







一、
对于目标检测的预测阶段,后处理是对于非常重要的,对于 YOLO 而言,后处理就是把复杂的预测出来的 98 个预测框,进行筛选、过滤,把重复的预测框只保留一个,最终获得目标检测的结果。包含把低置信度的框过滤掉,以及把重复的过滤框去掉,只保留一个,那么这个步骤称为 NMS 非极大值抑制。
二、具体做法
首先,YOLO 是一个黑箱,在预测阶段把输入图像 448 X 448 X 3 通道的图像,进行编码、压缩处理,经过卷积层、全连接层,最后获得 7 X 7 X 30 维的张量,后处理就是把 7 X 7 X 30 维的张量变成最后的目标检测结果。
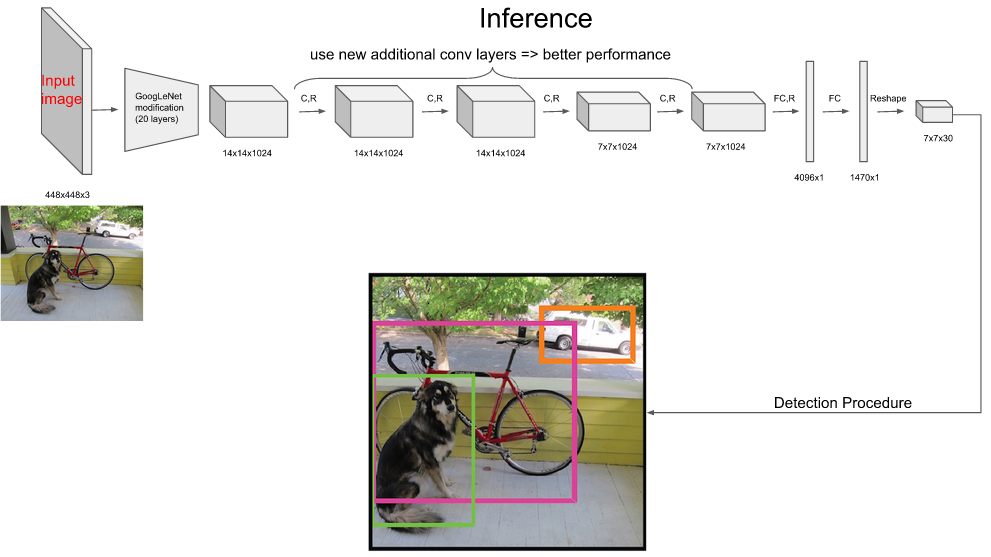
三、7 X 7 X 30 维的张量如何变成最终目标检测结果
