







文章目录
1. Mandelbrot & Julia Set 介绍
Mandelbrot 集合以其发现者数学家 Benoit Mandelbrot命名,它是一个分形集合。在数学中,分形是欧几里得空间的一个子集,它的 Hausdorff 维严格超过了拓扑维数。分形倾向于在不同的层次上保持它们的形式,这导致它们在大自然中无处不在。分形被称为自相似的,这意味着它们在越来越小的尺度上表现出类似的模式,并且与它的一个或多个部分相似。分形的图像通常是由计算机生成的彩色复杂的图案,因为分形是由复数组成的集合,需要一个公式来计算分形集合中的数字。生成了曼德尔勃特集合通过使用复杂的二次多项式C 是一个复杂的参数,从 z = 0 迭代产生的序列值将逐渐发散到正无穷或递归地收敛于一个点根据方程。使用不同的迭代数可以生成不同的函数值。
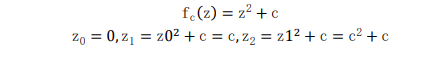
由于每个点的计算都是独立于其他点的,因此生成 Mandelbrot 集合非常适合并行计算。并行计算是一种使用多个计算资源并发地解决一个问题的过程。换句话说,它是一种提高计算机处理能力和速度的有效方法。消息传递接口(MPI)是一种实用、灵活和高效的标准,用于基于消息传递生成并行程序。Mandelbrot 集的并行化是通过利用 C 编程中的 MPI 库实现的。采用基于轮循行分割的分区方案将行划分为子行,并为子行分配不同的逻辑处理器,以提高子行计算效率。分析结果然后绘制图,观察算法在逻辑处理器数量增加时的可伸缩性。
2. 初步分析
2.1 Mandelbrot 集的理论并行性
检 测 序 列 算 法并 行 性的 一 个 可 靠 方法 是 找出 该 算 法 的 方程 是 否可 以 相 互 独立执行。在这里可以使用伯恩斯坦条件(因为可以在不修改程序结果的情况下交换)。构成伯恩斯坦条件构成的三个条件如下: 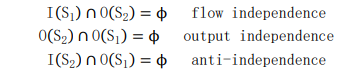
这表明 S1 和 S2 可以并行地相等, 这些条件以不同的粒度表现出来。只要满足这三个条件,就可以得出过程相互独立的结论,证明其具有极大的并行性。
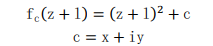
上式表示 Mandelbrot 集合的两个连续值的函数计算。因此,
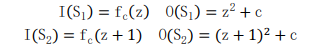
然后应用 Bernstein 条件得到以下三个方程:
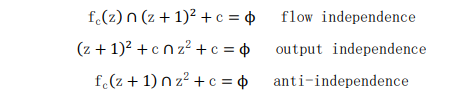
上述方程表明了伯恩斯坦条件的证明。因此,进程 S1 和 S2 都可以并行执行,即(S1 || S2)。因此,通过证明和证据表明,Mandelbrot 集合在 C 编程中是可使用 MPI 库来进行并行计算的。同理,Julia 集合也具有这种可并行性,在此不与赘述。
2.2 Mandelbrot 集和 Julia 集的运行逻辑
Mandelbrot 集的伪代码如下:
for each pixel (Px, Py) on the screen do
x0 := scaled x coordinate of pixel (scaled to lie in the Mandelbrot
X scale (-2.00, 0.47))
y0 := scaled y coordinate of pixel (scaled to lie in the Mandelbrot
Y scale (-1.12, 1.12))
x := 0.0
y := 0.0
iteration := 0
max_iteration := 1000
while (x*x + y*y ≤ 2*2 AND iteration < max_iteration) do
xtemp := x*x - y*y + x0
y := 2*x*y + y0
x := xtemp
iteration := iteration + 1
color := palette[iteration]
plot(Px, Py, color)
Julia 集的伪代码如下:
R = escape radius # choose R > 0 such that R**2 - R >= sqrt(cx**2 +
cy**2)
for each pixel (x, y) on the screen, do:
{
zx = scaled x coordinate of pixel # (scale to be between -R and
R)
# zx represents the real part of z.
zy = scaled y coordinate of pixel # (scale to be between -R and
R)
# zy represents the imaginary part of z.
iteration = 0
max_iteration = 1000
while (zx * zx + zy * zy < R**2 AND iteration < max_iteration)
{
xtemp = zx * zx - zy * zy
zy = 2 * zx * zy + cy
zx = xtemp + cx
iteration = iteration + 1
}
if (iteration == max_iteration)
return black;
else
return iteration;
}
2.3 探究参数C对 Julia 集的形状的影响
Julia Set 集是 z = z^2+c 迭代生成的图形,固定 c,然后计算发散的 z 的值,得到发散的数列。通过改变复数 c 的值,然后进行迭代,可以生成不同的 Julia 图形。下面的实验主要探究 c 值对 Julia Set 形状的影响,共设计了 7 组实验,每组实验有不同的 c.re和 c.im,分别代表复数 c 的实部和虚部。每组实验设有 3 次实验,从左到右不断的加大迭代的次数,可以观察出迭代的次数越多,得到的分形图案越精细。



