






基于1DCNN/CResNet/BiGRU三种分类模型的轴承缺陷检测
写在前面
历时三个多周终于把这个任务做的比较完美了。
三周前我把样本当音频用Mel和mfcc的频谱图去做,得到的结果看起来那叫一个好,结果听老师一说才意识到没进行数据处理,而且应该当作振动强度信号去做,让我第一版直接白给…
后来听老师的给数据替换异常值、去趋势化,再用常见的深度学习模型,比如MLP、LSTM、CResNet、GRU、Attention都试过,发现准确率高不起来还忽上忽下,又将数据样本进行扩充,这才稳定了一些。
但这时候准确率还是上不去,又用了小波变换提取高频特征,发现准确率就上去一点。网上搜了搜,发现很多用1D卷积的,于是我也在模型前添加了一层,发现准确率直接接近100%,甚至直接叠两层1D卷积效果都杠杠的。把第一层1D卷积打印出来发现,原理其实和用图谱去做差不多,CNN提取特征真的强!
最后三种模型训练得到的在验证集上的准确率都在97%以上,但对测试集预测得到的结果里,各类别之间还是有一个两个的差异,不过对应类别的分布概率大体相同没啥问题😎。
目录
一、数据分析
import os
import seaborn as sns
import pandas as pd
import numpy as np
import torch
import math
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
from sklearn.model_selection import train_test_split
font_path = './MSYH.TTC' # 设置字体文件路径
font_prop = FontProperties(fname=font_path, size=14) # 设置图形大小和字体
df = pd.read_csv('train.csv') # 读取CSV文件
data = df.drop(columns=['label']).astype(float).values # 其他列是特征
print(data.shape)
(96, 40960)
1.1 轴承状态分布饼状图
# 根据标签画轴承状态分布饼状图的函数
def plot_label_distribution(df, title="轴承状态分布"):
label_counts = df['label'].value_counts().reset_index() # 统计label列的值
label_counts.columns = ['label', 'number']
def func(pct, allvalues): # 定义自定义标签格式的函数
absolute = int(pct/100.*sum(allvalues))
return f"{absolute}\n{pct:.1f}%"
colors = ['#FF3030', '#436EEE', '#FFA500', '#FA8072'] # 橙、红、蓝、绿
plt.figure(figsize=(4, 4)) # 绘制饼状图
plt.pie(label_counts['number'], labels=label_counts['label'], autopct=lambda pct: func(pct, label_counts['number']),
startangle=90, colors=colors)
plt.legend(title='Label', loc='upper left', bbox_to_anchor=(1, 0.5)) # 添加图例
plt.title(title, fontproperties=font_prop, fontsize=14) # 添加标题
plt.show()
plot_label_distribution(df, "原始数据轴承状态分布")

1.2 轴承状态分类表
# 设置显示的最大行和列
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', 100) # 适当调整宽度
grouped = df.groupby('label').apply(lambda x: pd.Series({'索引序号': x.index.tolist()})) # 分组并输出每个label的索引序号和第一列的值
grouped.reset_index(inplace=True) # 重新设置索引
grouped # 输出表格形式
| label | 索引序号 | |
|---|---|---|
| 0 | inner | [0, 1, 2, 3, 5, 6, 11, 15, 17, 21, 23, 28, 38, 41, 42, 58, 70, 75, 79, 80, 83, 85, 87, 88] |
| 1 | normal | [8, 12, 13, 14, 18, 20, 25, 26, 32, 35, 36, 39, 43, 45, 56, 57, 60, 61, 66, 77, 78, 82, 89, 90] |
| 2 | outer | [4, 19, 27, 30, 31, 34, 37, 40, 44, 46, 51, 53, 59, 63, 64, 68, 71, 72, 74, 84, 86, 91, 92, 94] |
| 3 | roller | [7, 9, 10, 16, 22, 24, 29, 33, 47, 48, 49, 50, 52, 54, 55, 62, 65, 67, 69, 73, 76, 81, 93, 95] |
二、数据增强
将原长度为40960的一个样本拆成了8分长度为5000的新样本,将原来的96个长度为40960的原始样本,拆为了768个长度为5000的新样本。
-
滑动窗口: 在原始数据上设置了一个长度为5000的滑动窗口,每次在一个长度为40960的样本序列上取长度为5000的新序列,将这个新序列保存为新样本,并且设置了一个防越界处理,确保每个窗口内都有长度为5000的数据,算下来就是将原长度为40960的一个样本拆成了8分长度为5000的新样本,舍弃剩余的长度为960的数据。
-
标签复制: 对于每个新序列,都使用和当前样本相同的标签,即标签数据也等量且对应进行扩充了。
-
保存为CSV: 把这些增强后的数据保存为了enhanced_data.csv文件,除了用来验证一下没啥用处。
%%time
# 对数据进行增强函数
def enhance_data(data, original_sequence_length, new_sequence_length):
enhanced_data = [] # 初始化增强后的数据和标签列表
enhanced_labels = []
for i in range(len(data)): # 遍历原始数据集
sequence = data[i] # 获取当前序列和对应的标签
label = df.iloc[i, 0]
# 在原始序列上滑动窗口,每次取新序列长度的数据进行增强
for j in range(0, original_sequence_length, new_sequence_length):
if j + new_sequence_length <= original_sequence_length: # 确保窗口不会越界
enhanced_data.append(sequence[j:j+new_sequence_length])
enhanced_labels.append(label) # 将新序列和标签添加到增强后的数据和标签列表中
enhanced_data = np.array(enhanced_data) # 将增强后的数据和标签转换为NumPy数组
enhanced_labels = np.array(enhanced_labels)
return enhanced_data, enhanced_labels
original_sequence_length = 40960 # 设定原始序列长度和新的序列长度
new_sequence_length = 5000