1、
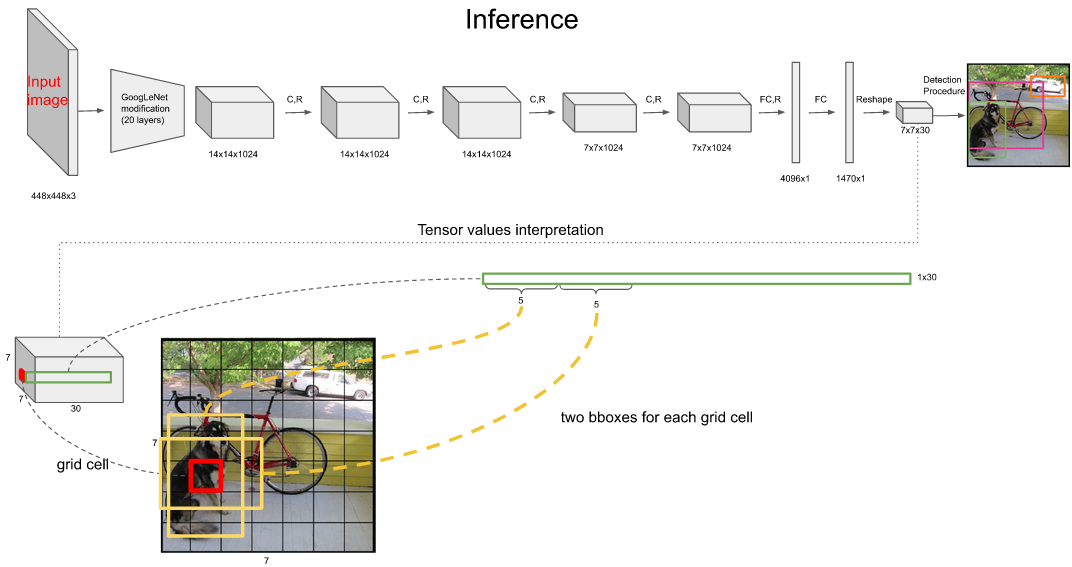
7 X 7 意味着是 7 X 7 个 grid cell(网格单元),取出其中的一个 grid cell(网格单元)来看,应该包含 30 个数字,30 个数字是由 5,5,20 构成,第一个 5 是第一个 bounding boxes (边界框)的四个位置坐标和一个置信度坐标,第二个 5 是第二个 bounding boxes (边界框)的四个位置坐标和一个置信度坐标,20 是该 grid cell(网格单元)对 20 个类别的条件概率,即假设该grid cell(网格单元)预测物体的条件下,20 个类别的概率是多少。
2、
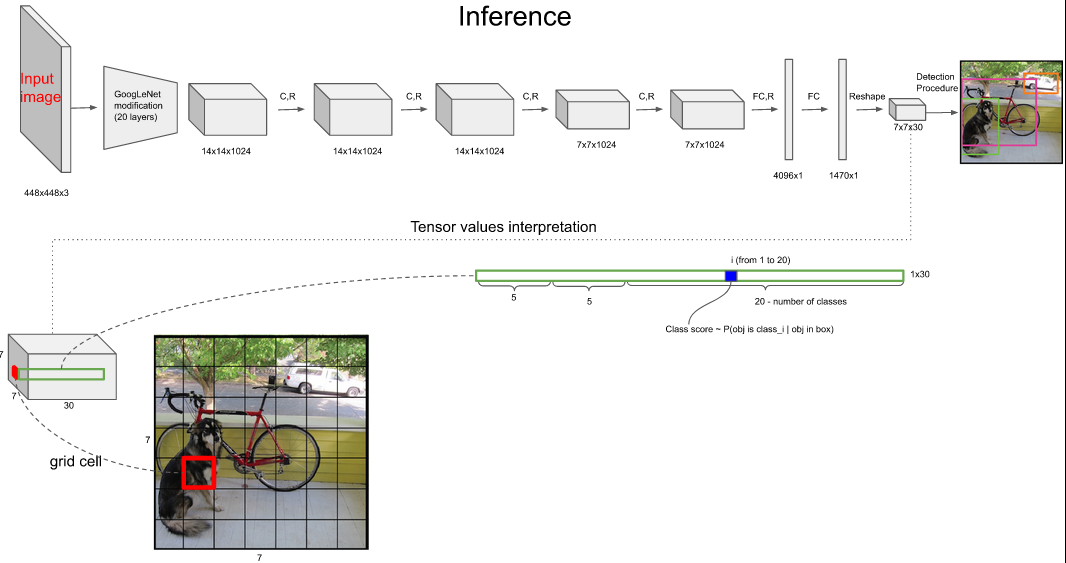