3. 分区方案设计
为了并行化顺序算法,我们需要寻找可以彼此独立执行的操作,这就是利用Bernstein 's Conditions 的地方。从 2.2 节 Mandelbrot 集和 Julia 集的运行伪代码可以看出,其中运算量主要集中在 for 循环的迭代上,而每一迭代过程是相互独立的,即可以并行计算。因此可以考虑在多核计算机上使用分区方案并行运行。
3.1 基于轮询行分段的分区方案
在这个方案中,根节点成为主节点并行执行接收和写入操作,同时给所有可用的逻辑处理器提供等量的工作来收集和发送到主节点以生成 Mandelbrot Set。其中每个进程分配的行数为图片像素矩阵的最大行数除以进程数。其数学表达式如下:

在分割完所有行之后,每个进程将它们分别计算生成的子行发送回根节点,在从所有处理器接收到所有子行之后,主节点最终将遵守算法的 Mandelbrot Set映像写入.ppm 文件。

3.2 基于 MPI 的并行计算
基于上述的分区策略,mandelbrot 的计算可以分配到一系列完整独立的任务各自执行,每个节点对应一个任务,即计算其所分配到的行像素的值。采用 MPI 的编程思想进行程序设计,可以按照 master 负责 assign 任务和收集任务,而其他的 slave process 是通过拿到 data partition,对对应的计算工作进行相关操作。其主程序代码的流程图如下:

4. 图形美化设计
4.1 着色方案
一张图像可以看作是像素点构成的矩阵,矩阵上每个值是 rgb,反应了该像素点的颜色状态。 因此可以将 Mandelbrot Set 和 Julia Set 中每个点的发散速度映射到一个 rgb 值,因此可以对 Mandelbrot 和 Julia 序列进行可视化的展示,其上色的结果分别如下:

4.2 其他方案
Mandelbrot 集在 z=0 时不断的迭代 c 得到的,因此只能得到一种葫芦状的图片。但是可以对图片进行缩放,平移,增大迭代次数,改变颜色的映射关系得到更加绚丽多彩的图片。基于此,在 mandelbrot 的代码中加入了用户可以自己配置的参数,具体的含义如下表

-
图片的翻转
执行指令 mpirun -np 4 ./mandelbrot -n 20000 -a -3.5

-
图片的缩放
执行指令 mpirun -np 4 ./mandelbrot -n 20000 -a 1

-
改变分区的大小
执行命令 mpirun -np 4 ./mandelbrot -n 5000 -b 8 -a -2

-
沿 X,Y 轴平移
执行命令 mpirun -np 4 ./mandelbrot -n 20000 -x 0.1 -y -0.8 -a 0.3

-
改变颜色区间
执行命令 mpirun -np 4 ./mandelbrot -n 10000 -p 0xffffff -q 0x000000

-
添加掩膜颜色
执行命令 mpirun -np 4 ./mandelbrot -n 10000 -p 0xffffff -q 0x00cccc -m CCFFFF

5. 结果和讨论
实验平台:
硬件:华为鲲鹏 920
软件:Xshell, Xftp
硬件平台参数
- Cpu 的信息:
输 入 命 令 ”lscpu” 查 看 cpu 的 信息, 可 以 看 到 该 模 型 的 名 称 为
KunPeng-920, 一共有 64 个 cpu,每一个核对应一个线程。

- 逻辑 cpu 的数量:64

测试方案:每个分形设置 26 组实验,每组实验设有不同的线程,范围是2~250。每组实验重复 5 次测试得到其耗时的平均值(具体数值清参见附录)
可视化分析:分别绘制 Mandelbrot 和 Julia 的线程数和耗时关系的折线图。

由上表可以看出,在线程数的范围在 2~25,随着线程数的增加,耗时下降的速率很快;
当线程数的范围在 25~75 时,随着线程数的增加,耗时下降的速率变缓;当线程数大于 75时,随着线程数的增加耗时反而略有增加。
综上可知,在一定范围内随着线程数的增加,并行计算的效率越高。但是超过一定范围后,由于调用 MPI_Send 函数和 MPI_Recv 函数,通信的时间开销大幅增加,导致整体的耗时
增加。
6. 总结
本报告提出的建议是采用并实现基于轮循行分割的分区方案,将 Mandelbrot
集合算法和 Julia 集合算法并行化。基于分区方案的并行化是利用 C 编程中的消
息传递接口(Message Passing Interface, MPI)库实现的。实验结果表明,使用
MPI 在 C 编程中提出的基于轮循行分割的分区方案的程序显著加速。因此证明了程序的成功并行化
7. 附录
7.1 其他结果展示
Mandelbrot 生成的其他图片展示

