







chapter 27 Multiple features
start to talk about a new version of linear regression,more powerful one that works with multiple variables or with multiple features.

Notation:
n = number of features
x(i) x ( i ) = input (features) of i th training example.
x(i)j x j ( i ) = value of feature j in i th training example.
Hypothesis:
hθ(x)=θ0+θ1x1+θ2x2+...+θnxn h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n
for convenience of notation ,define x0 x 0 = 1.
so
hθ(x)=θTx h θ ( x ) = θ T x
Multivariate linear regression.
chapter 28 Gradient descent for multiple variables
how to fit the parameters of that hypothesis.how to use gradient descent for linear regression with multiple features
Hypothesis: hθ(x)=θTx=θ0x0+θ1x1+...+θnxn) h θ ( x ) = θ T x = θ 0 x 0 + θ 1 x 1 + . . . + θ n x n )
Parameters: θ θ here is a n+1-dimensional vector.
Cost function:
J(θ)=12m∑mi=1(hθ(x(i))−y(i)) J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) )
Gradient descent:
Repeat{
θj:=θj−a∂∂θjJ(θ) θ j := θ j − a ∂ ∂ θ j J ( θ )
} (simultaneously update for every j=0,...,n j = 0 , . . . , n )
New algorithm(n>=1):
Repeat{
θj:=θj−a1m∑mi=1(hθ(x(i))−y(i)) θ j := θ j − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) )
}
θ0:=θ0−a1m∑mi=1(hθ(x(i))−y(i))x(i)0 θ 0 := θ 0 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i )
θ1:=θ1−a1m∑mi=1(hθ(x(i))−y(i))x(i)1 θ 1 := θ 1 − a 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 1 ( i )
chapter 29 Gradient descent in practice 1:feature scaling
practical tricks for making gradient descent work well
Feature Scaling:
Idea: Make sure features are on similar scale.

Get every feature into approximately a −1<=xi<=1 − 1 <= x i <= 1 range.
Mean normalization
Replace xi x i with xi−ui x i − u i to make features have approximately zero mean (Do not apply to x0=1 x 0 = 1 )
x1←x1−u1s1 x 1 ← x 1 − u 1 s 1 u1 u 1 is the average value of x1 in the training sets.
s1 s 1 is the range of values of that feature or standard deviation
chapter 30 Gradient descent in practice 2:learning rate
around the learning rate a a
- “Debugging “:How to make sure gradient descent is working correctly.
- How to choose learning rate

Declare convergence if J(θ) J ( θ ) decreases by less than 10−3 10 − 3 in one iteration.
but choose what this threshold is pretty difficult.So,in order to check your gradient descent has converged, actually tend to look at plots.
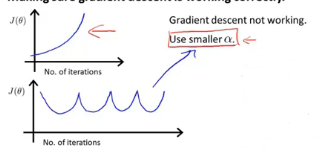
- For sufficiently small a a ,should decrease on every iteration.
- But if a a is too small,gradient descent can be slow to converge.
- if is too large ; J(θ) J ( θ ) may not decrease on every iteration ;may not converge.
chapter 31 Features and polynomial regression
the choice of features that you have and how you can get different learning algorithm

It is important to apply feature scaling if you’re using gradient descent to get them into comparable ranges of values.
broad choices in the features you use.

chapter 32 Normal equation
which for some linear regression problems ,will give us a much better way to solve for the optimal value of the parameters θ θ
Normal equation : Method to solve for θ θ analytically.


正规方程推到过程:https://zhuanlan.zhihu.com/p/22474562
矩阵求导:https://blog.csdn.net/nomadlx53/article/details/50849941
Gradient Descent and Normal Equation advantages and disadvantages :

The normal equation method actually do not work for those more sophisticated learning algorithms.
chapter 33 Normal equation and non-invertibility (optional)
what if XTX X T X is non-invertible?
- Redundant features (linearly dependent)
e g : x1 x 1 = size in feet 2 2 x2 x 2 = size in m 2 2
- too many features (e.g m<=n)
Delete some features , or use regularization.















 1301
1301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









