







RAG技术在24年开始火起来,所谓RAG就是增强检索,使得我们自己的数据内容挂载到LLM上,这样LLM可以基于我们的内部知识以及其自有知识来对话。使用RAG后我们的内部知识不需要出局,本地部署的RAG系统即可带来LLM+自有知识库的新体验。正如下面的这张图所示,RAG技术使得我们结合了自有的知识库以及LLM的知识库。

这样带来了两个非常显著优点:
1)安全性,不用担心自己的数据为LLM厂家获取;
2)时效性,上传后即可使用数据,不需要等LLM厂家更新模型;
从我们24年的工作来说,在企业内部的销售材料+RAG使得分布在全国的销售通过对话即可了解公司的新品、新品特性等。企业内部的投标文件编写,很多技术部分都是重复的,标书+RAG使得复用历史知识,不受人员的流失的影响。LLM在处理这类文本类的工作时表显相当不错,但在处理财务数字类的业务,还有一些不足。LLM天然的无法处理要求100%准确的业务场景。
当然从入门到精通这个话说得有一些大了,但我相信,接下来的这几期内容,会让你了解RagFlow的能力、核心流程、主要代码模块。我们选择RagFlow也是对比多个项目以及与原生的RAG基础工作流的使用效果进行了对比。本文适合企业IT部门、产品经理、研发一起来交流讨论。
1)安装部署运行RagFlow;
2)RagFlow应用场景体验;
3)RagFlow核心流程;
4)简单改造RagFLow。
欢迎加微信,建立联系:xingzhedanqing。
如果需要查看本期套的其它内容,请关注公号:AIGC中文站
在今天的分享中,我们的目标是在本地完成RagFlow的部署,对接QWEN大模型,解决部署过程中常见的各种问题,完测试性的进行一次对话。
目录
快速了解RagFlow
获取RagFlow
做好准备工作
开始安装依赖
运行
测试对话
-
快速了解一下RagFlow
当你已经在看我这篇内容时,我默认你至少已经知道什么是RAG了,我将不再对此概念作过多的解释。你可以看一下我的相关内容:
RagFlow是infinite团队的一个开源项目,是我使用下来比较符合我的期望的一个项目,先看一下其整体的工作流图,从左到右分为两个过程,第一个是对Document的处理,建立我们的数据库;第二步是面向Custom的一个检索过程,以及将检索的内容投喂给LLM进行生成。
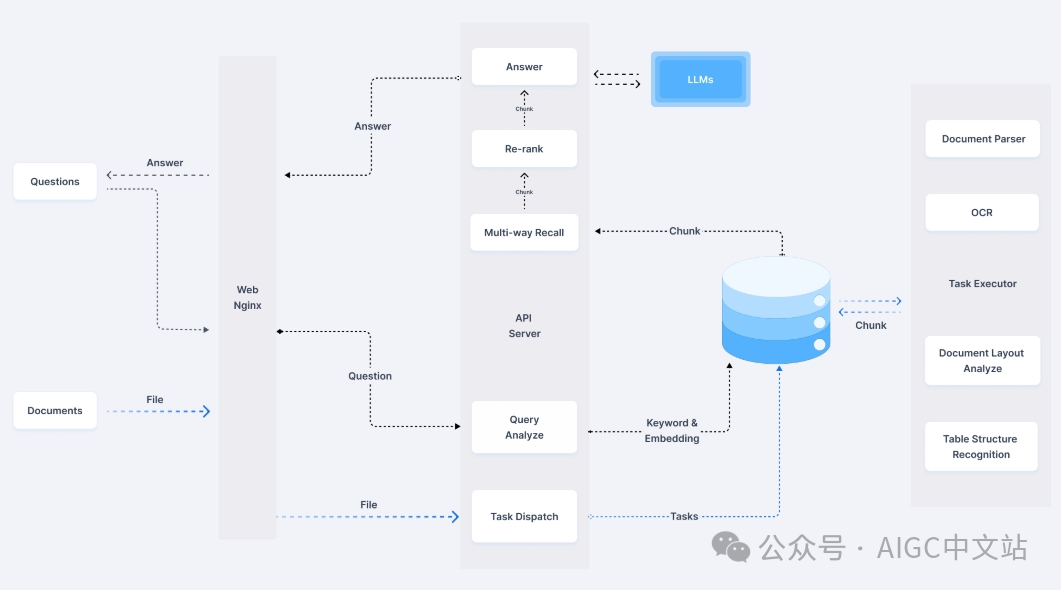
(RagFlow工作流图)
为什么我们选择RagFLow,因为他的一些特性:
多种输入知识处理方式:我们知道RAG有文本处理,和对话检索生成两个过程,在文本处理时,RagFlow有法律、论文、专利等多种处理模板,其OCR也是基于infinite团的深度识别框架完成,效果相当的出色;
检索过程的增强:使用了ES+向量库的方式混合检索,对两种方式的结果进行评分加权处理,这对比单一向量库检索的方式,结果的准确率高了不是太多;
权限角色:RagFlow自带了一个团队概念,团队可以邀请成员,对于一些简单的应用场景,这样的管理已经足够。当然,如果需要更复杂的权限管理,可以联系我们;
对话超长延迟加载:减少token的消耗;
检索结果带来源:可以查看来自那些文档,自行跳转查看原文档;
分段结果可查看:可以查看Chunk结果,帮助我们优化;
……
这些对于二次开发非常友好!