Julia Set 生成的其他图片展示:



7.2 源代码附录
7.2.1 mandelbrot源码
#include "mandelbrot.h"
int main(int argc, char **argv)
{
int proc_count, proc_id, retval;
mo_opts_t *opts;
/* MPI 初始化*/
if (MPI_Init(&argc, &argv) != MPI_SUCCESS) {
eprintf("MPI initialization failed.\n");
exit(EXIT_FAILURE);
}
/* 得到可用的进程数 */
MPI_Comm_size(MPI_COMM_WORLD, &proc_count);
if (proc_count < 2) { //进程数至少为2
eprintf("Number of processes must be at least 2.\n");
finalize_exit(EXIT_FAILURE);
}
/* 得到当前进程的ID */
MPI_Comm_rank(MPI_COMM_WORLD, &proc_id);
opts = (mo_opts_t *) malloc(sizeof(*opts));// 开辟内存空间
if (opts == NULL) {
eprintf("unable to allocate memory for config.\n");
finalize_exit(EXIT_FAILURE);
}
retval = parse_args(argc, argv, opts, proc_id, proc_count); // 参数的配置信息
if (retval == EXIT_SUCCESS) {
if (proc_id == 0) {
retval = master_proc(proc_count - 1, opts); //id=0 是根进程
} else {
retval = slave_proc(proc_id, opts); //其他是从进程
}
}
free(opts);
MPI_Finalize(); // 结束
return retval;
}
/*
* 参数的配置信息
*/
static int parse_args(int argc, char **argv, mo_opts_t *opts, int proc_id, int proc_count)
{
/* 设定默认值 */
opts->max_iterations = MO_MAXITER; //最大的迭代次数
opts->width = MO_SIZE; // 图片的宽度
opts->height = MO_SIZE; // 图片的高度
opts->filename = MO_FILENAME; //存放的文件名
opts->min_color = MO_COLORMIN; //颜色的下限
opts->max_color = MO_COLORMAX; //颜色的上限
opts->color_mask = MO_COLORMASK; //掩膜的颜色
opts->blocksize = MO_BLOCKSIZE; //分区的大小
opts->show_progress = MO_PROGRESS; //显示进程信息
double x_offset = 0;
double y_offset = 0;
double axis_length = MO_N;
const char *opt_string = "c:r:n:hb:p:q:m:x:y:a:o:s";
int optval_int, c, index;
long optval_long;
double optval_double;
opterr = 0;
/* start parsing args */
while ((c = getopt(argc, argv, opt_string)) != -1) {
switch (c) {
case 'b': /* blocksize */
case 'c': /* width */
case 'r': /* height */
case 'n': /* iterations */
optval_int = atoi(optarg);
if (optval_int <= 0) {
if (proc_id == 0) {
print_usage(argv);
eprintf("argument of '-%c' has to be greater than zero.\n", c);
}
return EXIT_FAILURE;
}
if (c == 'c') opts->width = optval_int; else
if (c == 'r') opts->height = optval_int; else
if (c == 'n') opts->max_iterations = optval_int; else
if (c == 'b') opts->blocksize = optval_int;
break;
case 'p': /* colormin */
case 'q': /* colormax */
case 'm': /* colormask */
optval_long = strtol(optarg, NULL, 16);
if (c == 'p') opts->min_color = optval_long; else
if (c == 'q') opts->max_color = optval_long; else
if (c == 'm') opts->color_mask = optval_long;
break;
case 'x': /* xoffset */
case 'y': /* yoffset */
case 'a': /* axis-length */
optval_double = atof(optarg);
if (c == 'x') x_offset = optval_double; else
if (c == 'y') y_offset = optval_double; else
if (c == 'a') {
if (optval_double == 0) {
if (proc_id == 0) {
print_usage(argv);
eprintf("argument of '-%c' cannot be zero.\n", c);
}
return EXIT_FAILURE;
}
axis_length = optval_double;
}
break;
case 'o': /* output */
opts->filename = optarg;
break;
case 's': /* progress */
opts->show_progress = 1;
break;
case 'h': /* help */
if (proc_id == 0) {
print_usage(argv);
}
free(opts);
finalize_exit(EXIT_SUCCESS);
break;
case '?': /* unknown opt */
if (proc_id == 0) {
/* hacky fix: get correct index if length of invalid option is > 2 */
