







 文章介绍了K-Means聚类算法的三个关键步骤:初始化聚类中心,计算样本点归属到最近的中心,以及迭代更新中心位置。通过实例演示了如何使用Python实现K-Means算法,并展示了在鸢尾花数据集上的聚类效果。
文章介绍了K-Means聚类算法的三个关键步骤:初始化聚类中心,计算样本点归属到最近的中心,以及迭代更新中心位置。通过实例演示了如何使用Python实现K-Means算法,并展示了在鸢尾花数据集上的聚类效果。
1.1-计算得到簇中心点
import numpy as np
@staticmethod
def centroids_init(data, num_clusters):
num_examples = data.shape[0] # 数据点的数量
random_ids = np.random.permutation(num_examples) # 随机排列数据点的索引
centroids = data[random_ids[:num_clusters], :] # 从随机排列的数据点中选择初始聚类中心
return centroids
@staticmethod
def centroids_compute(data, closest_centroids_ids, num_clusters):
num_features = data.shape[1]
cnum_features = data.shape[1] # 数据特征的数量
centroids = np.zeros((num_clusters, num_features)) # 存储新的聚类中心
for centroid_id in range(num_clusters):
closest_ids = closest_centroids_ids == centroid_id # 找到属于当前聚类中心的数据点
centroids[centroid_id] = np.mean(data[closest_ids.flatten(), :], axis=0) # 计算新的聚类中心作为所属数据点的平均值
return centroids这一部分的任务是初始化聚类中心和在每次迭代时更新聚类中心。
-
centroids_init(data, num_clusters)方法用于初始化聚类中心。它随机选择数据点作为初始聚类中心,并返回这些初始中心的坐标。 -
centroids_compute(data, closest_centroids_ids, num_clusters)方法用于计算新的聚类中心。它首先确定哪些数据点属于每个簇,然后计算每个簇的均值,将其作为新的聚类中心。
1.2-样本点归属划分
@staticmethod
def centroids_find_closest(data, centroids):
num_examples = data.shape[0] # 数据点的数量
num_centroids = centroids.shape[0] # 聚类中心的数量
closest_centroids_ids = np.zeros((num_examples, 1)) # 存储每个数据点所属的最近的聚类中心的ID
for example_index in range(num_examples):
distance = np.zeros((num_centroids, 1)) # 存储数据点与每个聚类中心的距离
for centroid_index in range(num_centroids):
distance_diff = data[example_index, :] - centroids[centroid_index, :] # 计算数据点与聚类中心的距离差