这里要对不熟悉RAG的同学们多说一句,RAG只是一套技术框架,是不包含LLM的,需要我们对接多种模型,完成embedding、生成等具体的功能。所以你会看到,在后面的过程中,我们需要申请QWEN或其它大模型的账号,获取对接的认证。
RagFlow有三个主要的模块:
1)web模块,也就是我们的界面部分;
2)Api Server 提供接口服务,我们常用的登录注册都由其完成。同时,AI部分的业务也由其先进行权限的处理,然后转交到业务模块处理;
3)Task Executor,是我们完成AI业务处理的模块,即切块、embedding、Retriver、生成等。
好了,现在我们对RagFlow有了一些基础的认识,知道其是一个RAG系统,知道有一些特性,知道由三个子模块组成。那么接下来,我们在本地的PyCharm中获取RagFlow代码。
-
获取RagFlow
infinite团队将RagFlow发布在了git:
https://github.com/infiniflow/ragflow
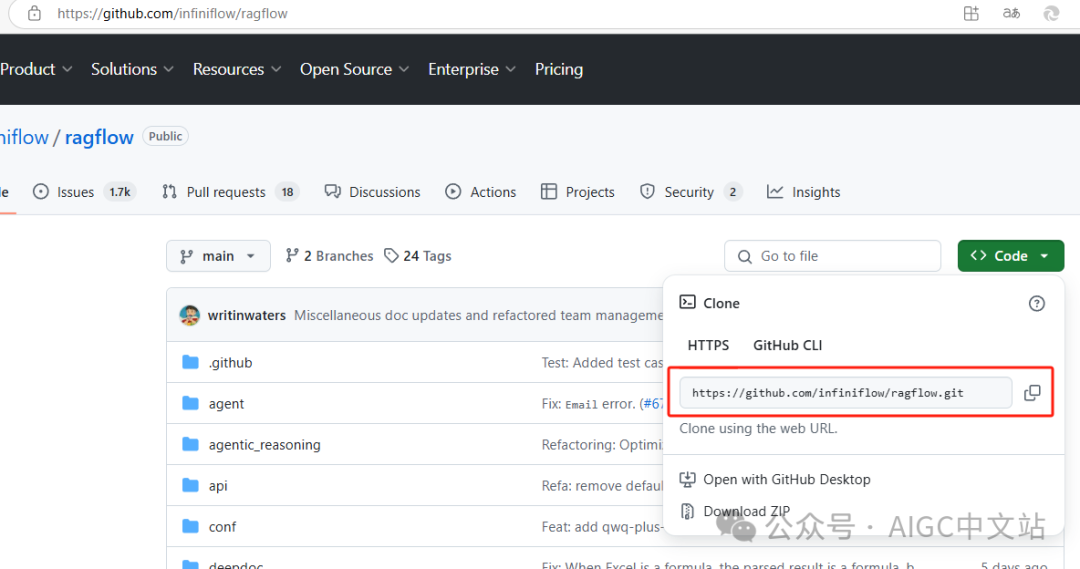
大家通过这个链接即可获取。如果你的网络无法获取,可以从我的网盘获取:

如果通过git获取,在我们的PyCharm等工具中,选择VCS获取,输入我们上一步中复制的链接:
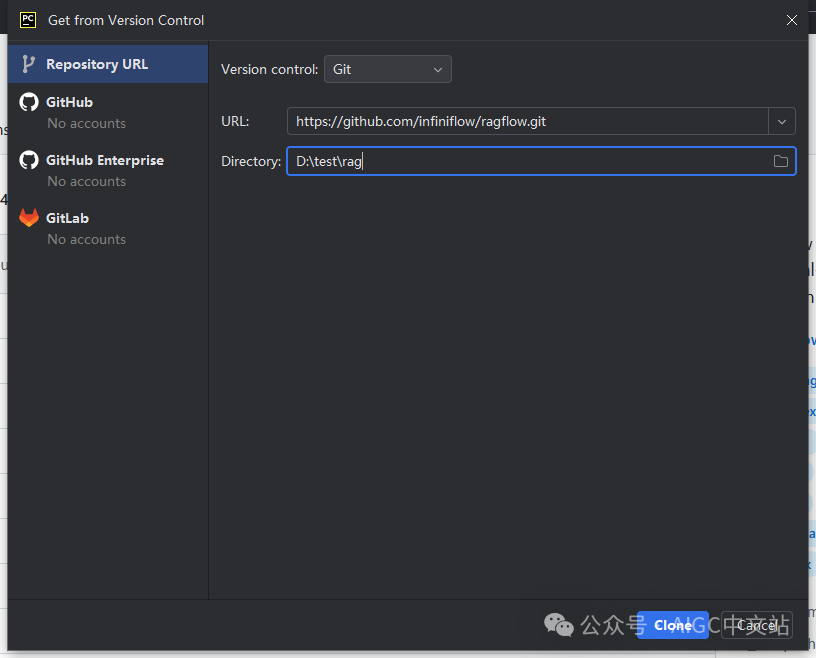
点击了clone后,就会下载代码到本地目录中。
如果是源码方式:
1、解压源代码
2、使用PyCharm打开项目即可
获取好代码后,你会在PyCharm中看到这样的内容:
好了,到这里我们完成了项目代码的导入,下一步,我们需要做一些配套的准备工作。
-
做好准备工作
RagFlow有多种安装方式,我用最原始的裸机安装的方式,当你学会了这,其它的方式也就手到擒来。这样的方式,便于我们进行下一步的改造。