假设 bounding boxes (边界框)负责预测物体的条件下,它是某个类别的概率,是狗的概率、猫的概率等。
3、
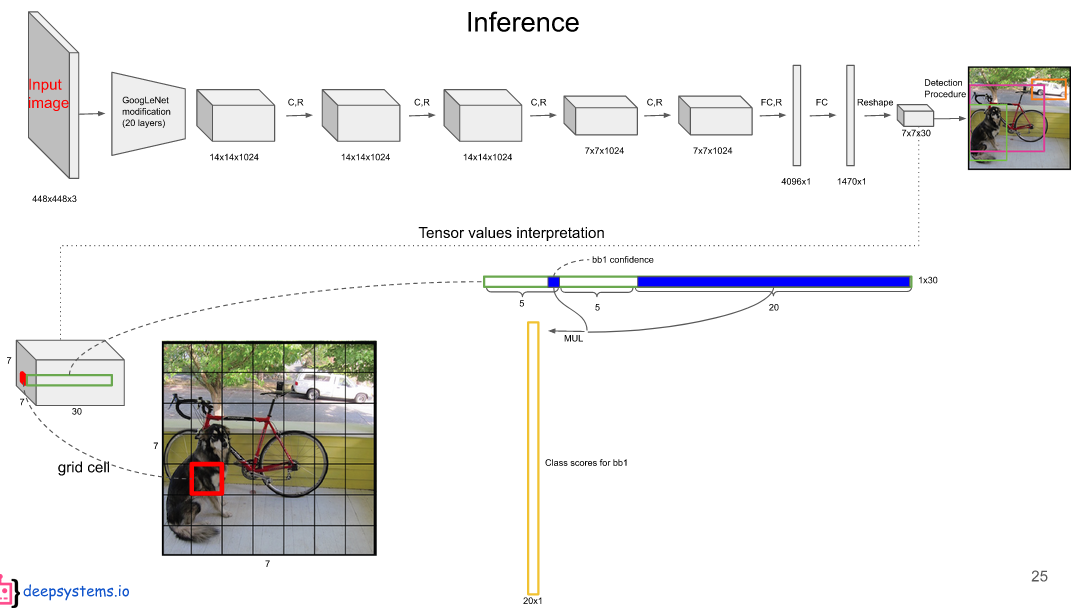
把20个类别的条件概率拿出来,与 bounding boxes (边界框)的置信度相乘,条件概率乘以条件本身发生的概率,就变成了它的全概率,就是说该bounding boxes (边界框)包含物体的概率就是它的置信度乘以在包含物体的条件下,各个类别的概率,那么就得到了真正是哪个类别的概率,不再是条件概率。第一个预测框的置信度乘以该grid cell(网格单元)的20个类别的条件概率得到第一个预测框的20个类别的全概率。
4、