enhanced_data, enhanced_labels = enhance_data(data, original_sequence_length, new_sequence_length) # 进行数据增强
print("原始数据维度:", data.shape) # 打印增强后的数据集维度
print("增强后的数据维度:", enhanced_data.shape)
# 将增强后的数据集保存为新的CSV文件
enhanced_df = pd.DataFrame(data=enhanced_data)
enhanced_df['label'] = enhanced_labels
enhanced_df.to_csv('enhanced_data.csv', index=False)
原始数据维度: (96, 40960)
增强后的数据维度: (768, 5000)
CPU times: total: 1.56 s
Wall time: 2.67 s
# 可再次读入查看数据增强后保存文件的信息。
df_en = pd.read_csv('enhanced_data.csv') # 读取CSV文件
num_rows, num_columns = df_en.shape # 输出行列信息
print(f"该CSV文件有{num_rows}行,{num_columns}列。")
该CSV文件有768行,5001列。
2.1 数据增强后_轴承状态分布饼状图
# 传入df_en查看数据增强后的轴承状态分布,
plot_label_distribution(df_en,"数据增强后_轴承状态分布")

2.2 数据增强后_轴承状态分类表
# 设置显示的最大行和列
pd.set_option('display.max_rows', None)
pd.set_option('display.max_columns', None)
pd.set_option('display.max_colwidth', 300) # 适当调整宽度
grouped = df_en.groupby('label').apply(lambda x: pd.Series({'索引序号': x.index.tolist()})) # 分组并输出每个label的索引序号和第一列的值
grouped.reset_index(inplace=True) # 重新设置索引
grouped # 输出表格形式
| label | 索引序号 | |
|---|---|---|
| 0 | inner | [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 88, 89, 90, 91, 92, 93, 94, 95, 120, 121, 122, 123, 124, 125, 126, 127, 136, 137, 138, 139, 140, 141, 142, 143, 1... |
| 1 | normal | [64, 65, 66, 67, 68, 69, 70, 71, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 144, 145, 146, 147, 148, 149, 150, 151, 160, 161, 162, 163, 164, 165, 166, 167, 200, 201, 202, 203, 204, 205, 206, 207, 208, 209, 210, 211, 212, 21... |
| 2 | outer | [32, 33, 34, 35, 36, 37, 38, 39, 152, 153, 154, 155, 156, 157, 158, 159, 216, 217, 218, 219, 220, 221, 222, 223, 240, 241, 242, 243, 244, 245, 246, 247, 248, 249, 250, 251, 252, 253, 254, 255, 272, 273, 274, 275, 276, 277, 278, 279, 296, 297, 298, 299, 300, 301, 302, 303, 320, 321, 322, 323, 324... |
| 3 | roller | [56, 57, 58, 59, 60, 61, 62, 63, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 128, 129, 130, 131, 132, 133, 134, 135, 176, 177, 178, 179, 180, 181, 182, 183, 192, 193, 194, 195, 196, 197, 198, 199, 232, 233, 234, 235, 236, 237, 238, 239, 264, 265, 266, 267, 268, 269, 270, 271,... |
保存增强数据与标签序列为npz文件
读入原始csv数据和数据增强操作比较费时,所以将处理好的数据与标签保存为npz文件,方便重复使用。
def label_to_array(data):
labels = []
for i in range(len(data)):
labels.append(data.iloc[i, 0]) # 提取第一列标签值
return np.array(labels)
# 使用振动信号的数据处理
labels = label_to_array(df_en)
# 将增强后的数据和标签保存为NumPy的压缩文件(.npz格式)
np.savez('data_and_labels_enhanced.npz', data=enhanced_data, labels=enhanced_labels)
三、数据预处理
3.1 数据读取
从上面保存的增强数据与标签序列的npz文件中读取数据
loaded_data = np.load('data_and_labels_enhanced.npz')
data = loaded_data['data']
labels = loaded_data['labels']
print("data维度:", data.shape)
print("labels维度:", labels.shape)
data维度: (768, 5000)
labels维度: (768,)
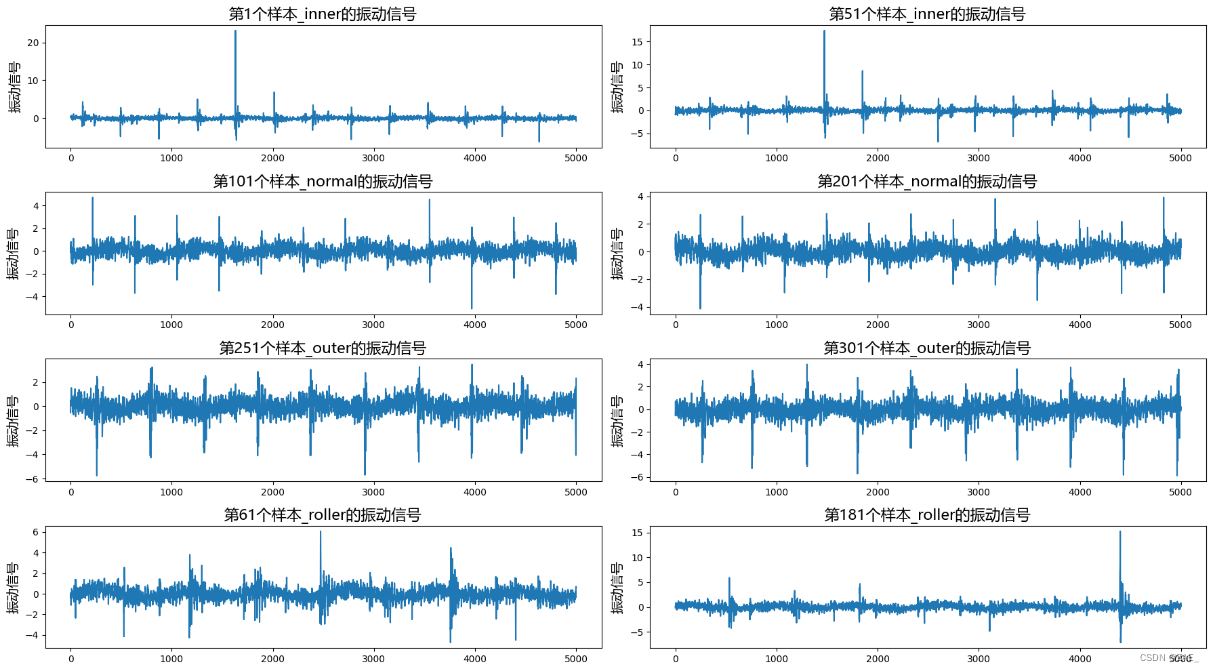
增强后数据data的可视化
此增强后数据data是从原始数据截取的
selected_rows_indices = [0, 50, 100, 200, 250, 300, 60, 180]
num_cols = 2
num_rows = (len(selected_rows_indices) + num_cols - 1) // num_cols
plt.figure(figsize=(18, 2.5 * num_rows))
for i, index in enumerate(selected_rows_indices):
vibration_data = data[index]
label_value = labels[index]
plt.subplot(num_rows, num_cols, i+1)
plt.plot(vibration_data)
plt.title(f"第{index+1}个样本_{label_value}的振动信号", fontproperties=font_prop, fontsize=16)
plt.xlabel("", fontproperties=font_prop, fontsize=14)
plt.ylabel("振动信号", fontproperties=font_prop, fontsize=14)
plt.tight_layout()
plt.savefig("增强后数据data的可视化.jpg")
plt.show()
3.2 替换异常值
- 为什么要替换异常值:
1.振动信号通常包含了机械系统的运行状态信息,而异常值可能是由于故障、噪音或其他干扰引起的。
2.替换异常值的目的在于平滑信号,使其更符合正常的振动模式,同时确保分析结果更加稳定和可靠。