这时,我们需要将PyCharm安装好。这是我们常用的Python IDE。
好的,做好了这些准备工作,让我开始吧。我们需要完成:
1)ES安装。RagFlow使用的全文检索工具,这会使用检索命中率更高;
2)MINIO安装。RagFlow使用的文本存储工具;
3)Redis安装。RagFlow的API Server与Task Executor两个进程间通信工具;
4)Mysql安装。业务数据库;
5)Node安装,web模块运行使用。
为了减少本文的篇幅,我将这四个安装的指南,放到了本次推送的其它几篇文章中。
1、ES安装
ES是全文检索工具,用于存储我们上传的文本。在前文我们已经说过,RagFlow使用了两种检索方式来实现更加精准的命中。安装方式,参看本次推送的另一篇《windows下ES安装》。
2、minio安装
minio是RagFlow使用的文档管理工具,我们上传的文档,如excle、doc、png等,都会
上传到这个工具中进行管理,而不是直接上传的到本地。安装方式,参看本次推送的另一篇《windows下minio安装)
3、Redis安装
RagFlow有两个进程,一个是一个web Server用来处理请求,另一个是task进程,进行文档的处理、检索等任务。两个进程的通信方式,就是通过Redis完成。So,这很重要。安装方式,参看本次推送的另一篇《windows下redis安装)
4、MySql安装
业务数据都放在了Mysql中,如团队及成员数据、知识库数据、对话数据等。Mysql太过于基础,这里我们就不讲怎么安装了。
5、Node安装
这个太基础了,我不作过多的说明,百度一下非常简单。前面我们说过由web等3个子模块组成,而web模块的运行需要node。
好了,到一步,我们完成了5个辅助工具的安装,没有这些,在启动时,是会报错的!