distance[centroid_index] = np.sum(distance_diff ** 2) # 计算欧氏距离的平方
closest_centroids_ids[example_index] = np.argmin(distance) # 找到最近的聚类中心的ID
return closest_centroids_ids这一部分的任务是确定每个样本点属于哪个簇。
centroids_find_closest(data, centroids)方法用于找到每个数据点所属的最近的聚类中心。对于每个数据点,它计算该点与所有聚类中心的距离,并确定最近的聚类中心,将其ID存储在closest_centroids_ids中。
1.3-算法迭代更新
class KMeans:
def __init__(self, data, num_clusters):
self.data = data
self.num_clusters = num_clusters
def train(self, max_iterations):
centroids = KMeans.centroids_init(self.data, self.num_clusters) # 初始化聚类中心
num_examples = self.data.shape[0] # 数据点的数量
closest_centroids_ids = np.empty((num_examples, 1)) # 存储每个数据点所属的最近的聚类中心的ID
for _ in range(max_iterations): # 迭代训练K均值模型
closest_centroids_ids = KMeans.centroids_find_closest(self.data, centroids) # 查找每个数据点所属的最近的聚类中心
centroids = KMeans.centroids_compute(self.data, closest_centroids_ids, self.num_clusters) # 计算新的聚类中心
return centroids, closest_centroids_ids # 返回最终的聚类中心和每个数据点所属的聚类中心ID这一部分包含主要的训练循环,用于迭代地更新聚类中心和样本点的归属划分。
- 在
train(max_iterations)方法中,首先初始化聚类中心,然后进入迭代循环。在每次迭代中,计算每个样本点属于哪个簇,然后根据新的归属划分计算新的聚类中心。这个过程重复了max_iterations次,然后返回最终的聚类中心和样本点的归属划分。
每个部分的实现流程都负责K均值算法的关键步骤,以确保通过迭代更新聚类中心和样本点的归属划分来找到数据的簇结构。在整个算法的运行过程中,这三个部分协同工作以完成聚类任务。
1.4-尾花数据集聚类任务
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from k_means import KMeans # 导入自定义的K均值聚类类
# 从CSV文件读取数据
data = pd.read_csv('../data/iris.csv')
# 不同鸢尾花种类的名称
iris_types = ['SETOSA', 'VERSICOLOR', 'VIRGINICA']
# 选择用于绘制的 x 轴和 y 轴特征
x_axis = 'petal_length'
y_axis = 'petal_width'
# 创建一个图形窗口
plt.figure(figsize=(12, 5))
# 在图形窗口中创建子图 1
plt.subplot(1, 2, 1)