3.对于振动信号来说,过大或过小的异常值可能大致后续时域或频域分析等操作的结果出现较大干扰,影响对系统状态的准确理解。
- 替换异常值具体操作:
1.遍历数据的每一行,计算每行的均值和标准差。
2.对于每个元素,如果其值超过该行均值加两倍标准差,就用该行均值加一个标准差来替代;
3.如果元素值低于该行均值减两倍标准差,就用该行均值减一个标准差来替代。
通过相对较小的值替代异常值,以平滑数据并减小异常值对整体影响。
# 将值大/小于“均值 ± 2*标准差”的认定为异常值,使用“均值 ± 1*标准差”进行替换,折线图看起来效果最好
def remove_outliers(data):
data_re = np.copy(data) # 创建数据的副本,以免修改原始数据
for i in range(data.shape[0]): # 遍历数据的每一行
row_mean = np.mean(data[i, :]) # 计算当前行的均值和标准差
row_std = np.std(data[i, :])
for j in range(data.shape[1]): # 遍历当前行的每个元素
if data[i, j] > row_mean + 2 * row_std: # 如果元素值大于均值加两倍标准差
data_re[i, j] = row_mean + 1 * row_std # 将元素值设置为均值加一个标准差
elif data[i, j] < row_mean - 2 * row_std: # 如果元素值小于均值减两倍标准差
data_re[i, j] = row_mean - 1 * row_std # 将元素值设置为均值减一个标准差
return data_re
data_re = remove_outliers(data) # 传入数据data_window,并将结果保存在data_re中
print("data_re维度:", data_re.shape)
data_re维度: (768, 5000)
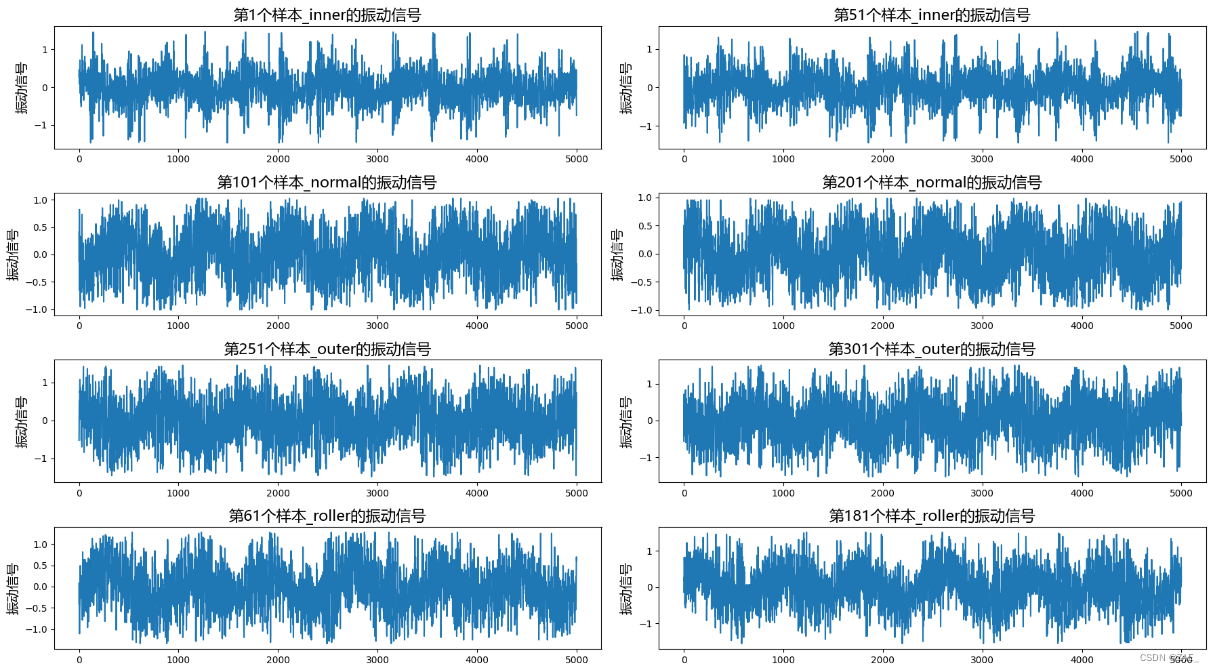
替换异常值后data_re的可视化
selected_rows_indices = [0, 50, 100, 200, 250, 300, 60, 180]
num_cols = 2
num_rows = (len(selected_rows_indices) + num_cols - 1) // num_cols
plt.figure(figsize=(18, 2.5 * num_rows))
for i, index in enumerate(selected_rows_indices):
vibration_data = data_re[index]
label_value = labels[index]
plt.subplot(num_rows, num_cols, i+1)
plt.plot(vibration_data)
plt.title(f"第{index+1}个样本_{label_value}的振动信号", fontproperties=font_prop, fontsize=16)
plt.xlabel("", fontproperties=font_prop, fontsize=14)
plt.ylabel("振动信号", fontproperties=font_prop, fontsize=14)
plt.tight_layout()
plt.savefig("替换异常值后data_re的可视化.jpg")
plt.show()
3.3 去趋势化
- 为什么要去趋势化值:
-
振动信号有时会混入长期的趋势变化。这种趋势可能来自于温度变化、设备老化、或者其他长时间尺度上的影响。
-
从上面的“3.2替换异常值后data_re的可视化”的图中可以很明显看出数据确实存在长时间周期趋势,且并不属于振动信号特征。
-
去趋势化的目的是消除这些长期趋势,使得信号更加集中在短期内的振动和波动,这个短期时间的设定可以取轴承周期长度。
-
去趋势化有助于提高信号的稳定性和可靠性,以便更精确地进行故障诊断和性能评估。
- 去趋势化值具体操作:
-
分段处理: 将时间序列按指定周期为4进行分段,每段称为一个数据段。
-
去趋势化: 对每个数据段,减去该段数据的平均值,以消除周期性趋势。
-
整合结果: 将去趋势化后的各数据段连接起来,形成整体去趋势的时间序列。
# 去除数据的趋势的函数
def detrend_data(data_re, period=4):
data_detrend = np.zeros_like(data_re) # 创建一个和输入数据相同维度的零数组,用于存储去趋势后的数据
for i in range(data_re.shape[0]): # 遍历输入数据的每一行
timeseries = data_re[i] # 获取当前行的时间序列
detrended = [] # 用于存储去趋势后的时间序列
for j in range(0, len(timeseries), period): # 遍历时间序列,按指定周期进行分段处理
start = j
end = min(j + period, len(timeseries))
segment = timeseries[start:end] # 获取当前周期内的数据段
detrended.append(segment - np.mean(segment)) # 将数据段去趋势化,并添加到detrended列表中
detrended = np.concatenate(detrended) # 将去趋势后的数据段连接起来,形成整体去趋势的时间序列
data_detrend[i, :len(detrended)] = detrended # 将去趋势后的时间序列存储到相应的行中
return data_detrend # 返回去趋势后的数据
data_detrend = detrend_data(data_re, period=4) # 使用detrend_data函数去趋势化输入数据data_re,指定周期为4
print("data_detrend维度:", data_detrend.shape)
data_detrend维度: (768, 5000)
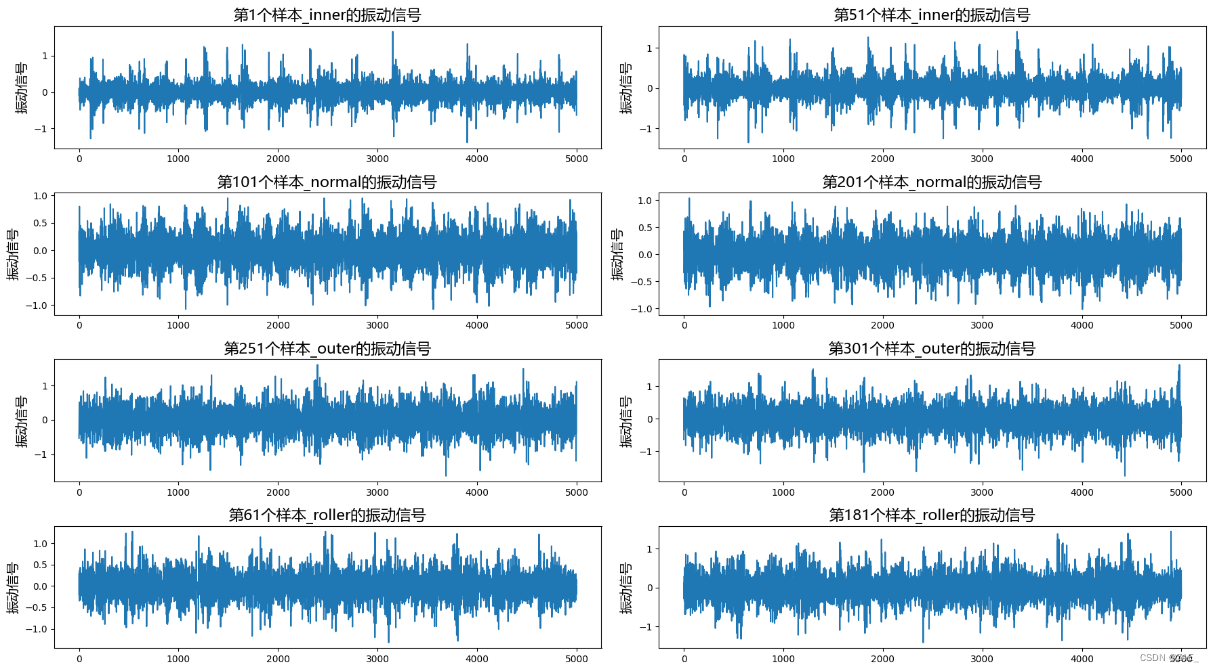
去趋势化后data_detrend的可视化
selected_rows_indices = [0, 50, 100, 200, 250, 300, 60, 180]
num_cols = 2
num_rows = (len(selected_rows_indices) + num_cols - 1) // num_cols
plt.figure(figsize=(18, 2.5 * num_rows))
for i, index in enumerate(selected_rows_indices):
vibration_data = data_detrend[index]
label_value = labels[index]
plt.subplot(num_rows, num_cols, i+1)
plt.plot(vibration_data)
plt.title(f"第{index+1}个样本_{label_value}的振动信号", fontproperties=font_prop, fontsize=16)
plt.xlabel("", fontproperties=font_prop, fontsize=14)
plt.ylabel("振动信号", fontproperties=font_prop, fontsize=14)
plt.tight_layout()
plt.savefig("data_detrend_1000.jpg")
plt.show()
3.5 小波变换
- 为什么要进行小波变换:
-
时频局部性: 小波变换提供了时频局部性,能够同时提供信号在时间和频率上的信息。而振动信号的频率特征随时间而变化,通过小波变换可以更好地捕捉到信号中的瞬时振动和频域特征。
-