index = (strncmp(argv[0], argv[optind - 1], sizeof(argv)) == 0)
? optind
: optind-1;
print_usage(argv);
eprintf("invalid option '%s'.\n", argv[index]);
}
return EXIT_FAILURE;
break;
default:
break;
}
}
/* blocksize 的大小要可以整除height */
if (opts->height % opts->blocksize != 0) {
if (proc_id == 0) {
print_usage(argv);
eprintf("argument of '-b' has to be a divisor of %d.\n", opts->height);
}
return EXIT_FAILURE;
}
/* 避免出现过大的blocksize */
if (opts->blocksize > opts->height/(proc_count - 1)) {
if (proc_id == 0) {
print_usage(argv);
eprintf("argument of '-b' has to be smaller than %d.\n", opts->height/(proc_count-1));
}
return EXIT_FAILURE;
}
/* 计算图片的区间范围 */
opts->min_re = x_offset - axis_length;
opts->max_re = x_offset + axis_length;
opts->min_im = y_offset - axis_length;
opts->max_im = y_offset + axis_length;
/* 显示配置信息 */
if (proc_id == 0) {
if (argc < 2) {
printf("Note: Program invoked with default options.\n" \
" Run '%s -h' for detailed information on available arguments.\n\n", argv[0]);
}
print_params(opts, x_offset, y_offset, axis_length);
}
return EXIT_SUCCESS;
}
/*
* 在计算前显示配置信息
*/
static void print_params(mo_opts_t *opts, double x_off, double y_off, double axis_length)
{
printf("Computation parameters:\n" \
" output file %s\n" \
" maximum iterations %d\n" \
" blocksize %d\n" \
" image width %d\n" \
" image height %d\n" \
" minimum color 0x%06lx\n" \
" maximum color 0x%06lx\n" \
" color mask 0x%06lx\n" \
" x-offset %g\n" \
" y-offset %g\n" \
" axis length %g\n" \
" coordinate system range [%g, %g]\n\n",
opts->filename, opts->max_iterations, opts->blocksize, opts->width, opts->height,
opts->min_color, opts->max_color, opts->color_mask, x_off, y_off, axis_length,
opts->min_re, opts->max_re);
}
/*
* 显示使用说明
*/
static void print_usage(char **argv)
{
printf("\nDynamic MPI mandelbrot algorithm\n\n" \
"usage: %s [options]\n\n" \
"OPTIONS:\n" \
" -h Shows this help.\n" \
" -c {width} Width of resulting image. Has to be positive integer.\n" \
" (default: %d)\n" \
" -r {height} Height of resulting image. Has to be positive integer.\n" \
" (default: %d)\n" \
" -n {iterations} Maximum number of iterations for each pixel. Has to be\n" \
" positive integer (default: %d)\n" \
" -o {filename} Filename of resulting bitmap. (default: %s)\n" \
" -b {blocksize} Number of rows to be assigned to a slave at once.\n" \
" Has to be smaller than (height/slave-count).\n" \
" Has to be a divisor of height. (default: %d)\n" \
" -x {offset} X-offset from [0,0]. (default: %g)\n" \
" -y {offset} Y-offset from [0,0]. (default: %g)\n" \
" -a {length} Absolute value range of x/y-axis, e.g. if length was 2, \n" \
" displayed x/y-values would range from -1 to 1. \n" \
" If the x/y-offsets are set, axis shifts by those offsets.\n" \
" Negative value inverts axis.\n" \
" Has to be non-zero double value. (default: %g)\n" \
" -p {hexnum} Minimum color of the resulting image. (default: 0x%06lx)\n" \
" -q {hexnum} Maximum color of the resulting image. (default: 0x%06lx)\n" \
" -m {hexnum} Hex mask to manipulate color ranges. (default: 0x%06lx)\n" \
" -s Print progress of the computation.\n\n",
argv[0], MO_SIZE, MO_SIZE, MO_MAXITER, MO_FILENAME, MO_BLOCKSIZE, 0.0f, 0.0f,