-
开始安装依赖
当你看到这里的时候,我相信你其实并没有安装上述的四个辅助工具,这里还可以再等等,但如果运行时还没有,那就启动不成功哦!
pycharm导入项目如果你能打开git,那么通过pycharm的CVS导入即可,如果无法打开git,从我的网盘下载了项目,那么解压后,在pycharm中打开这个项目即可。
1、初次运行时请配置好解释器
请确保你已经安装了Python和PyCharm,我使用了Python 3.10。
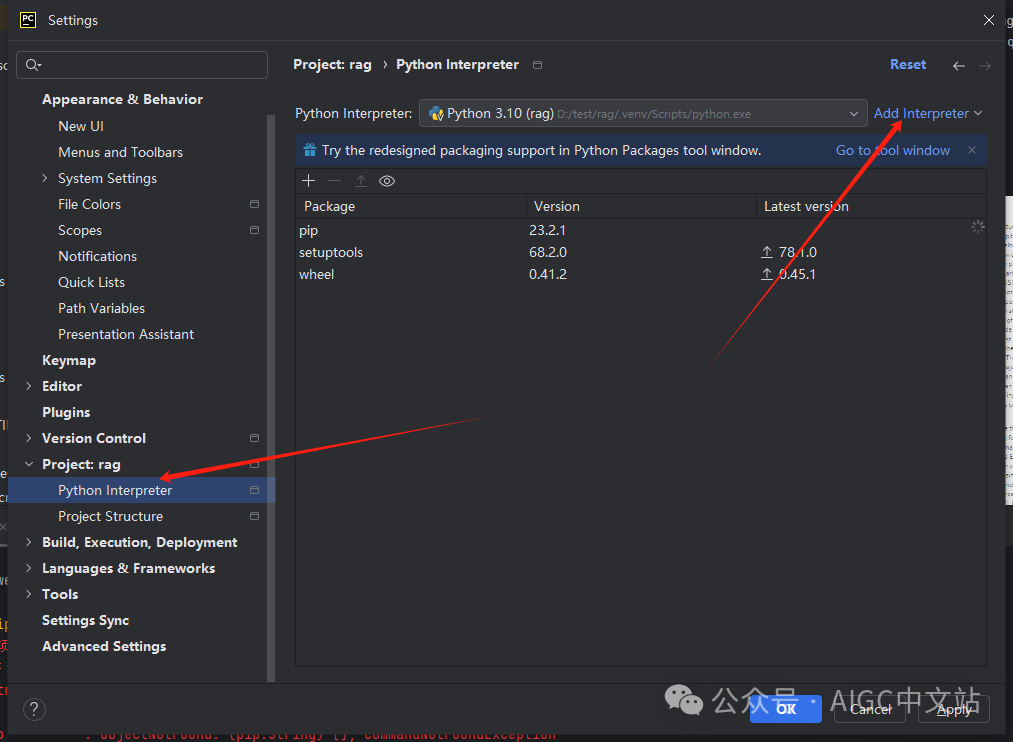
(初次运行需要先配置一个解释器)
配置好解释器后,最好重启一下你的PyCharm确保配置生效,我们遇到的很多莫名奇妙的问题都可以通过重启解决。
在过去的老版本中,我们使用pip install -r requirements.txt来安装全部的依赖。在新的版本中,其使用了pyproject.toml的方式管理依赖。
2、Poetry
pyproject.toml:这是一个更现代的、更强大的方式来管理Python项目的配置和依赖项。它是PEP 518和PEP 621中引入的标准,旨在提供一个统一的配置文件格式。pyproject.toml文件可以包含项目的元数据(如名称、版本和作者)、依赖项、构建系统配
置等。它通常与如Poetry和Flit等更现代的包管理和构建工具一起使用。
使用poetry包管理工具时,pyproject.toml文件内容大致如下:
[tool.poetry]name = "maxkb"version = "0.1.0"description = "智能知识库"authors = ["deanChang"]readme = "README.md"[tool.poetry.dependencies]python = "^3.11"django = "4.1.13"