多尺度分析: 小波变换具有多尺度分析的特性,允许在不同尺度上对信号进行分解,可以得到不同频率范围内的振动模式。
-
数据降维:小波变换能够将信号能量集中在少量的系数中,可以压缩和减小数据维度。提取小波系数的某些层级可以聚焦于感兴趣的频率范围,降低了数据的复杂性。
-
特征提取: 小波变换的系数可以被用作特征来描述信号的不同方面。在振动信号中,第三层小波系数通常包含高频信息,对于检测故障信号或其他短时事件很有用。
- 小波变换具体操作:
-
选择小波基函数: 选择 ‘db2’ 小波基函数,在信号中捕捉不同频率的信息。
-
进行小波变换: 对信号应用小波变换函数
pywt.wavedec,使用选择的小波基进行3层分解,得到3种不同尺度的小波系数。 -
提取第三层的小波系数: 提取了第三层的小波系数,这一层的高频信息比较能概述原来信号的关键特征(通过多次对比实验得到的最优选择)。而且将小波变换得到的不同尺度的数据都输入模型做起来十分困难QAQ。
import pywt
def wavelet_transform(data):
transformed_coeffs = [] # 存储每个信号的小波变换系数
for i in range(data.shape[0]): # 遍历数据的每一行
coeffs = pywt.wavedec(data[i, :], 'db2', level=3) # 对每一行数据进行小波变换,使用db2小波基,3层分解
transformed_coeffs.append(coeffs) # 将变换得到的系数存储起来
return transformed_coeffs # 返回所有信号的小波变换系数
def extract_third_level_wavelet(data):
third_level_coeffs = [] # 存储第三层小波系数的列表
for coeffs in data: # 遍历每个信号的小波变换系数
third_level_coeffs.append(coeffs[2]) # 取第三层小波系数并存储
third_level_coeffs = np.array(third_level_coeffs) # 将数据转换为NumPy数组
return third_level_coeffs
transformed_coeffs = wavelet_transform(data_detrend) # 对data_detrend应用小波变换
data_wave = extract_third_level_wavelet(transformed_coeffs)
print("Shape of data_wave:", data_wave.shape) # 打印data_wave的形状信息
Shape of data_wave: (768, 1252)
连续小波变换后data_wave的可视化
# 选择要展示的样本索引
sample_indices = [0, 100, 250, 60]
# 创建一个图形窗口
plt.figure(figsize=(12, 6))
# 循环展示每个样本的小波变换结果
for idx in sample_indices:
# 获取样本数据及其小波变换结果
original_data = data_detrend[idx, :]
label_value = labels[idx]
# 绘制原始数据
plt.subplot(4, 2, 2 * (sample_indices.index(idx)) + 1)
plt.plot(original_data)
plt.title(f'样本 {idx+1} _ {label_value}- 原始数据', fontproperties=font_prop, fontsize=14)
# 绘制小波变换结果
plt.subplot(4, 2, 2 * (sample_indices.index(idx)) + 2)
plt.plot(data_wave[idx])
plt.title(f'样本 {idx+1} _ {label_value} - 小波变换结果', fontproperties=font_prop, fontsize=14)
# 调整布局
plt.tight_layout()
plt.show()

四、数据集划分与数据加载
1. 数据形状重塑:
- 将data_wave数组重新形状为(-1, 1, 1252),“-1”表示自动计算维度以保持数据总数不变;“1”是为了添加一个通道,方便后续输入1D卷积;“1252”是原来长度为5000的序列经过小波变换并提取的第三层小波系数,其序列长度为1252。
2. 划分训练集与验证集:
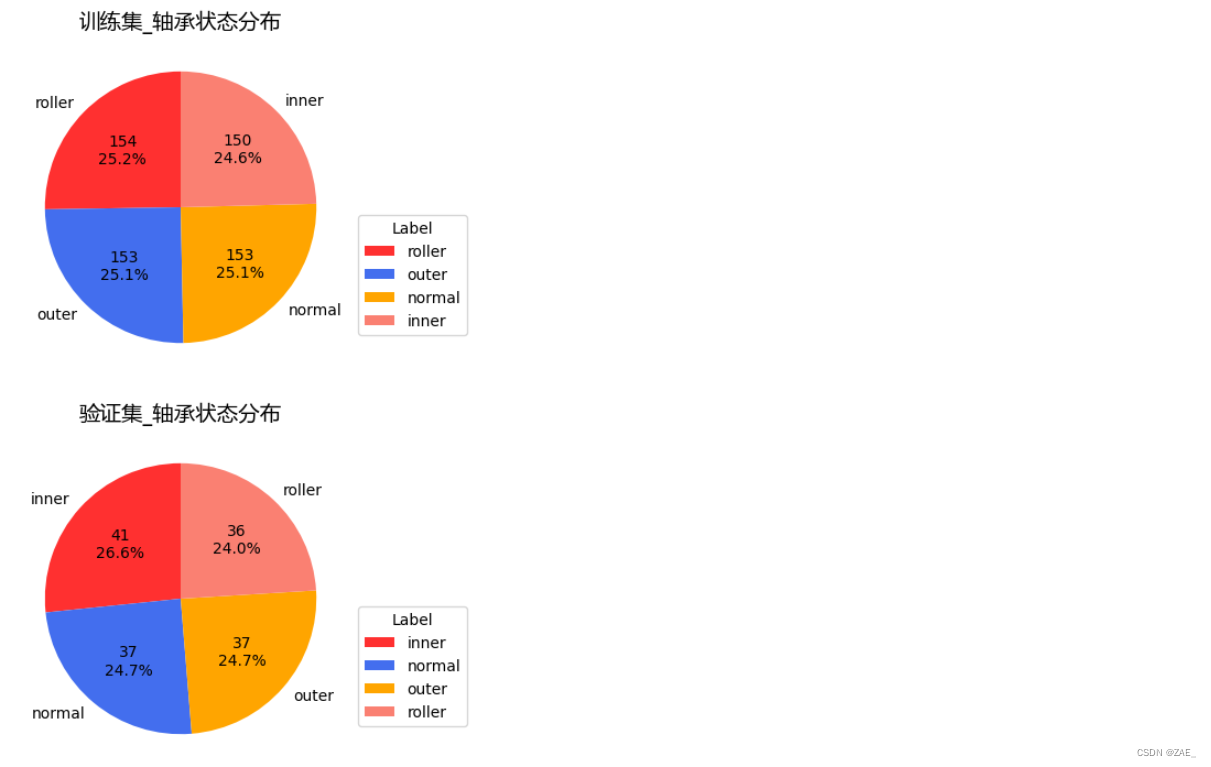
- 设置随机种子为22是为了让验证集中各类别比较均衡,因为之前通过混淆矩阵发现训练结果有个类别准确率较低,跟占比较小有关。
3. 标签映射处理:
- 在 PyTorch 中直接使用标签映射处理标签,避免了像在TensorFlow 中需要将标签转换为独热编码的步骤。
4. 创建数据加载器:
- 设置batch_size为64也是多次对比实验得到的最优的,128和32的准确率都比64明显要低。通过多次实验对比发现这是一个最优的选择。其他尺寸如128和32的批处理大小导致准确率明显下降,64的批处理大小在实验中表现最佳。这个选择旨在平衡训练效率和模型性能。
# 将data_wave数组重新形状为(-1, 1, 1252),其中-1表示自动计算维度以保持数据总数不变
data_fin = data_wave.reshape(-1, 1, 1252)
print(data_fin.shape)
# 验证集占总数据的比例为0.2,随机数生成器的种子为22(试出来的验证集各类别比较均衡的种子),打乱数据
train_data, val_data, train_label, val_label = train_test_split(data_fin,
labels,
test_size=0.20, random_state=22, shuffle=True
)
# 定义标签映射关系
label_mapping = {'normal': 0, 'inner': 1, 'outer': 2, 'roller': 3}
# 创建训练数据集,将数据和对应标签转换为PyTorch张量
train_dataset = [(torch.Tensor(data), torch.tensor(label_mapping[label])) for data, label in zip(train_data, train_label)]
# 创建验证数据集,同样将数据和对应标签转换为PyTorch张量
val_dataset = [(torch.Tensor(data), torch.tensor(label_mapping[label])) for data, label in zip(val_data, val_label)]
# 创建训练数据加载器,每次加载8个样本并进行随机打乱
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 创建验证数据加载器,每次加载8个样本(设大点也行,但基本都秒验证完),进行打乱
val_dl = torch.utils.data.DataLoader(val_dataset, batch_size=64, shuffle=True)
# 查看输入数据格式
batch_shape = next(iter(train_dl))[0].shape
num_batches = len(train_dl)
print("Batch shape:", batch_shape)
print("Number of batches:", num_batches)
(768, 1, 1252)
Batch shape: torch.Size([64, 1, 1252])
Number of batches: 10
训练集与验证集_轴承状态分布情况
plot_label_distribution(pd.DataFrame({'label': train_label}),"训练集_轴承状态分布")