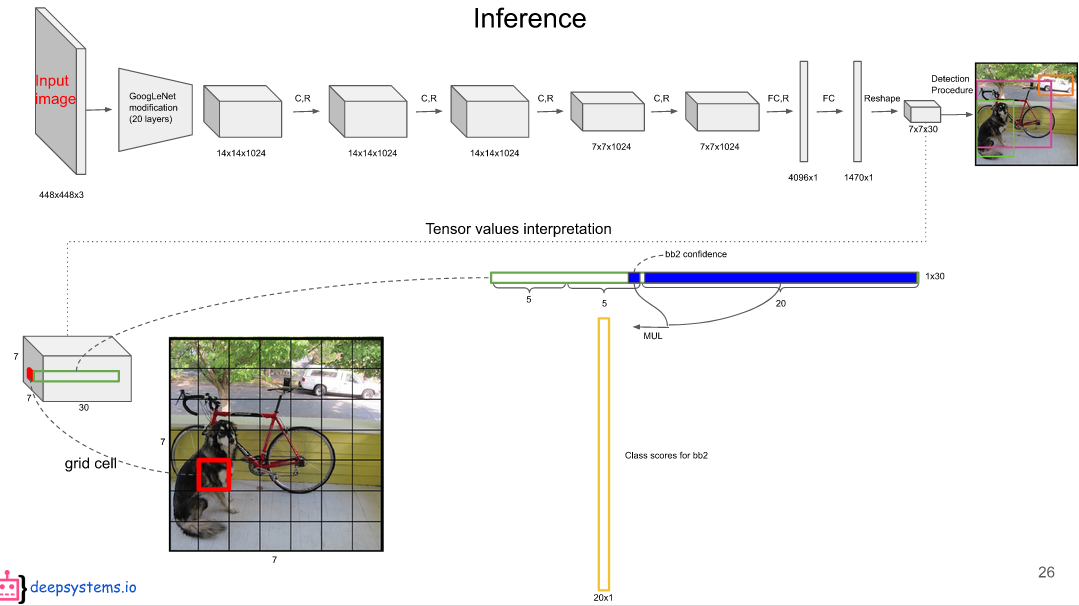
第二个预测框的置信度乘以该grid cell(网格单元)的20个类别的条件概率得到第二个预测框的20个类别的全概率。
5、
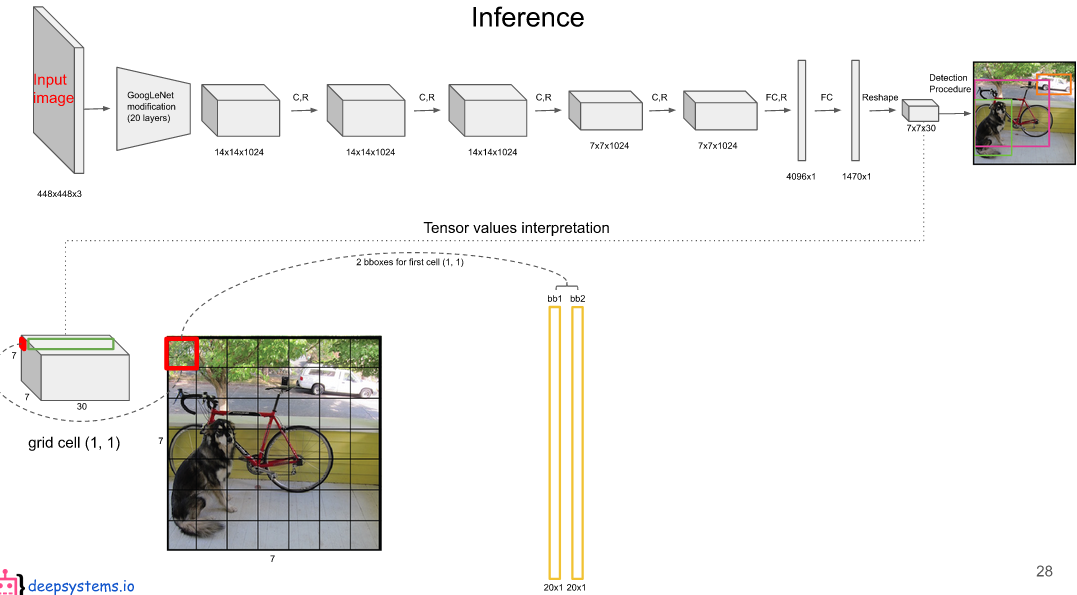
每一个grid cell(网格单元)都能获得两个 20 维的全概率,分别表示两个预测框。
6、
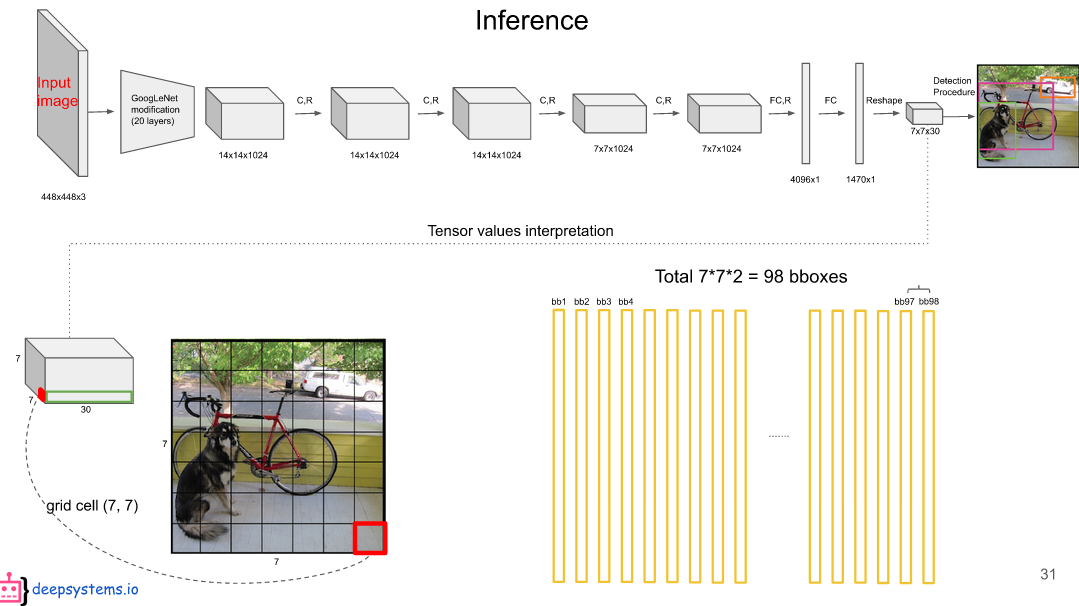
一共 49 个 grid cell(网格单元),生成 98 个 20 维的向量。每一列表示,对于某一个bounding boxes (边界框)而言,20 个类别的概率是多少。
7、
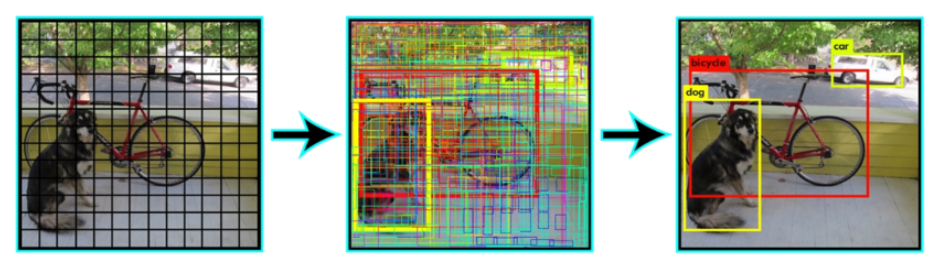