(double) MO_N, (long) MO_COLORMIN, (long) MO_COLORMAX, (long) MO_COLORMASK);
}
/*
* 主进程的运行逻辑
*/
static int master_proc(int slave_count, mo_opts_t *opts)
{
int *rows = (int *) malloc(opts->blocksize*sizeof(*rows));
long *data = (long *) malloc((opts->width + 1)*opts->blocksize*sizeof(*data));
char *rgb = (char *) malloc(3*opts->width*opts->height*sizeof(*rgb));
if (rows == NULL || data == NULL || rgb == NULL) {
eprintf("unable to allocate memory for buffers.\n");
free(rows); free(data); free(rgb);
return EXIT_FAILURE;
}
int proc_id, offset;
double start_time, end_time;
long pixel_color, pixel_pos;
int current_row = 0;
int running_tasks = 0;
int retval = EXIT_SUCCESS;
MPI_Status status;
printf("Computation started.\n");
/* 记录开始时间 */
start_time = MPI_Wtime();
/* 为每一个从进程初始化 row(s) */
for (int p = 0; p < slave_count; ++p) {
for (int i = 0; i < opts->blocksize; ++i) {
rows[i] = current_row++;
}
MPI_Send(rows, opts->blocksize, MPI_INT, p + 1, MO_CALC, MPI_COMM_WORLD);
++running_tasks;
}
/* reveice results from slaves until all rows are processed */
while (running_tasks > 0) {
MPI_Recv(data, (opts->width + 1)*opts->blocksize, MPI_LONG, MPI_ANY_SOURCE,
MO_DATA, MPI_COMM_WORLD, &status);
--running_tasks;
proc_id = status.MPI_SOURCE;
/* if there are still rows to be processed, send slave to work again
* otherwise send him to sleep */
if (current_row < opts->height) {
for (int i = 0; i < opts->blocksize; ++i) {
rows[i] = current_row++;
}
MPI_Send(rows, opts->blocksize, MPI_INT, proc_id, MO_CALC, MPI_COMM_WORLD);
++running_tasks;
} else {
MPI_Send(NULL, 0, MPI_INT, proc_id, MO_STOP, MPI_COMM_WORLD);
}
/* store received row(s) in rgb buffer */
for (int i = 0; i < opts->blocksize; ++i) {
offset = opts->width*i;
for (int col = 0; col < opts->width; ++col) {
pixel_color = data[offset + col + 1] & opts->color_mask;
pixel_pos = 3*(opts->width*data[offset] + col);
rgb[pixel_pos] = (char) ((pixel_color >> 16) & 0xFF);
rgb[pixel_pos + 1] = (char) ((pixel_color >> 8) & 0xFF);
rgb[pixel_pos + 2] = (char) (pixel_color & 0xFF);
}
}
/* 当配置信息有要求时,显示进度条 */
if (opts->show_progress) {
static int rows_processed = 0;
print_progress(rows_processed += opts->blocksize, opts->height);
}
}
/* 获得结束时间 */
end_time = MPI_Wtime();
/* 清空进度条 */
if (opts->show_progress) printf("\033[K");
printf("Finished. Computation finished in %g sec.\n\n", end_time - start_time); // 显示时间
/* 将rgb信息写入到图片中 */
printf("Creating bitmap image.\n");
retval = write_bitmap(opts->filename, opts->width, opts->height, rgb);
if (retval == EXIT_SUCCESS) {
printf("Finished. Image stored in '%s'.\n", opts->filename);
} else {
eprintf("failed to write bitmap to file.\n");
}
// 释放内存空间
free(rows);
free(data);
free(rgb);
return retval;
}
/*
* 从进程的运行逻辑
*/
static int slave_proc(int proc_id, mo_opts_t *opts)
{
int *rows = (int *) malloc(opts->blocksize*sizeof(*rows));
long *data = (long *) malloc((opts->width + 1)*opts->blocksize*sizeof(*data));
mo_scale_t *scale = (mo_scale_t *) malloc(sizeof(*scale));
if (rows == NULL || data == NULL || scale == NULL) {
free(rows); free(data); free(scale);
return EXIT_FAILURE;
}
long pixel_color;
int offset;
MPI_Status status;
/* 计算颜色缩放因子 */
scale->color = (double) (opts->max_color - opts->min_color) /