plot_label_distribution(pd.DataFrame({'label': val_label}),"验证集_轴承状态分布")
这里设置了保存并直接读取划分好的训练数据的代码,方便做实验时不用再重复上面的数据处理步骤,单次从头运行时可跳过此步
# 将数据和标签保存为npz文件
np.savez('data_wave_split.npz', train_data=train_data, val_data=val_data, train_label=train_label, val_label=val_label)
# 提取训练和验证数据和标签
loaded_data = np.load('data_wave_split.npz')
train_data = loaded_data['train_data']
val_data = loaded_data['val_data']
train_label = loaded_data['train_label']
val_label = loaded_data['val_label']
# 定义标签映射关系
label_mapping = {'normal': 0, 'inner': 1, 'outer': 2, 'roller': 3}
# 创建训练数据集,将数据和对应标签转换为PyTorch张量
train_dataset = [(torch.Tensor(data), torch.tensor(label_mapping[label])) for data, label in zip(train_data, train_label)]
# 创建验证数据集,同样将数据和对应标签转换为PyTorch张量
val_dataset = [(torch.Tensor(data), torch.tensor(label_mapping[label])) for data, label in zip(val_data, val_label)]
# 创建训练数据加载器,每次加载8个样本并进行随机打乱
train_dl = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 创建验证数据加载器,每次加载8个样本(设大点也行,但基本都秒验证完),进行打乱
val_dl = torch.utils.data.DataLoader(val_dataset, batch_size=64, shuffle=True)
# 查看输入数据格式
batch_shape = next(iter(train_dl))[0].shape
num_batches = len(train_dl)
print("Batch shape:", batch_shape)
print("Number of batches:", num_batches)
Batch shape: torch.Size([64, 1, 1252])
Number of batches: 10
五、定义绘图函数和训练函数
5.1 训练指标与混淆矩阵绘图函数定义
- plot_confusion_matrices 函数
用于绘制训练集和验证集的混淆矩阵,用于展示分类模型的性能,显示实际类别与模型预测类别之间的关系。
- plot_training_metrics 函数
用于绘制训练指标随时间(epoch)的变化趋势。包括训练集和验证集的损失(Loss)和准确率(Accuracy)。
def plot_training_metrics(train_loss_history, val_loss_history, train_accuracy_history, val_accuracy_history, model_name):
plt.figure(figsize=(10, 5))
plt.subplot(1, 2, 1)
plt.plot(train_loss_history, label='Training Loss')
plt.plot(val_loss_history, label='Validation Loss')
plt.title(f'Loss Over Epochs ({model_name})')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(train_accuracy_history, label='Training Accuracy')
plt.plot(val_accuracy_history, label='Validation Accuracy')
plt.title(f'Accuracy Over Epochs ({model_name})')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
plt.savefig(f'training_metrics_{model_name}.png')
plt.show()
def plot_confusion_matrices(train_true_labels, train_predicted_labels, val_true_labels, val_predicted_labels, class_labels, model_name):
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
# 绘制训练集混淆矩阵
cm_train = confusion_matrix(train_true_labels, train_predicted_labels)
cm_train = cm_train.astype('float') / cm_train.sum(axis=1)[:, np.newaxis] # Normalize confusion matrix
sns.heatmap(cm_train, annot=True, fmt=".2f", cmap="Blues", xticklabels=class_labels, yticklabels=class_labels, cbar_kws={'label': 'Scale'}, ax=axes[0])
axes[0].set_title(f'Confusion Matrix - Training Set ({model_name})', fontproperties=font_prop, fontsize=12)
axes[0].set_xlabel('Predicted Label')
axes[0].set_ylabel('True Label')
# 绘制验证集混淆矩阵
cm_val = confusion_matrix(val_true_labels, val_predicted_labels)
cm_val = cm_val.astype('float') / cm_val.sum(axis=1)[:, np.newaxis] # Normalize confusion matrix
sns.heatmap(cm_val, annot=True, fmt=".2f", cmap="Blues", xticklabels=class_labels, yticklabels=class_labels, cbar_kws={'label': 'Scale'}, ax=axes[1])
axes[1].set_title(f'Confusion Matrix - Validation Set ({model_name})', fontproperties=font_prop, fontsize=12)
axes[1].set_xlabel('Predicted Label')
axes[1].set_ylabel('True Label')
plt.tight_layout()
plt.savefig(f'training_confusion_matrices_{model_name}.png')
plt.show()
5.2 训练函数定义
1. 模型训练准备
-
设备选择: 根据是否有可用的 GPU,选择将模型放在 GPU 上或 CPU 上进行训练。
-