在其中输入以下命令安装完成依赖安装(和requirements.txt有一点不一样):
python -m ensurepip --default-pip。(没有pip的情况)
输入以下命令安装项目的依赖项:pip install poetry。
进入项目的根目录,然后输入以下命令来安装项目:poetry install。
这样就能够完成pyproject.toml-based项目的安装了。
我使用了VPN进行安装,这个过程会需要一点时间,要耐心等一下。
这个过程不出意外的话,肯定要出意外,由于意外的内容篇幅不小,我放在了本次推送的另一篇中。《安装RagFlow过程中常见的异常》,在其中我罗列了如下的8个常见的问题:
1)安装VS studio2)huggingface_hub网络错误3)'gbk' codec can't decode 错误4)pipeline caused error: unknown command 'XADD'5)ntlk ValueError6)No module named 'past'解决方案7)onnx动态库加载失败8)nltl缺少错误
3、配置
还记得我们安装了mysql、es、minio、redis吗?我们需要在RagFlow中进行相应的配置。
配置文件在conf-service_conf.yaml文件中,我们需要将这里的mysql、es、minio、redis的账号密码配置为我们安装时设置的。
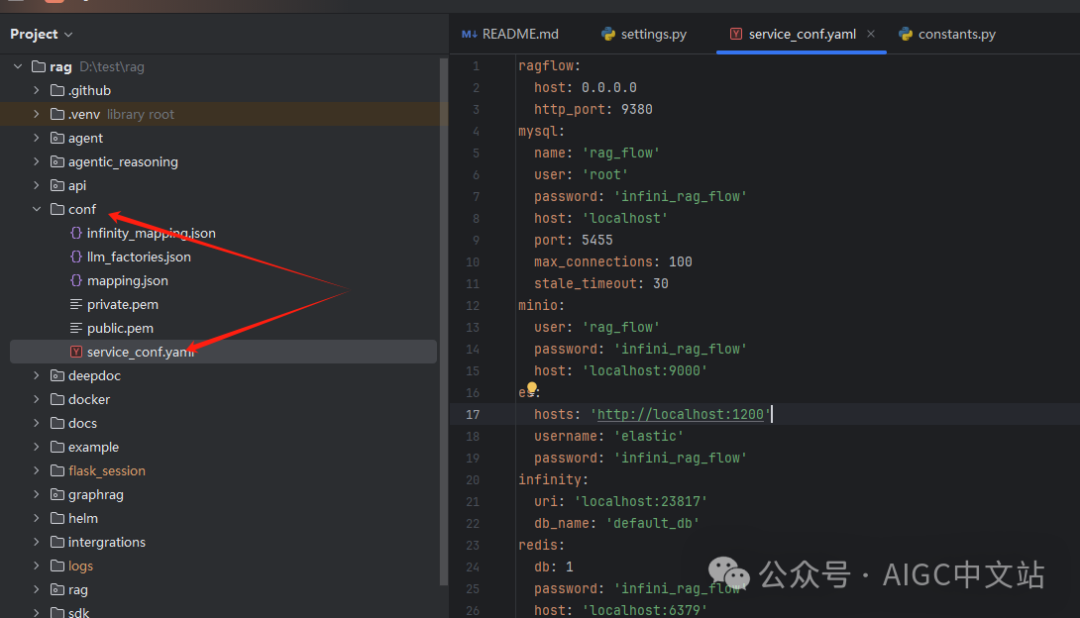
4、初始默认LLM配置
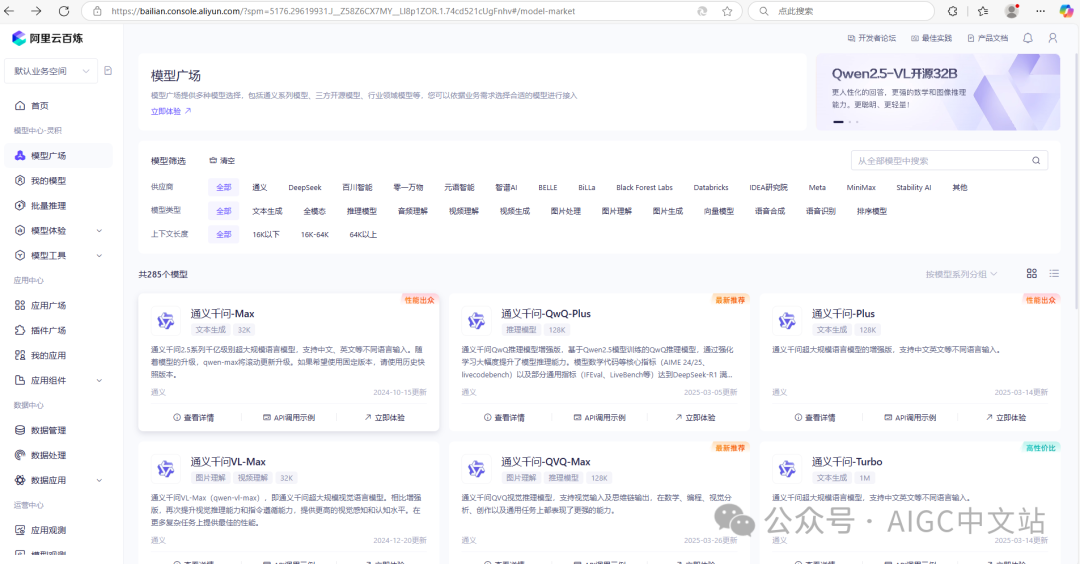
你当然可以不在这里进行配置,待系统运行后,在LLM管理界面中进行配置,这里是一个默认LLM配置。我在阿里百炼中获取api-key。