目前获得中间的图。那么如何获得最后的类别结果?
四、后处理
1、
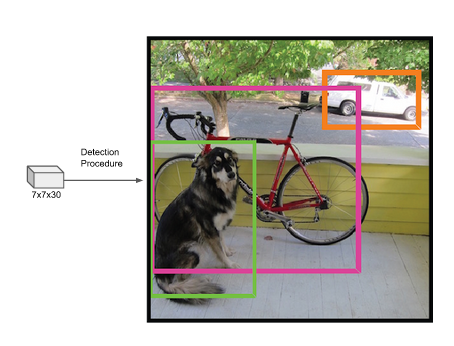
即把 7 X 7 X 30 的张量变成最终的目标检测结果。
2、
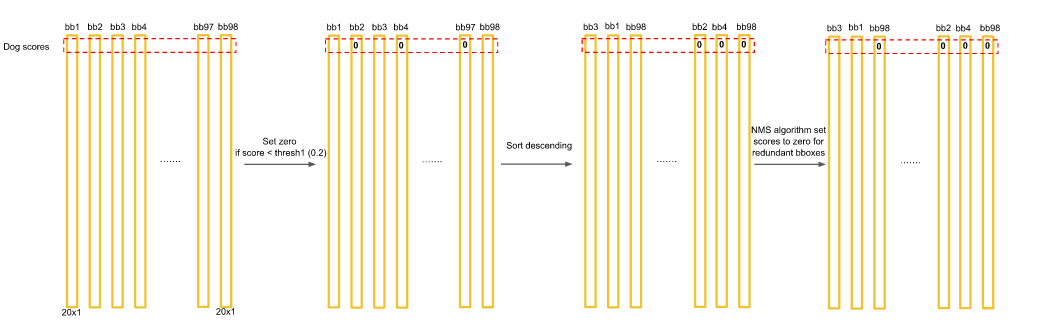
目前获得 98 个竖条(长度均为 20 ),第一个数字就是狗的概率。假如说狗是 20 个类别中的第一个类别。这些概率里面有一些很小的,如0.002,0.003等,那么我们设置一个阈值,把所有小于阈值的数,一律归为 0 ,那么很多概率就是 0 ,再按照狗的概率的高低排序,把狗的概率高的放在前面,低的放在后面,再对排序之后的结果进行非极大值抑制 NMS。
3、非极大值抑制 NMS 如何操作?