(double) (opts->max_iterations - 1);
/* 计算区域的图像大小的缩放因子 */
scale->re = (double) (opts->max_re - opts->min_re) / (double) opts->width;
scale->im = (double) (opts->max_im - opts->min_im) / (double) opts->height;
/* 如果状态为MO_CALC,接收行并开始计算 */
while ((MPI_Recv(rows, opts->blocksize, MPI_INT, 0, MPI_ANY_TAG, MPI_COMM_WORLD,
&status) == MPI_SUCCESS) && status.MPI_TAG == MO_CALC) {
for (int i = 0; i < opts->blocksize; ++i) {
offset = opts->width*i;
data[offset] = rows[i];
/* 使用mandelbrot算法计算像素颜色 */
for (int col = 0; col < opts->width; ++col) {
pixel_color = mandelbrot(col, rows[i], scale, opts);
data[offset + col + 1] = pixel_color;
}
}
/* 向主进程发送row(s) */
MPI_Send(data, (opts->width + 1)*opts->blocksize, MPI_LONG, 0, MO_DATA, MPI_COMM_WORLD);
}
//释放内存空间
free(rows);
free(data);
free(scale);
return EXIT_SUCCESS;
}
/*
* 使用mandelbrot算法计算像素颜色
*/
static long mandelbrot(int col, int row, mo_scale_t *scale, mo_opts_t *opts)
{
mo_complex_t a, b;
a.re = a.im = 0;
/* 缩放显示坐标到实际区域 */
b.re = opts->min_re + ((double) col*scale->re);
b.im = opts->min_im + ((double) (opts->height - 1 - row)*scale->im);
/* 计算z0, z1,直到发散或最大迭代 */
int n = 0;
double r2, tmp;
do {
tmp = a.re*a.re - a.im*a.im + b.re;
a.im = 2*a.re*a.im + b.im;
a.re = tmp;
r2 = a.re*a.re + a.im*a.im;
++n;
} while (r2 < MO_THRESHOLD && n < opts->max_iterations);
/* 对颜色进行缩放并且返回 */
return (long) ((n - 1)*scale->color) + opts->min_color;
}
/*
* 绘制进度条
*/
static inline void print_progress(int rows_processed, int row_count)
{
int r = row_count/MO_PUPDATE;
/* 只更新MO_PUPDATE次数 */
if (r == 0 || rows_processed % r != 0) return;
/* 计算比率和当前位置 */
float ratio = rows_processed/(float) row_count;
int pos = ratio*MO_PWIDTH;
/* 绘制进度条 */
printf("%3d%% [", (int) (ratio*100));
for (int i = 0; i < pos; ++i) printf("=");
for (int i = pos; i < MO_PWIDTH; ++i) printf(" ");
/* 回车以覆盖下一次进度条更新 */
printf("]\r");
}
/*
* 绘制图片
*/
static int write_bitmap(const char *filename, int width, int height, char *rgb)
{
int i, j, pixel_pos;
int bytes_per_line;
unsigned char *line;
FILE *file;
mo_bmp_header_t bmph;
/* 每一行的长度必须是4字节的倍数 */
bytes_per_line = (3*(width + 1)/4)*4;
bmph.type[0] = 'B';
bmph.type[1] = 'M';
bmph.offbits = 54;
bmph.fsize = bmph.offbits + bytes_per_line*height;
bmph.reserved = 0;
bmph.hsize = 40;
bmph.width = width;
bmph.height = height;
bmph.planes = 1;
bmph.bit_count = 24;
bmph.compression = 0;
bmph.size_image = bytes_per_line*height;
bmph.x_pels_per_meter = 0;
bmph.y_pels_per_meter = 0;
bmph.clr_used = 0;
bmph.clr_important = 0;
file = fopen(filename, "wb");
if (file == NULL) {
eprintf("unable to open file '%s'.\n", filename);
return EXIT_FAILURE;
}
/* write header */
fwrite(&bmph.type, 2, 1, file);
fwrite(&bmph.fsize, 4, 1, file);
fwrite(&bmph.reserved, 4, 1, file);
fwrite(&bmph.offbits, 4, 1, file);
fwrite(&bmph.hsize, 4, 1, file);
fwrite(&bmph.width, 4, 1, file);
fwrite(&bmph.height, 4, 1, file);
fwrite(&bmph.planes, 2, 1, file);
fwrite(&bmph.bit_count, 2, 1, file);
fwrite(&bmph.compression, 4, 1, file);
fwrite(&bmph.size_image, 4, 1, file);
fwrite(&bmph.x_pels_per_meter, 4, 1, file);
fwrite(&bmph.y_pels_per_meter, 4, 1, file);
fwrite(&bmph.clr_used, 4, 1, file);
fwrite(&bmph.clr_important, 4, 1, file);