1)先登陆阿里百炼,并注册,界面如下:
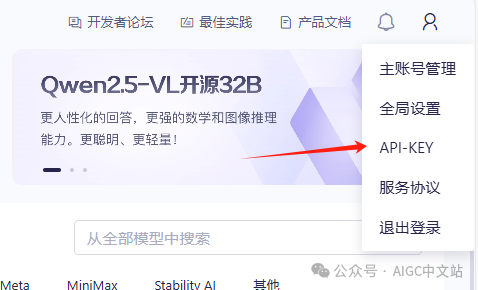
2)点击右上角的个人头像
选择API-KEY
3)创建KEY
如下图所示,创建一个key。
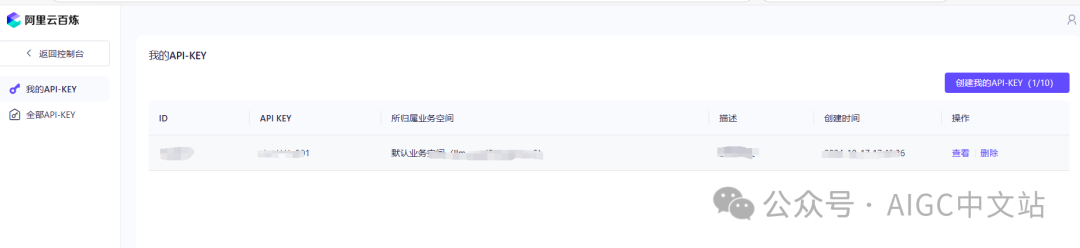
并将其配置到我们的配置文件中。这不是必须的,你可以在系统启动后在LLM管理中心配置。

-
运行
在这里我需要对RagFlow的三个主要模块进行再次说明web、Api Server、Task Executor,请你回忆一下,这在前面提过。因此,三个模块也需要单独启动。这个过程,我们需要启动四个部分:
1)打开es、minio;
2)WEB界面;
3)Server;
4)Task Executor。
下面让我们开始!
1、运行es、minio
怎么启动,在本次推送的另外几篇的安装中,也有说明,请自行查看。
启动成功后,如下图所示;
前面还提到过redis和mysql,这两个是系统服务,不需要启动。
2、运行WEB界面
我们可以打开CMD,进入到RagFlow目录中,然后进行web目录。这里就是web项目代码。我们使用了node,所以用npm工具进行包管理。如所图所示,使用cmd工具,进入到web目录中,npm install完成安装。
npm install
如果没有报错就安装完成。
这时,执行npm run dev
npm run dev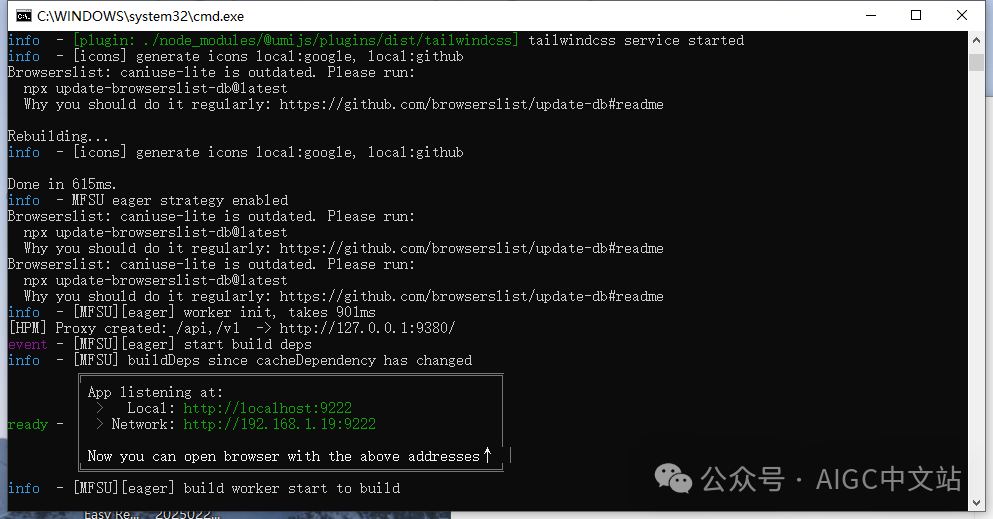
让我们复制这个链接到浏览器看看,哇,有界面了。但别激动,Api Server还没有启动,你什么也做不了。
(界面运行)
3、运行Server
启动Server后,我们即可登陆系统,只是还不能对话。