1、
比如目前获得的 98 个竖条中,某几个竖条中狗的概率不是 0 ,并且是从高到低排序的。

2、


先把最高的拿出来,之后把每一个都跟最高的作比较。比如拿第一个跟第二个比较,如果它两个的IOU(交并比)大于某一个阈值,我们认为两者重复识别了一个物体,就把低概率的过滤掉。阈值可以调节,如果阈值很低的话,比如 0.1 ,NMS 是非常强的,稍微跟黄框有一丁点重叠,就被替掉了;而如果阈值设置的很高,需要另外一个框与黄框有非常高的重合才可能被替掉。所以如果想加强 NMS,可以把阈值设置的低一些。
3、
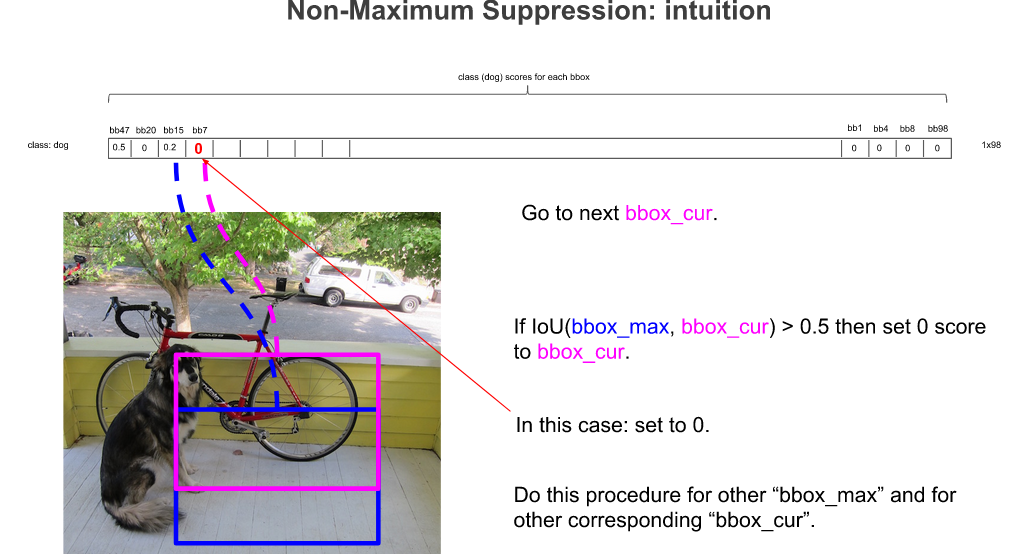
再看第二高的,因为 bb20 已经被淘汰,所以看 bb15,把后面所有比 0.2 低的框和蓝框比较,IOU(交并比)大于 0.5,所以将其归 0。
4、

最后就得到了橙框和蓝框两个结果。其他一律都被归 0 。这就是 NMS 的流程。这只是对狗这一个类别,那么对每一个类别都应该这样操作,就获得了最终的目标检测结果。
5、
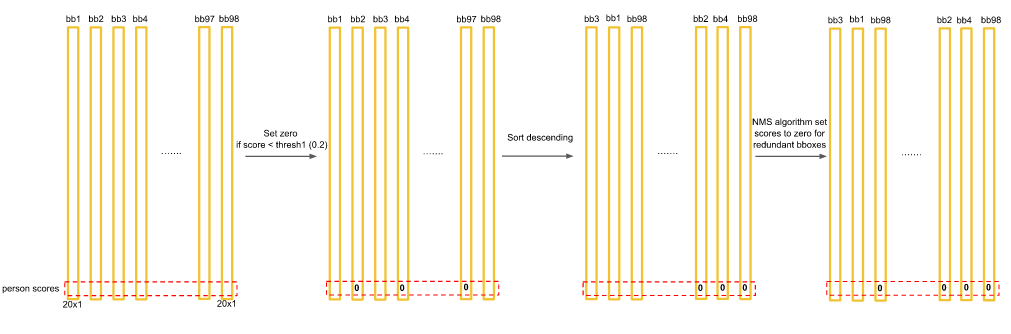