损失函数、优化器和学习率调度器: 定义交叉熵损失作为分类问题的损失函数,使用 Adam 优化器进行参数更新。设置学习率调度器(StepLR),通过步长和衰减因子来调整学习率。(最后调来调去还是舍弃了学习率衰减)
2. 训练过程
-
循环训练每个 epoch: 对于每个 epoch,执行训练和验证阶段。
-
训练阶段:
- 将模型切换到训练模式。
- 遍历训练数据加载器,计算损失并执行反向传播。
- 记录训练集的平均损失和准确度。
- 在训练过程中,保存训练集真实标签和预测标签,以备后续绘制混淆矩阵使用。
-
验证阶段:
- 将模型切换到评估模式。
- 遍历验证数据加载器,计算损失和准确度。
- 记录验证集的平均损失和准确度。
- 在验证过程中,保存验证集真实标签和预测标签,以备后续绘制混淆矩阵使用。
3. 模型性能评估与保存
-
性能评估: 每个 epoch 后,输出当前 epoch 的训练和验证集损失、准确度等指标。
-
最佳模型保存: 通过在验证集上监测准确度和损失,选择在这两个指标上表现最优的模型作为最佳模型。如果准确度相同,则选择具有更低验证集损失的模型。
-
保存模型: 保存训练完的模型的状态字典为文件,以便后续使用。
4. 可视化与输出
- 图形化输出: 使用
plot_training_metrics函数绘制并保存训练过程中损失和准确度的趋势图。
- 使用
plot_training_metrics函数绘制并保存训练过程中损失和准确度的趋势图。
- 混淆矩阵绘制: 使用
plot_confusion_matrices函数输出并保存训练集和验证集混淆矩阵图。
def training(model, train_dl, val_dl, num_epochs, model_name):
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 损失函数,优化器和学习率调度器
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
# scheduler = torch.optim.lr_scheduler.OneCycleLR(optimizer, max_lr=0.001,
# steps_per_epoch=len(train_dl),
# epochs=num_epochs,
# anneal_strategy='linear')
# 学习率调度器
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=50, gamma=0.01)
# 用于存储损失和准确度值的列表
train_loss_history = []
train_accuracy_history = []
val_loss_history = []
val_accuracy_history = []
best_accuracy = 0.0
lowest_loss = float('inf')
best_epoch = 0
best_model_state = None
# 用于存储混淆矩阵
train_true_labels = []
train_predicted_labels = []
val_true_labels = []
val_predicted_labels = []
# 每个epoch重复一次
for epoch in range(num_epochs):
running_loss = 0.0
correct_prediction = 0
total_prediction = 0
# 训练阶段
model.train()
for inputs, labels in train_dl:
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
scheduler.step()
running_loss += loss.item()
_, prediction = torch.max(outputs, 1)
correct_prediction += (prediction == labels).sum().item()
total_prediction += labels.size(0)
train_true_labels.extend(labels.cpu().numpy())############
train_predicted_labels.extend(prediction.cpu().numpy())############
avg_train_loss = running_loss / len(train_dl)
train_accuracy = correct_prediction / total_prediction
train_loss_history.append(avg_train_loss)
train_accuracy_history.append(train_accuracy)
# 验证阶段
model.eval()
running_loss = 0.0
correct_prediction = 0
total_prediction = 0
with torch.no_grad():
for inputs, labels in val_dl:
inputs, labels = inputs.to(device), labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_loss += loss.item()
_, prediction = torch.max(outputs, 1)
correct_prediction += (prediction == labels).sum().item()
total_prediction += labels.size(0)
val_true_labels.extend(labels.cpu().numpy())############
val_predicted_labels.extend(prediction.cpu().numpy())###########
avg_val_loss = running_loss / len(val_dl)
val_accuracy = correct_prediction / total_prediction
val_loss_history.append(avg_val_loss)
val_accuracy_history.append(val_accuracy)
# 检查当前模型是否优于记录的最佳模型
if val_accuracy > best_accuracy or (val_accuracy == best_accuracy and avg_val_loss < lowest_loss):
best_accuracy = val_accuracy
lowest_loss = avg_val_loss
best_epoch = epoch
best_model_state = model.state_dict().copy()
print(f'Epoch: {epoch + 1}, Train Loss: {avg_train_loss:.4f}, Train Accuracy: {train_accuracy:.4f}, Val Loss: {avg_val_loss:.4f}, Val Accuracy: {val_accuracy:.4f}')
# 保存最佳模型
model_filename = f'best_model_{model_name}.pth'
# 删除原有同名模型文件
if os.path.exists(model_filename):
os.remove(model_filename)
torch.save(best_model_state, model_filename, _use_new_zipfile_serialization=False)
print(f'Finished Training. Best model saved from epoch {best_epoch + 1} as {model_filename}.')