我们在pycharm中打开了代码,这里编辑一个启动的配置,这样启动时更方便,请注意是运行api/ragflow_server.py文件,这是api server的入口。如图所示:
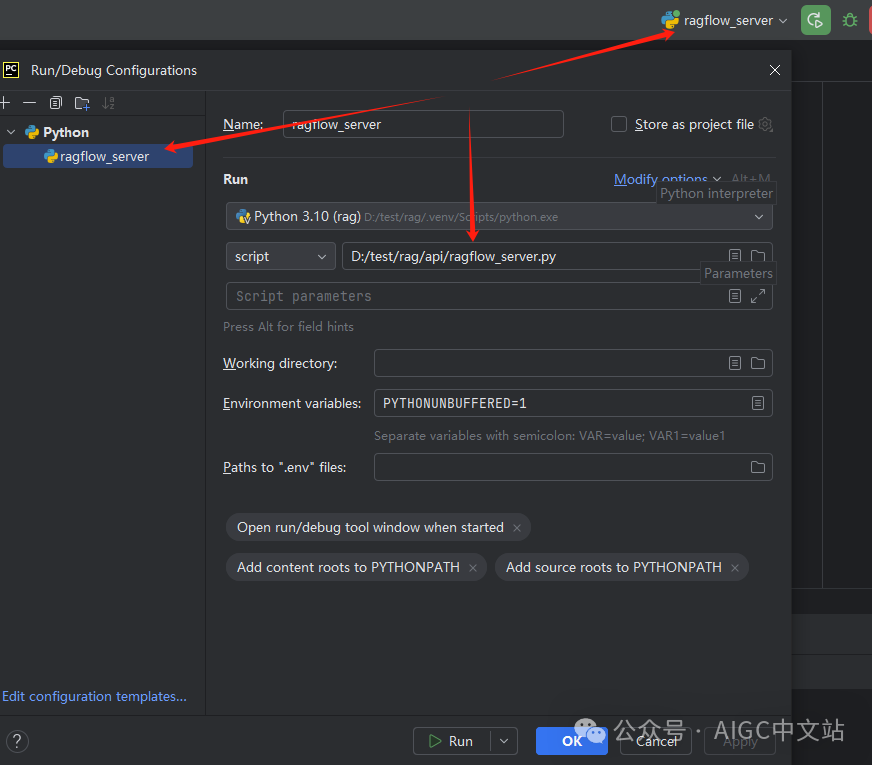
(启动配置)
初次运行时,会下载一些
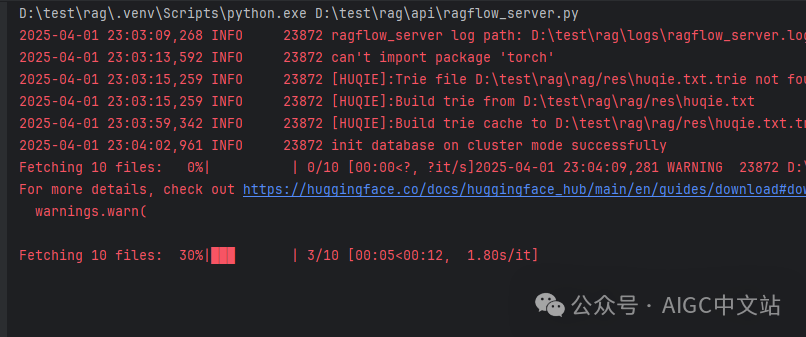
这里如果你没有vpn则需要配置国内的镜像,我在本次推送的另一篇,常见异常中有说明使用HF的镜像,请你前往查看。
待完成启动后,我们可以看到监听9380端口成功。
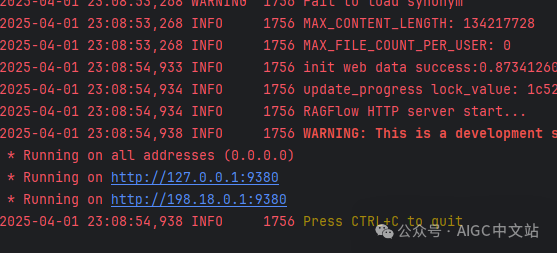
(启动成功)
到这里,Api Server启动成功,这里我们可以登陆系统了。
那么恭喜你,走到这一步,就算成功一大半了,那么我们来注册一个账号体验吧!在登陆界面中点击注册。
然后使用账号登陆:
当然,什么也没有!但我们离成功已经更近了一步。
4、运行task executor
和server类似,我们要配置一下,注意入口文件是rag/svr/task_executor.py。如图所示:
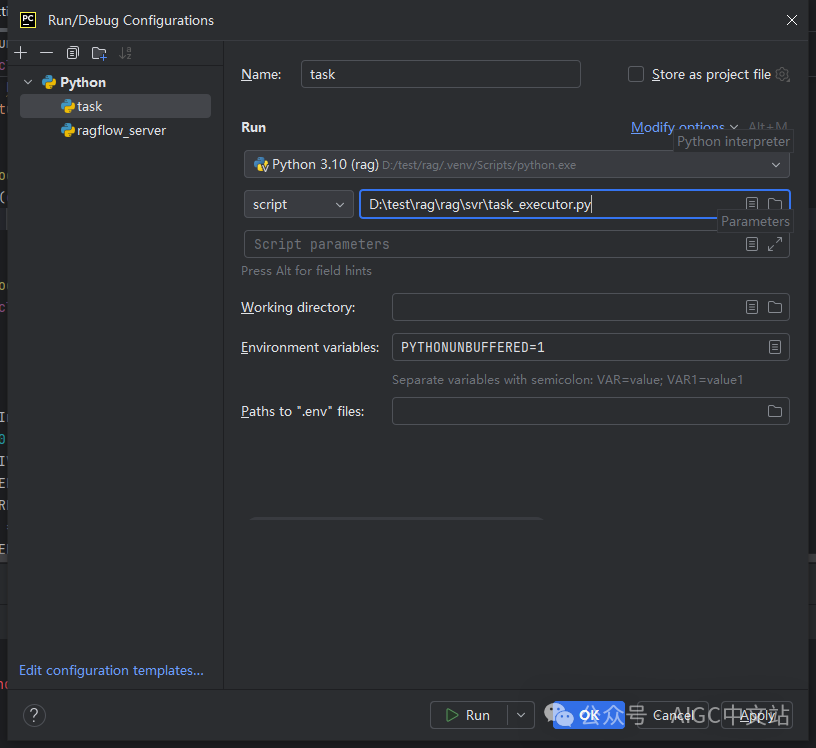
(启动配置)
然后运行,没提示失败就对了:
(启动成功)
配置一下模型,如果刚才我们在配置文件进行了配置,那么可以看到如下图所示,在added models中看到已经添加的qwen。
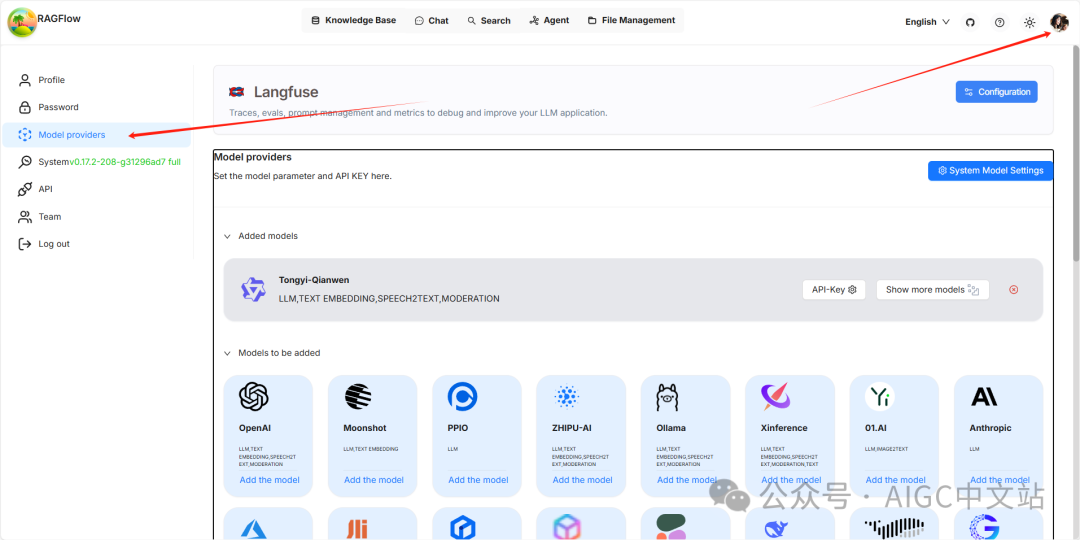
这时再点击System model setting,配置一下模型,前面说过在配置文件配置LLM不是必须的,因为你可以在此页面中配置,只是个人长期的习惯,要在配置文件中设置缺省。
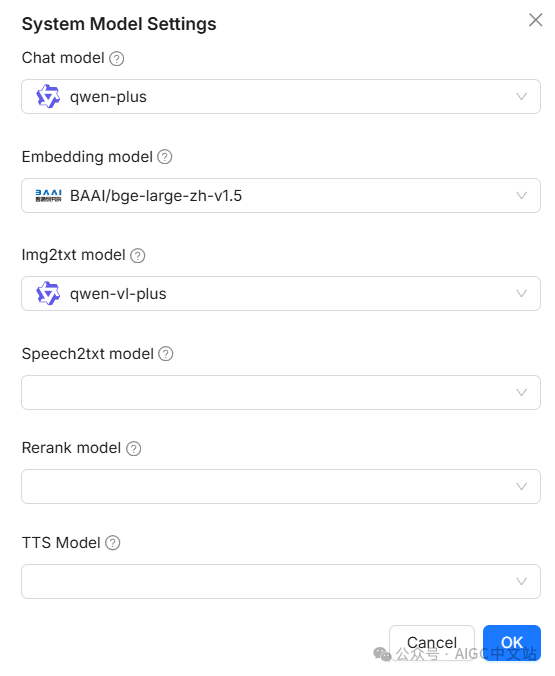
好了,我们的RagFlow已经完成了!