# 对于每个鸢尾花种类,绘制散点图
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class'] == iris_type], data[y_axis][data['class'] == iris_type], label=iris_type)
plt.title('label known') # 设置子图标题
plt.legend() # 添加图例
# 在图形窗口中创建子图 2
plt.subplot(1, 2, 2)
# 绘制未知标签的所有数据点的散点图
plt.scatter(data[x_axis][:], data[y_axis][:])
plt.title('label unknown') # 设置子图标题
plt.show() # 显示图形
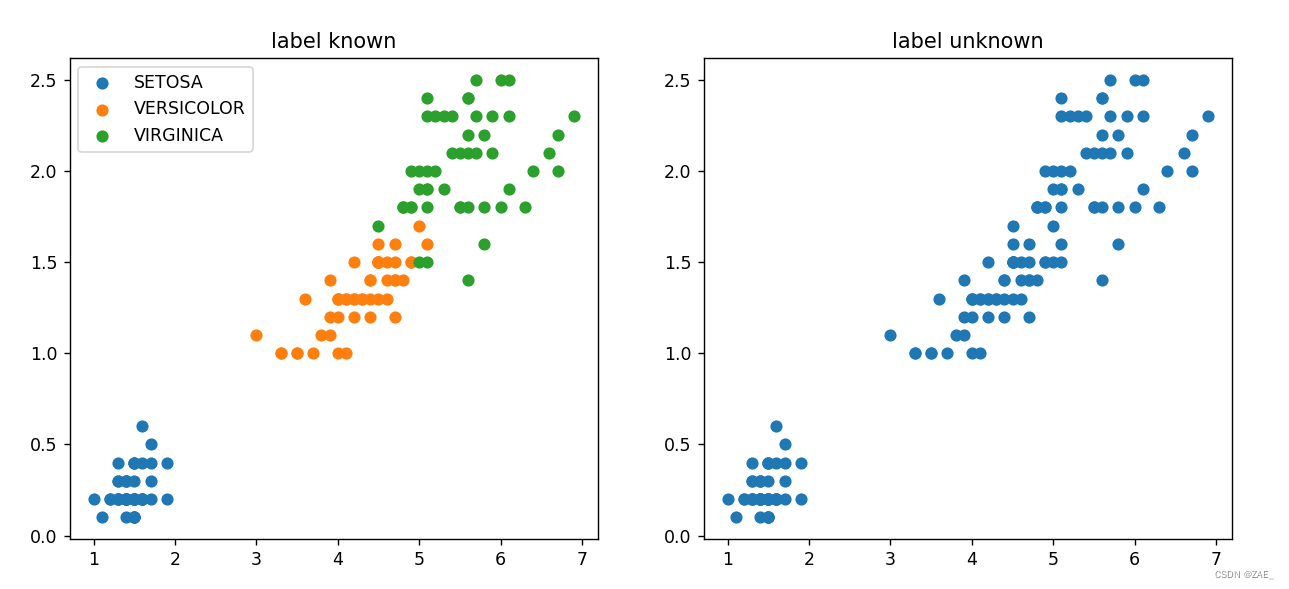
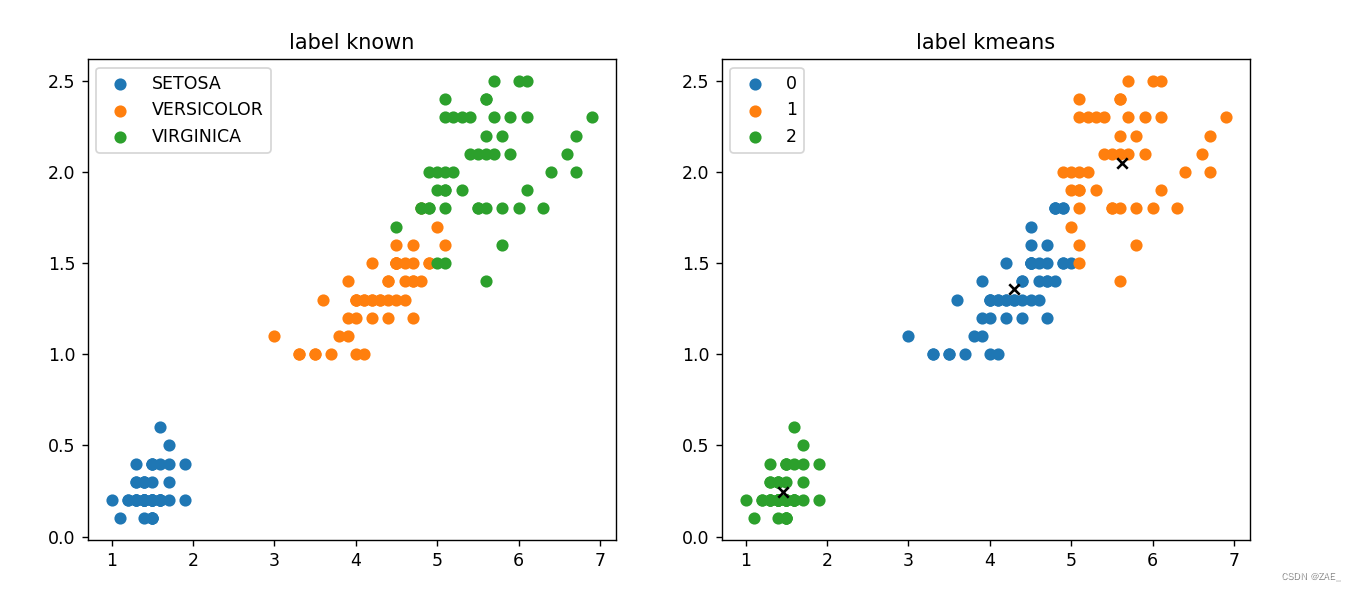
1.5-聚类效果展示
# 获取数据集中的样本数量
num_examples = data.shape[0]
# 从数据集中选择指定的特征列,并将其变换为 NumPy 数组
x_train = data[[x_axis, y_axis]].values.reshape(num_examples, 2)
# 指定K均值聚类所需的参数
num_clusters = 3 # 聚类簇的数量
max_iterations = 50 # 最大迭代次数
# 创建K均值聚类对象,并传入训练数据
k_means = KMeans(x_train, num_clusters)
# 训练K均值模型,获取最终的聚类中心和每个样本点所属的聚类簇
centroids, closest_centroids_ids = k_means.train(max_iterations)
# 创建一个图形窗口
plt.figure(figsize=(12, 5))
# 在图形窗口中创建子图 1
plt.subplot(1, 2, 1)
# 对于每个鸢尾花种类,绘制已知标签的散点图
for iris_type in iris_types:
plt.scatter(data[x_axis][data['class'] == iris_type], data[y_axis][data['class'] == iris_type], label=iris_type)
plt.title('label known') # 设置子图标题
plt.legend() # 添加图例
# 在图形窗口中创建子图 2
plt.subplot(1, 2, 2)
# 针对每个聚类簇绘制散点图
for centroid_id, centroid in enumerate(centroids):
current_examples_index = (closest_centroids_ids == centroid_id).flatten()
plt.scatter(data[x_axis][current_examples_index], data[y_axis][current_examples_index], label=centroid_id)
# 在图中标记聚类中心点
for centroid_id, centroid in enumerate(centroids):
plt.scatter(centroid[0], centroid[1], c='black', marker='x')
plt.legend()
plt.title('label kmeans') # 设置子图标题
plt.show() # 显示图形


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









