







本文使用Python第三方库实现了SMOTE过采样,用于解决数据样本不均衡的问题,本文适用于想要使用Python解决数据样本不平衡的问题但对于算法理论的理解要求不高的读者。
SMOTE算法解决的问题
对于我们真实世界中采集到的数据来说,我们想要把我们采集到的数据应用到我们的一些预测模型等应用场景时,如果直接采用这些数据可能会导致我们无法更好的完成目标任务。比如,我们想要实现一个预测算法来预测一个二分类问题,通过我们采集到的真实世界的数据完成模型的训练。但是,对于很多二分类问题来说,我们在真实世界采集到的数据可能会存在样本不均衡的问题,即属于两个分类的样本数量存在巨大差异,如果我们直接将这样的数据用于模型的训练,通过传统的机器学习的算法或者深度学习的算法训练出一个二分类预测模型,如果我们使用的数据存在严重的样本不均衡的情况,可能会导致模型学习到的结果更偏向于占更大比例的类别,而且训练出的模型通过我们同样不均衡的测试集甚至可以获得“更好的效果”,但是,在面对真实的数据时,可能会出现预测的准确度不够,假阴性率过低等问题。
针对这一问题,我们可以通过使用SMOTE算法解决样本不均衡的问题,通过SMOTE过采样方法合成更多的少数类样本,增加少数样本在数据集中的数量,让我们的模型学习到更多的少数类的特征,提高模型的鲁棒性,可以有效的降低假阴性率,提高模型的预测效果。
SMOTE算法的原理
这篇文章的重点是为一些想使用SMOTE算法的读者提供一个Python的代码参考,所以并不重点解释SMOTE算法的理论层面,这里仅进行一个简单的介绍。
SMOTE算法(Synthetic Minority Over-sampling Technique,虚拟少数类别过采样技术)可以简单的理解为通过现有的少数类的数据来生成更多的少数类的数据,在生成这些数据时并不会考虑原本数据集中的多数类的数据点。在数据的生成方面,SMOTE算法相较于原始的 随机过采样Random Over-Sampling算法相比还是存在一定的优势的。
随机过采样算法(Random Over-sampling)
随机过采样算法也是用于解决样本不均衡问题的方法,其实现十分简单,就是通过复制更多的少数类样本来达成数据集的平衡,但是通过该方法生成的数据可能会导致过拟合问题,同时,如果原数据集中存在少数类的噪声数据,这样的过采样方式可能会进一步的引入噪声,导致学习的模型效果无法达到预期。
SMOTE算法的流程
SMOTE算法有效的规避了一些上述算法存在的问题,其主要流程如下:
- 找到少数类的样本附近的k个少数类样本;
- 在这k个样本中随机选择一个样本;
- 在特征空间中这两个少数类样本之间随机选择点创建合成样本;
- 重复上述的过程直到数据集平衡。
其中k值一般默认为5,k值可以自行定义,但不宜过大或过小,而且要考虑到原数据集中少数样本的数量。如果k值过小可能会导致合成的数据的效果接近于随机过采样生成的数据的效果,如果k值过大会降低算法的效率,同时也增大了离群值影响合成数据的概率(即引入噪声的概率)。
在距离的定义上,一般采用欧式距离,当然我们在实现时也可以通过其他的距离计算方式来定义距离。
在数据的类型上,对于算法的理解来说,如果我们的数据是2个浮点数作为特征,1个二分类(可以理解成布尔型数据,即0或1)作为预测目标,将更容易理解SMOTE算法,即在样本点之间连线并随机在连线上点样本点,就完成了数据的合成。
实际上,我们很难讲我们采集到的数据全部化成浮点数,对于一些分类数据等我们会使用其他的数据类型来对他们进行表示:
- 对于多分类数据,我们可能会将这样的数据处理为整型数据,比如将患病处理为1-6的整型数据的分级;
- 对于二分类数据,我们一般会使用布尔型数据(0或1)代表两个类别。
对于这样的数据来说,我们可能就无法通过简单的在两个样本点之间随机选点得到合成数据,但是处理方式也相对简单,只需要在随机选点的基础之上为每个特征添加一个分类的阈值,将他们从合成的浮点型数据变回所需要的整型或是布尔型即可,比如对于布尔型数据来说,可以以0.5作为阈值,将他们分为0或1即可。
有些采集到的数据中可能还会存在字符串类型,但是通过上述的原理我们也能得知这样的算法实现很难生成字符串类型的样本点,如果想要使用SMOTE算法完成数据集的平衡,就需要提前对数据集中存在的字符串类型的数据进行预处理。
SMOTE算法的优劣
SMOTE算法相比其他的一些过采样方法存在一些优势,其在处理数据不平衡的问题时能够有效的扩充少数类的数据样本量,并且添加的数据样本是基于特征空间的随机插值,这样的方式既保证了不会简单的复制少数类的样本,具有一定的随机性,同时也保证了生成的样本具有少数类样本的基本特征。该算法在实现上也较为简单,效率较高。
SMOTE算法在实际的应用中也存在一些问题,比如在面对某些数据集时可能会存在对离群值比较敏感的情况,也有可能会导致模型的过拟合,当然,这些也是很多过采样方法存在的共性问题,需要在适当的范围内使用此类方法解决数据的不平衡问题。还有一点需要注意的是,SMOTE算法在处理多分类不平衡问题时的效果相较于处理二分类问题稍显逊色,其在二分类的问题上表现要更好。
SMOTE算法的实现
以下的部分为SMOTE算法通过Python三方库的直接实现,对于不需要了解算法原理仅需要使用SMOTE算法的读者可以直接阅读此部分。SMOTE算法的实现需要imblearn库,不会安装的读者安装方法可以参考该博客,SMOTE的代码实现如下:
# 引入三方库
import pandas as pd
from imblearn.over_sampling import SMOTE
# 数据预处理
data = pd.read_csv("此处为你的数据集的存储路径")
print(data.dtypes)
- 此处使用的数据集为csv格式,如果数据集为xlsx等格式可以通过excel或wps另存为csv格式。
- 此处会输出你的数据集中的数据类型,需要查看数据类型是否符合预期,数据类型大概可以遵循以下的原则:
- 对于只能取整数的数据,数据类型应为int64。
- 对于可以取到小数的数据,数据类型应为float64。
- 对于2分类的数据,数据类型应为bool。
我们在此处得到的输出格式大概如下:

拿上述数据作为例子,比如性别、是否抽烟、是否饮酒都是布尔型(二分类)数据,需要将他们从int转换为bool,转换方式如下:
data['sex'] = data['sex'].astype(bool)
data['smoking'] = data['smoking'].astype(bool)
data['drinking'] = data['drinking'].astype(bool)
同理,如果你的数据集中有其他需要转换的数据,只需要使用此方式进行转换:
data['列名'] = data['列名'].astype('目标数据类型')
# 其中目标数据类型为bool(布尔型)、int(整型)、float(浮点型)
在完成数据转换后可以再次使用print(data.dtypes)检查一下转换后的数据是否符合规则。而后,我们需要将我们的数据集分为特征和目标变量两部分,我们一般将需要预测的变量放在最后一列,使用如下语句进行分割,并统计不平衡数据的分布情况:
X_train, y_train = data.iloc[:, :-1], data.iloc[:, -1]
counts_1 = y_train.value_counts()
print('不平衡数据分布情况为')
print(counts_1)
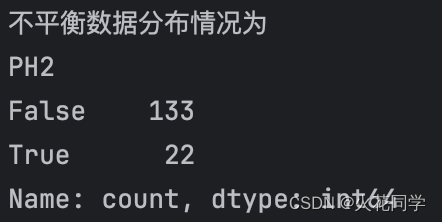
随后,我们使用SMOTE算法合成数据:
smt = SMOTE()
X_train_sm, y_train_sm = smt. fit_resample(X_train, y_train)
合成后查看合成后的数据分布情况:
counts_sm = y_train_sm.value_counts()
print('SMOTE(输出为data_smote)平衡数据计数')
print(counts_sm)
输出如下:
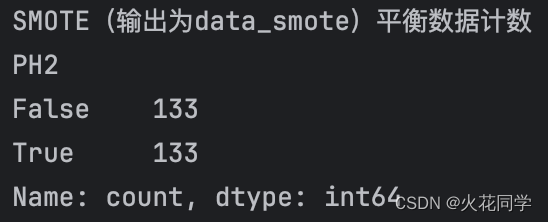
通过SMOTE完成了数据平衡,此时完成数据合成,只需将合成后的数据输出为新的csv即可。
data_sm = pd.concat([X_train_sm, y_train_sm], axis=1)
data_sm.to_csv('data_smote.csv', index=False)
数据命名为data_smote.csv存储在代码运行的路径下,此时smote算法全部完成,你可以通过生成的文件检查合成数据的情况。
全部代码
全部代码示例如下:
import pandas as pd
from imblearn.over_sampling import SMOTE
# 数据预处理
data = pd.read_csv("此处为你的数据集的存储路径")
print(data.dtypes)
#数据转换根据自己的数据集情况修改
data['sex'] = data['sex'].astype(bool)
data['smoking'] = data['smoking'].astype(bool)
data['drinking'] = data['drinking'].astype(bool)
data['列名'] = data['列名'].astype('目标数据类型')
# 其中目标数据类型为bool(布尔型)、int(整型)、float(浮点型)
#检查转换完的数据类型情况
print(data.dtypes)
X_train, y_train = data.iloc[:, :-1], data.iloc[:, -1]
counts_1 = y_train.value_counts()
print('不平衡数据分布情况为')
print(counts_1)
# SMOTE
smt = SMOTE()
X_train_sm, y_train_sm = smt. fit_resample(X_train, y_train)
# 合成后的数据集平衡情况
counts_sm = y_train_sm.value_counts()
print('SMOTE(输出为data_smote)平衡数据计数')
print(counts_sm)
data_sm = pd.concat([X_train_sm, y_train_sm], axis=1)
data_sm.to_csv('data_smote.csv', index=False)
结语
本文使用Python第三方库imblearn实现了SMOTE算法解决二分类问题的数据集不平衡的问题,简要介绍了SMOTE算法的基本原理,但并没有从理论层面严谨的进行讲解,仅针对想要使用SMOTE算法的读者在使用这个算法时需要了解的基础进行了介绍,同时在代码章节中实现了简单的SMOTE算法,供读者在处理自己的数据集时参考使用。
如果在阅读该博客时发现存在错误和瑕疵可以在评论区或私信博主提出问题或修改意见,如果存在其他的问题也可以和博主进行探讨。原创不易,如果觉得该博客对您有用可以点赞收藏,感谢您的支持。
原创博客,转载请注明出处。

















 589
589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