同学们,当我们到这里我们已经完成了RagFlow的本地安装了,为我们自己鼓掌吧,我们离RAG应用更近一步了。
-
测试对话
完成全部的安装启动后,我们点击 顶部菜单栏的Chat(聊天)。

然后选择创建一个助理
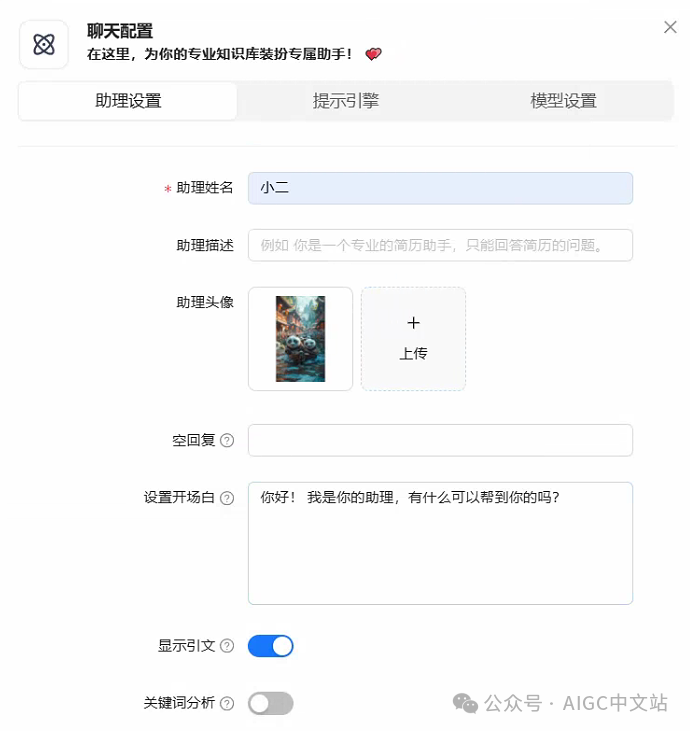
(建立bot)
创建助理后,记得新建一个对话。
(bot与对话)
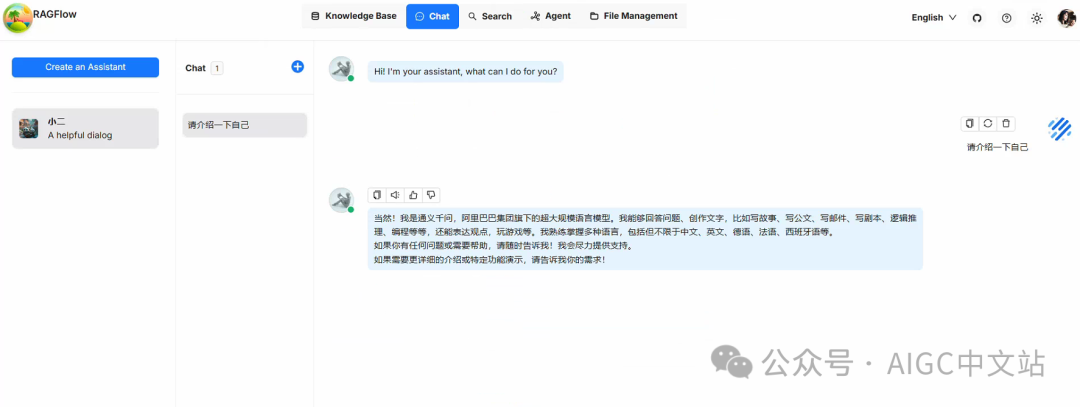
这时,我们问一下:“请介绍一下自己?”
(对话内容)
你看,我们配置的QWEN工作了!!!同样,你也还可以配置deepseek等其它的模型。
到这里我们的对话是LLM本身的知识在进行回答,因为我们还没有建立我们自己的知识库。走到这一步我们可以看到我们的系统已经部署完成,流程也是正确的。
今天的内容我们就先到这里,我相信你们可能会遇到一些其它的问题,我毕竟已经安装了很多次了,非常熟悉这个过程,很多的问题我在本地已经解决,所以没有再出现。
在下一次的分享中,我们将使用RagFlow来创建一个知识库,并完成一些有趣的操作体验。
有问题可以加我的微信哦:xingzhedanqing。
公号:AIGC中文站。
--完--

















 6484
6484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









