







往期文章链接目录
文章目录
Comparison between CBOW and Skip-gram
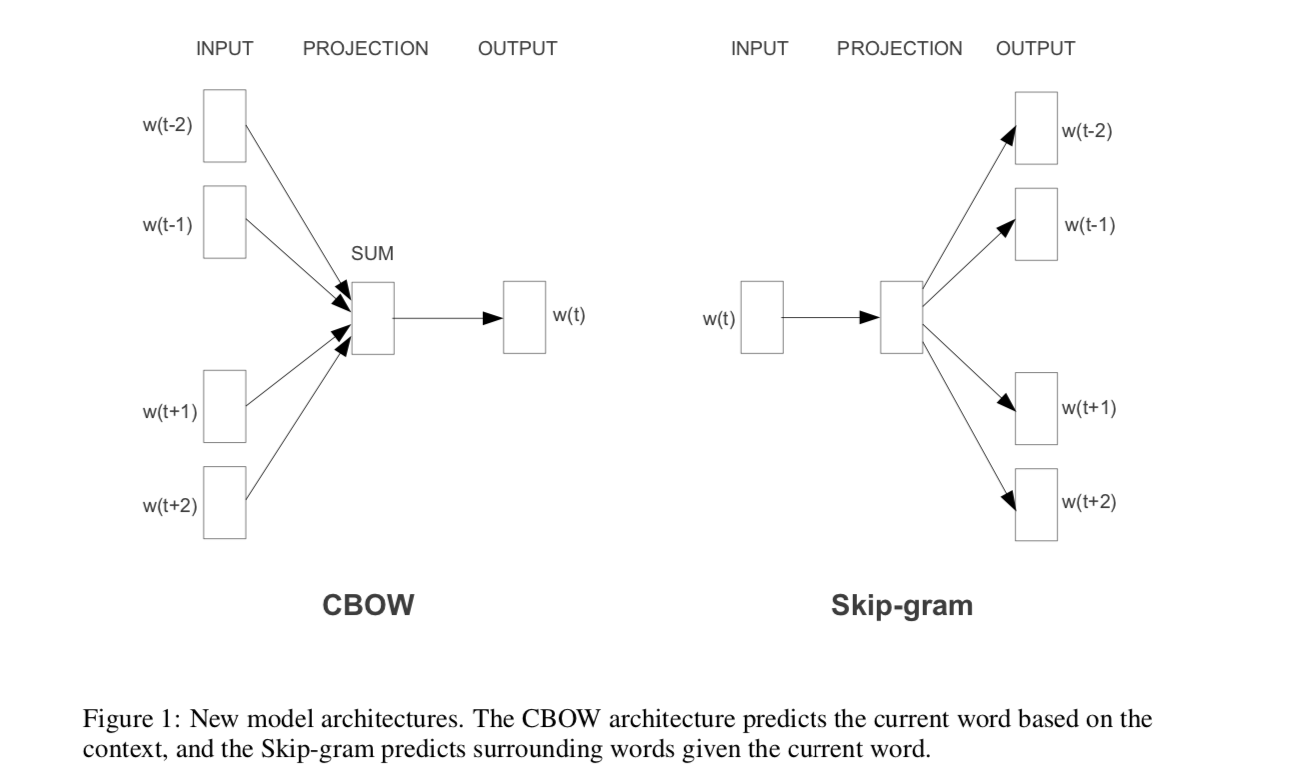
The major difference is that skip-gram is better for infrequent words than CBOW in word2vec. For simplicity, suppose there is a sentence “ w 1 w 2 w 3 w 4 w_1w_2w_3w_4 w1w2w3w4”, and the window size is 1 1 1.
For CBOW, it learns to predict the word given a context, or to maximize the following probability
p ( w 2 ∣ w 1 , w 3 ) ⋅ P ( w 3 ∣ w 2 , w 4 ) p(w_2|w_1,w_3) \cdot P(w_3|w_2,w_4) p(w2∣w1,w3)⋅P(w3∣w2,w4)
This is an issue for infrequent words, since they don’t appear very often in a given context. As a result, the model will assign them a low probabilities.
For Skip-gram, it learns to predict the context given a word, or to maximize the following probability
P ( w 2 ∣ w 1 ) ⋅ P ( w 1 ∣ w 2 ) ⋅ P ( w 3 ∣ w 2 ) ⋅ P ( w 2 ∣ w 3 ) ⋅ P ( w 4 ∣ w 3 ) ⋅ P ( w 3 ∣ w 4 ) P(w_2|w_1) \cdot P(w_1|w_2) \cdot P(w_3|w_2) \cdot P(w_2|w_3) \cdot P(w_4|w_3) \cdot P(w_3|w_4) P(w2∣w1)⋅P(w1∣w2)⋅P(w3∣w2)⋅P(w2∣w3)⋅P(w4∣w3)⋅P(w3∣w4)
In this case, two words (one infrequent and the other frequent) are treated the same. Both are treated as word AND context observations. Hence, the model will learn to understand even rare words.
Skip-gram
Main idea of Skip-gram
-
Goal: The Skip-gram model aims to learn continuous feature representations for words by optimizing a neighborhood preserving likelihood objective.
-
Assumption: The Skip-gram objective is based on the distributional hypothesis which states that words in similar contexts tend to have similar meanings. That is, similar words tend to appear in similar word neighborhoods.
-
Algorithm: It scans over the words of a document, and for every word it aims to embed it such that the word’s features can predict nearby words (i.e., words inside some context window). The word feature representations are learned by optmizing the likelihood objective using SGD with negative sampling.
Skip-gram model formulation
Skip-gram learns to predict the context given a word by optimizing the likelihood objective. Suppose now we have a sentence
"I am writing a summary for NLP." \text{"I am writing a summary for NLP."} "I am writing a summary for NLP."
and the model is trying to predict context words given a target word “summary” with window size 2 2 2:
I am [ ] [ ] summary [ ] [ ] . \text {I am [ ] [ ] summary [ ] [ ] . } I am [ ] [ ] summary [ ] [ ] .
Then the model tries to optimize the likelihood
P ( "writing" ∣ "summary" ) ⋅ P ( "a" ∣ "summary" ) ⋅ P ( "for" ∣ "summary" ) ⋅ P ( "NLP" ∣ "summary" ) P(\text{"writing"}|\text{"summary"}) \cdot P(\text{"a"}|\text{"summary"}) \cdot P(\text{"for"}|\text{"summary"}) \cdot P(\text{"NLP"}|\text{"summary"}) P("writing"∣"summary")⋅P("a"∣"summary")⋅P("for"∣"summary")⋅P(&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8万+
8万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