line = (unsigned char *) malloc(bytes_per_line*sizeof(*line));
if (line == NULL) {
eprintf("unable to allocate memory for line buffer.\n");
fclose(file);
return EXIT_FAILURE;
}
/* 写rgb信息 */
for (i = height - 1; i >= 0; i--) {
for (j = 0; j < width; j++) {
pixel_pos = 3*(width*i + j);
line[3*j] = rgb[pixel_pos + 2];
line[3*j + 1] = rgb[pixel_pos + 1];
line[3*j + 2] = rgb[pixel_pos];
}
fwrite(line, bytes_per_line, 1, file);
}
free(line);
fclose(file);
return EXIT_SUCCESS;
}
7.2.2 Julia源码
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#include "mpi.h"
#include "cmplx.h"
#define FULL_WIDTH 1024
#define CHUNK_WIDTH 32
#define MAX_ITER 1000
void plot(int* image_arr, FILE* img);
long iterator(Complex c, double im, double re);
int main(int argc, char* argv[])
{
int *image_arr;
int pixel_YX[3];
int Y_start, X_start, CUR_CHUNK, disp = 0;
int i, j;
Complex c;
FILE *img;
int NUM_CHUNKS = (FULL_WIDTH / CHUNK_WIDTH) * (FULL_WIDTH / CHUNK_WIDTH);
/** 时间相关 **/
double start, stop;
float elapsed_time;
/** MPI相关变量 **/
MPI_Status status, stat_recv;
MPI_Request request;
MPI_Datatype CHUNKxCHUNK, CHUNKxCHUNK_RE;
int rankID, numProcs, numSlaves;
/** MPI环境的初始化 **/
MPI_Init(&argc, &argv);
MPI_Barrier(MPI_COMM_WORLD);
MPI_Comm_size(MPI_COMM_WORLD, &numProcs);
MPI_Comm_rank(MPI_COMM_WORLD, &rankID);
MPI_Barrier(MPI_COMM_WORLD);
/** 创建类型 **/
int full_sizes[2] = {FULL_WIDTH, FULL_WIDTH};
int sub_sizes[2] = {CHUNK_WIDTH, CHUNK_WIDTH};
int starting[2] = {0, 0};
int sendcounts[numProcs];
int displs[numProcs];
/** 创建CHUNK */
MPI_Type_create_subarray(
2,
full_sizes,
sub_sizes,
starting,
MPI_ORDER_C,
MPI_INT,
&CHUNKxCHUNK
);
/** 设置偏移 **/
MPI_Type_create_resized(
CHUNKxCHUNK,
0,
CHUNK_WIDTH * sizeof(int),
&CHUNKxCHUNK_RE
);
/** 提交要使用的类型 **/
MPI_Type_commit(&CHUNKxCHUNK_RE);
/** 从进程的个数 */
numSlaves = numProcs - 1;
/** 打印基本信息 */
if(rankID == 0)
printf("Runtime Stats:\n\tNum Procs:\t%d\n\tNum Slaves:\t%d\n", numProcs, numSlaves);
MPI_Barrier(MPI_COMM_WORLD);
/** 参数C的取值 */
c.re = -0.4;
c.im = 0.5;
/** 主进程 */
if(rankID == 0) {
img = fopen("t6.ppm", "w");
if(img == NULL) {
printf("Could not open handle to image\n");
return 1;
}
fprintf(img, "P6\n%d %d 255\n", FULL_WIDTH, FULL_WIDTH);
image_arr = (int *)malloc(FULL_WIDTH * FULL_WIDTH * sizeof(int));
/** 开启计时器 */
start = MPI_Wtime();
/** 计算X和Y 并分发到各个节点 **/
for(pixel_YX[2] = 0; pixel_YX[2] < numSlaves; pixel_YX[2]++) {
pixel_YX[0] = (pixel_YX[2] / (FULL_WIDTH / CHUNK_WIDTH)) * CHUNK_WIDTH; // Y
pixel_YX[1] = (pixel_YX[2] % (FULL_WIDTH / CHUNK_WIDTH)) * CHUNK_WIDTH; // X
MPI_Send(
pixel_YX,
3,
MPI_INT,
pixel_YX[2] + 1,
0,
MPI_COMM_WORLD
);
}
/** 更新当前的chunk和pixel */
pixel_YX[2] = numSlaves;
pixel_YX[0] = (pixel_YX[2] / (FULL_WIDTH / CHUNK_WIDTH)) * CHUNK_WIDTH; // Y
pixel_YX[1] = (pixel_YX[2] % (FULL_WIDTH / CHUNK_WIDTH)) * CHUNK_WIDTH; // X
/** 从X接收当前块并发送下一个块到X */
while(pixel_YX[2] < NUM_CHUNKS) {
/** 探测接收缓冲区,计算阵列内的位移,并接收 */
MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &stat_recv);
disp = ((stat_recv.MPI_TAG * CHUNK_WIDTH) % FULL_WIDTH) +
(((stat_recv.MPI_TAG * CHUNK_WIDTH) / FULL_WIDTH) * CHUNK_WIDTH * FULL_WIDTH);
MPI_Recv(
image_arr + disp,
1,
CHUNKxCHUNK_RE,
stat_recv.MPI_SOURCE,
stat_recv.MPI_TAG,
MPI_COMM_WORLD,