20个类别,就进行20次的NMS非极大值抑制。
6、
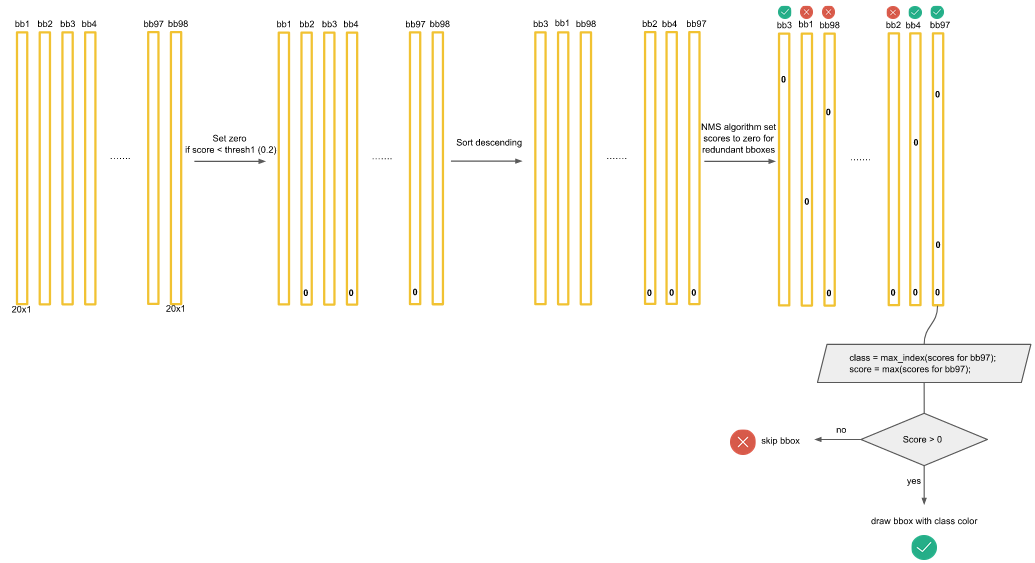
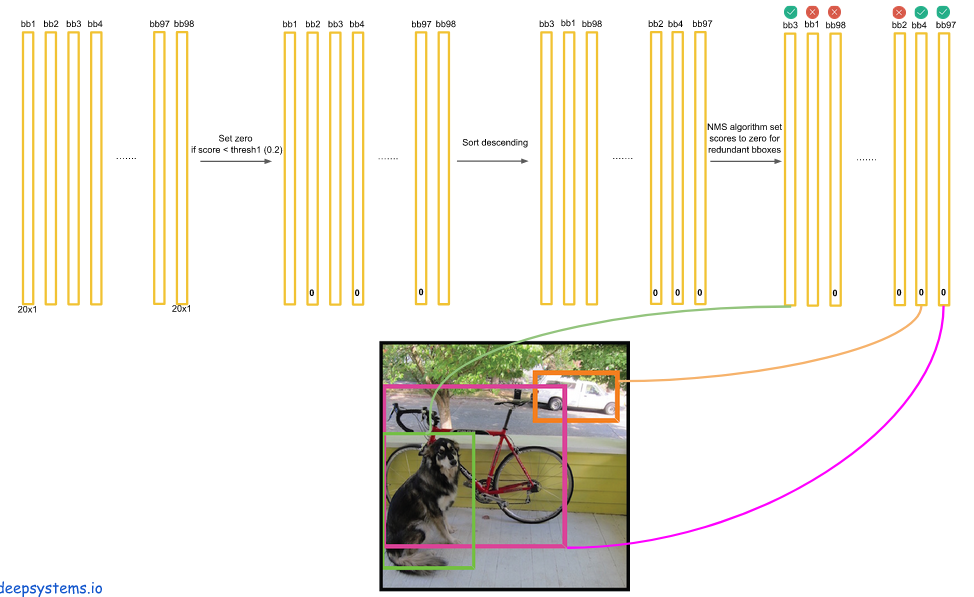
最后结果是一个稀疏矩阵,将很多值设为 0 了,如果不为0,将其拿出,将其的类别和分数拿出,作为目标检测的结果。上图中 bb3,bb4,bb97有一些类别是不为0的,把不为0的类别索引找出来,即把它代表什么找出来,再把它的概率找出来,可视化在目标检测结果上,就获得最终的目标检测结果。
在训练阶段是不需要进行NMS的,因为每一个框都在损失函数中占据一席之地,都会影响损失函数,所以不能随便在训练阶段把预测框替换掉,把概率抹零。只是在预测阶段,在已经训练出来这个模型之后,进行待测图片的预测的时候,才需要通过后处理,把低置信度的框过滤掉,再把重复识别同样物体的重复框只挑出一个。

















 6840
6840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









