUMENT(2 dimension).



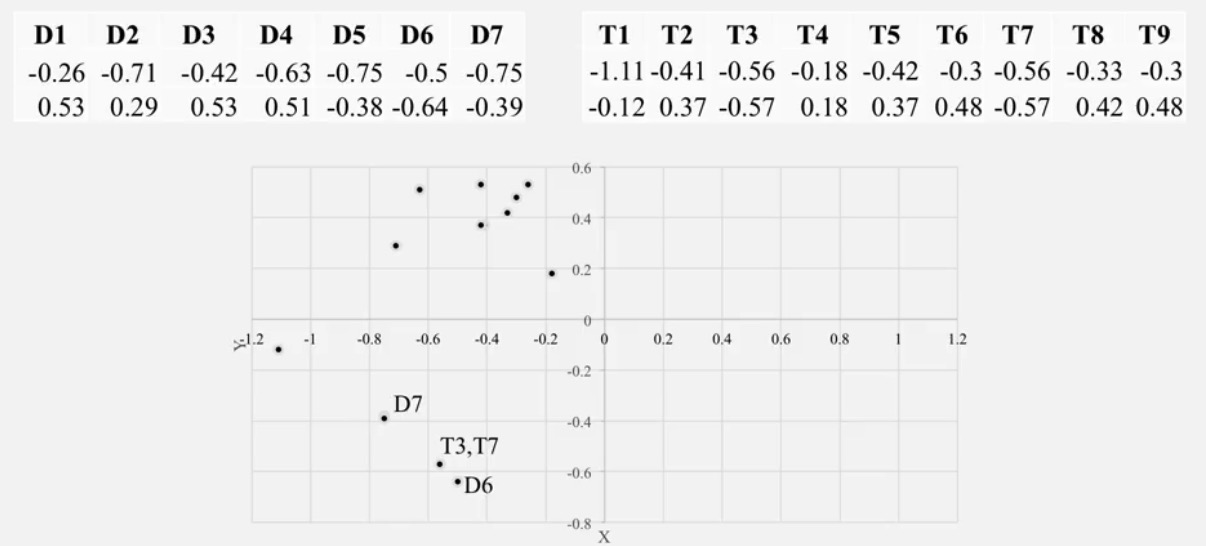
Question
what do ATA and AAT mean if A is a document-term matrix ℝ9×7 ?
- ATA∈ℝ7×7 is the document-document similarity matrix.
- AAT∈ℝ9×9 is the term-term similarity matrix.
Latent semantic indexing(LSI, identical to LSA)
- Dimensionality reduction = identification of hidden(latent) concepts
- query matching in latent space















 3510
3510

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