# 绘制并保存损失和准确度图
plot_training_metrics(train_loss_history, val_loss_history, train_accuracy_history, val_accuracy_history, model_name)
# 获取类标签列表
label_mapping = {'normal': 0, 'inner': 1, 'outer': 2, 'roller': 3}
class_labels = [label for label, _ in sorted(label_mapping.items(), key=lambda x: x[1])]
# 输出混淆矩阵图
plot_confusion_matrices(train_true_labels, train_predicted_labels, val_true_labels, val_predicted_labels, class_labels, model_name)
六、模型搭建
import torch
import torch.nn as nn
import torch.nn.init as init
import torch.nn.functional as F
import torch.optim as optim
import seaborn as sns
from sklearn.metrics import confusion_matrix
from torch.optim import lr_scheduler
from torch import Tensor
from torch.utils.data import TensorDataset, DataLoader
from torch.optim.lr_scheduler import ExponentialLR
from torch.optim.lr_scheduler import StepLR
from torch.nn.modules.loss import CrossEntropyLoss
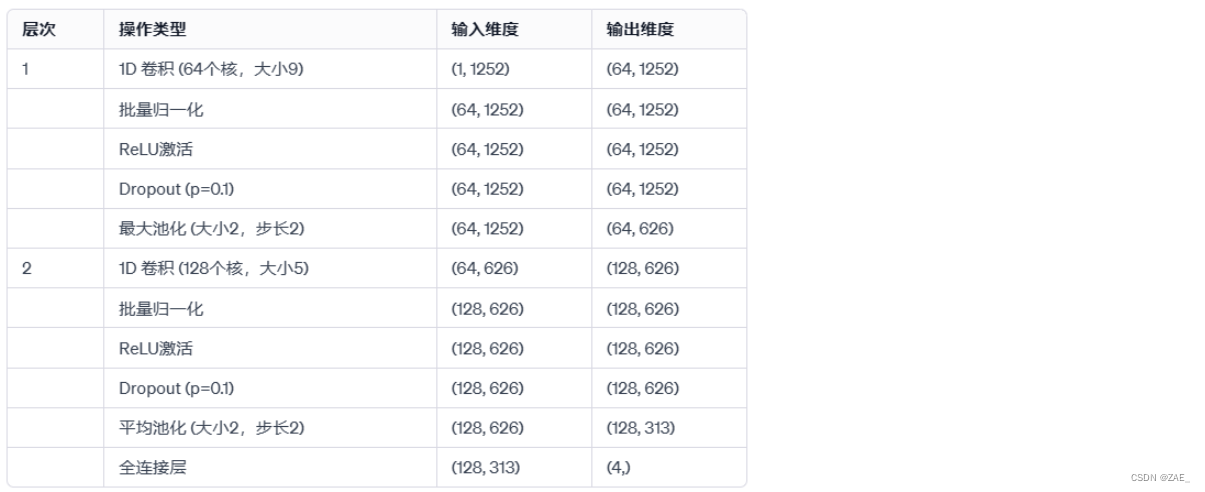
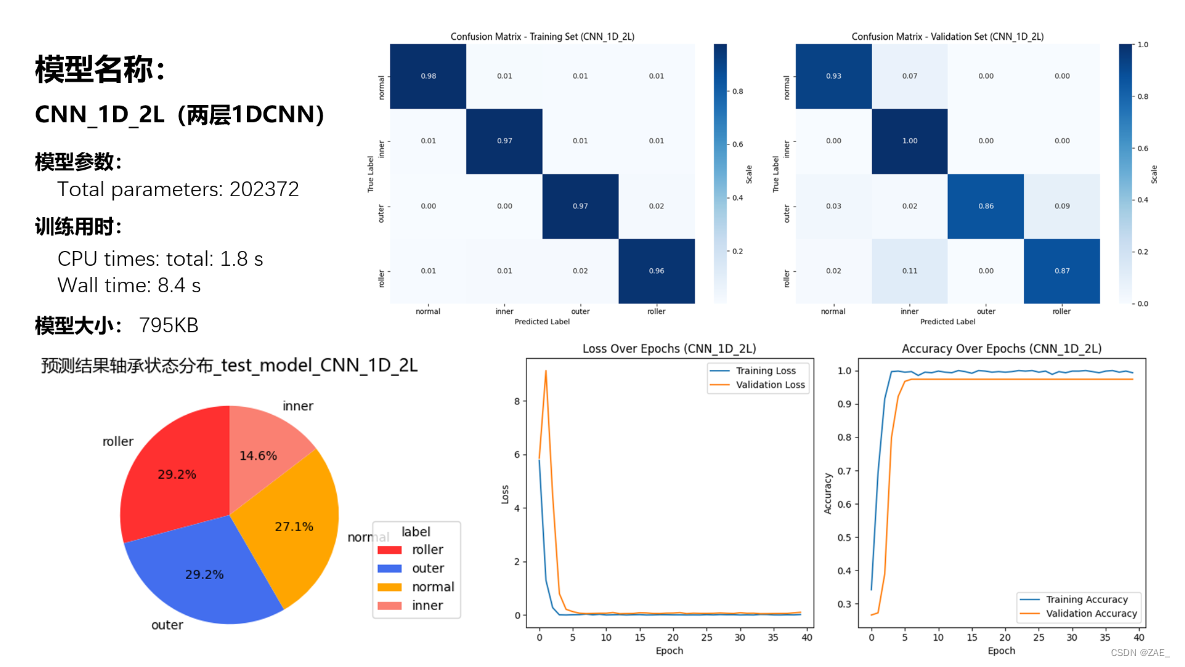
6.1 CNN_1D_2L模型
input_size = 1252
lr = 0.001
wd = 0.0001
betas=(0.99, 0.999)
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
class CNN_1D_2L(nn.Module):
def __init__(self, n_in):
super().__init__()
self.n_in = n_in
self.layer1 = nn.Sequential(
nn.Conv1d(1, 64, (9,), stride=1, padding=4),
nn.BatchNorm1d(64),
nn.ReLU(),
nn.Dropout(p=0.1),
nn.MaxPool1d(2,stride=2)
)
self.layer2 = nn.Sequential(
nn.Conv1d(64, 128, (5,), stride=1, padding=2),
nn.BatchNorm1d(128),
nn.ReLU(),
nn.Dropout(p=0.1),
nn.AvgPool1d(2,stride=2)
)
self.linear1 = nn.Linear(self.n_in*128 //4, 4)
def forward(self, x):
x = x.view(-1, 1, self.n_in)
x = self.layer1(x)
x = self.layer2(x)
x = x.view(-1, self.n_in*128//4)
return self.linear1(x)
model_CNN_1D_2L = CNN_1D_2L(input_size)
model_CNN_1D_2L.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_CNN_1D_2L.parameters(), lr=0.001)
# 打印模型结构
print(model_CNN_1D_2L)
total_params = sum(p.numel() for p in model_CNN_1D_2L.parameters())
print(f"Total parameters: {total_params}")
# scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
## Instantiate model, optimizer and loss function
# opt = optim.Adam(model.parameters(), lr=lr, betas=betas, weight_decay=wd)
# loss_func = CrossEntropyLoss()
# # scheduler = ExponentialLR(opt, gamma=0.98)
# scheduler = StepLR(opt, step_size=7, gamma=0.05)
CNN_1D_2L(
(layer1): Sequential(
(0): Conv1d(1, 64, kernel_size=(9,), stride=(1,), padding=(4,))
(1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