&status
);
#ifdef DEBUG
printf("Proc: MA\tJob: Recieved [# %d]\n", stat_recv.MPI_TAG);
#endif
MPI_Send(
pixel_YX,
3,
MPI_INT,
status.MPI_SOURCE,
0,
MPI_COMM_WORLD
);
/** pixel_YX到下一个块值 */
pixel_YX[2]++;
pixel_YX[0] = (pixel_YX[2] / (FULL_WIDTH / CHUNK_WIDTH)) * CHUNK_WIDTH;
pixel_YX[1] = (pixel_YX[2] % (FULL_WIDTH / CHUNK_WIDTH)) * CHUNK_WIDTH;
}
/** 最终接收匹配初始发送 */
for(i = 0; i < numSlaves; i++) {
MPI_Probe(MPI_ANY_SOURCE, MPI_ANY_TAG, MPI_COMM_WORLD, &stat_recv);
disp = ((stat_recv.MPI_TAG * CHUNK_WIDTH) % FULL_WIDTH) + (((stat_recv.MPI_TAG * CHUNK_WIDTH) / FULL_WIDTH) * CHUNK_WIDTH * FULL_WIDTH);
MPI_Recv(
image_arr + disp,
1,
CHUNKxCHUNK_RE,
stat_recv.MPI_SOURCE,
stat_recv.MPI_TAG,
MPI_COMM_WORLD,
&status
);
#ifdef DEBUG
printf("Proc: MA\tJob: Recieved [# %d]\n", stat_recv.MPI_TAG);
#endif
}
/** 结束当前进程 **/
for(i = 0; i < numSlaves; i++)
MPI_Send(
0,
0,
MPI_INT,
i + 1,
0xFFFF,
MPI_COMM_WORLD
);
/** 停止计时器并计算elapsed_time */
stop = MPI_Wtime();
elapsed_time = stop - start;
#ifdef DEBUG
printf("Proc: Ma\tJob: Plotting image\n");
#endif
plot(image_arr, img);
printf("Algorithm completed for,\n\t%d * %d pixels\n\t%d maximum iterations\n\t\tin %f seconds.\n", \
FULL_WIDTH, FULL_WIDTH, \
MAX_ITER, \
elapsed_time);
fclose(img);
}
else {
/** 每个人分配他们的image_arr部分 */
image_arr = (int *)malloc(CHUNK_WIDTH * CHUNK_WIDTH * sizeof(int));
/** 无限循环直到' break; ' */
while(1) {
MPI_Recv(
pixel_YX,
3,
MPI_INT,
0,
MPI_ANY_TAG,
MPI_COMM_WORLD,
&status
);
/** 检查是否呼叫终止 */
if(status.MPI_TAG == 0xFFFF) {
printf("Proc: %d \tJob: Exiting\n", rankID);
break;
}
CUR_CHUNK = pixel_YX[2];
#ifdef DEBUG
printf("Proc: %d \tChunk %d \tJob: Algorithm\n", rankID, CUR_CHUNK);
#endif
/** 对于每一个Y值 */
for(i = 0; i < CHUNK_WIDTH; i++) {
for(j = 0; j < CHUNK_WIDTH; j++) {
image_arr[(i * CHUNK_WIDTH) + j] = iterator(
c,
-(((pixel_YX[0] + i) - (FULL_WIDTH / 2)) / (double) FULL_WIDTH) * 2,
(((pixel_YX[1] + j) - (FULL_WIDTH / 2)) / (double) FULL_WIDTH) * 2
);
}
}
#ifdef DEBUG
printf("Proc: %d \tJob: Returning [# %d]\n", rankID, CUR_CHUNK);
#endif
/** 发送部分计算成像到MASTER */
MPI_Send(
image_arr,
CHUNK_WIDTH * CHUNK_WIDTH,
MPI_INT,
0,
CUR_CHUNK,
MPI_COMM_WORLD
);
}
}
free(image_arr);
/** 结束MPI的运行环境 */
MPI_Type_free(&CHUNKxCHUNK_RE);
MPI_Finalize();
fflush(stdout);
return 0;
}
/**
程序的主迭代函数
*/
long iterator(Complex c, double im, double re)
{
Complex z;
long itCount = 0;
z.re = re;
z.im = im;
for(; itCount < MAX_ITER; itCount++) {
z = cmplx_add(cmplx_squared(z), c);
if(cmplx_magnitude(z) > 4)
break;
}
return itCount + 1;
}
/**
绘制图形
*/
void plot(int* image_arr, FILE* img)
{
int i, j;
unsigned char line[3 * FULL_WIDTH];
for(i = 0; i < FULL_WIDTH; i++) {
for(j = 0; j < FULL_WIDTH; j++) {
if (*(image_arr + j + (i * FULL_WIDTH)) <= 63) {
line[3 * j] = 255;
line[3 * j + 1] = line[3 * j + 2] =
255 - 4 * *(image_arr + j + (i * FULL_WIDTH));
} else {
line[3 * j] = 255;
line[3 * j + 1] = *(image_arr + j + (i * FULL_WIDTH)) - 63;
line[3 * j + 2] = 0;
}
if (*(image_arr + j + (i * FULL_WIDTH)) == 320)
line[3 * j] = line[3 * j + 1] = line[3 * j + 2] = 255;
}
fwrite(line, 1, 3 * FULL_WIDTH, img);
}
}
7.3 参考
https://github.com/BodneyC/JuliaSet
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