(4): MaxPool1d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(layer2): Sequential(
(0): Conv1d(64, 128, kernel_size=(5,), stride=(1,), padding=(2,))
(1): BatchNorm1d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Dropout(p=0.1, inplace=False)
(4): AvgPool1d(kernel_size=(2,), stride=(2,), padding=(0,))
)
(linear1): Linear(in_features=40064, out_features=4, bias=True)
)
Total parameters: 202372
%%time
num_epochs = 40
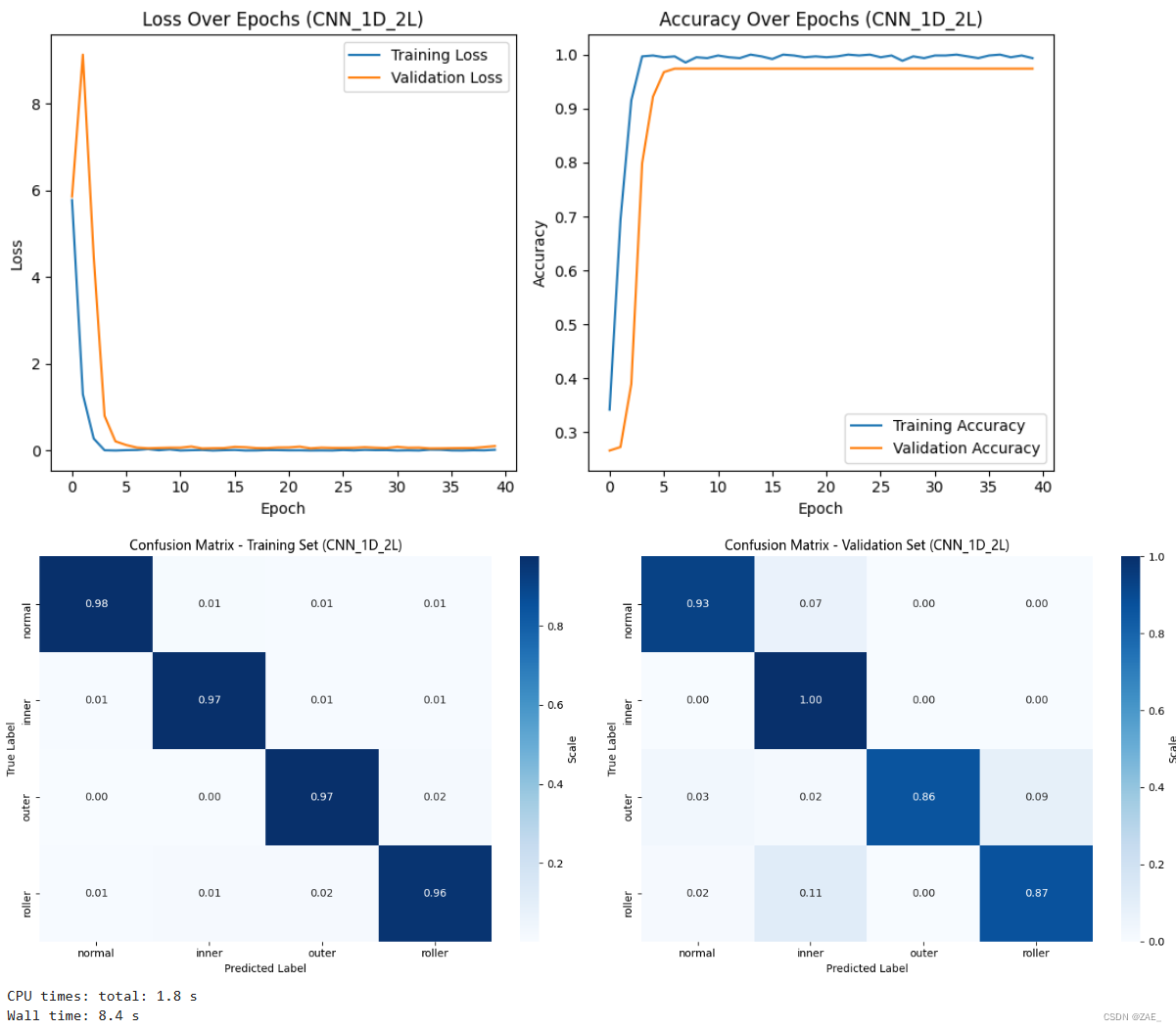
training(model_CNN_1D_2L, train_dl, val_dl, num_epochs,"CNN_1D_2L")
Epoch: 1, Train Loss: 5.7770, Train Accuracy: 0.3420, Val Loss: 5.8563, Val Accuracy: 0.2662
Epoch: 2, Train Loss: 1.2994, Train Accuracy: 0.6938, Val Loss: 9.1282, Val Accuracy: 0.2727
Epoch: 3, Train Loss: 0.2791, Train Accuracy: 0.9153, Val Loss: 4.4755, Val Accuracy: 0.3896
Epoch: 4, Train Loss: 0.0101, Train Accuracy: 0.9967, Val Loss: 0.8033, Val Accuracy: 0.7987
Epoch: 5, Train Loss: 0.0041, Train Accuracy: 0.9984, Val Loss: 0.2160, Val Accuracy: 0.9221
Epoch: 6, Train Loss: 0.0125, Train Accuracy: 0.9951, Val Loss: 0.1303, Val Accuracy: 0.9675
Epoch: 7, Train Loss: 0.0169, Train Accuracy: 0.9967, Val Loss: 0.0712, Val Accuracy: 0.9740
Epoch: 8, Train Loss: 0.0379, Train Accuracy: 0.9853, Val Loss: 0.0556, Val Accuracy: 0.9740
Epoch: 9, Train Loss: 0.0098, Train Accuracy: 0.9951, Val Loss: 0.0628, Val Accuracy: 0.9740
Epoch: 10, Train Loss: 0.0303, Train Accuracy: 0.9935, Val Loss: 0.0687, Val Accuracy: 0.9740
Epoch: 11, Train Loss: 0.0040, Train Accuracy: 0.9984, Val Loss: 0.0694, Val Accuracy: 0.9740
Epoch: 12, Train Loss: 0.0112, Train Accuracy: 0.9951, Val Loss: 0.0963, Val Accuracy: 0.9740
Epoch: 13, Train Loss: 0.0163, Train Accuracy: 0.9935, Val Loss: 0.0515, Val Accuracy: 0.9740
Epoch: 14, Train Loss: 0.0033, Train Accuracy: 1.0000, Val Loss: 0.0569, Val Accuracy: 0.9740
Epoch: 15, Train Loss: 0.0117, Train Accuracy: 0.9967, Val Loss: 0.0597, Val Accuracy: 0.9740
Epoch: 16, Train Loss: 0.0170, Train Accuracy: 0.9919, Val Loss: 0.0886, Val Accuracy: 0.9740
Epoch: 17, Train Loss: 0.0040, Train Accuracy: 1.0000, Val Loss: 0.0802, Val Accuracy: 0.9740
Epoch: 18, Train Loss: 0.0059, Train Accuracy: 0.9984, Val Loss: 0.0600, Val Accuracy: 0.9740
Epoch: 19, Train Loss: 0.0143, Train Accuracy: 0.9951, Val Loss: 0.0581, Val Accuracy: 0.9740
Epoch: 20, Train Loss: 0.0131, Train Accuracy: 0.9967, Val Loss: 0.0727, Val Accuracy: 0.9740
Epoch: 21, Train Loss: 0.0081, Train Accuracy: 0.9951, Val Loss: 0.0754, Val Accuracy: 0.9740
Epoch: 22, Train Loss: 0.0089, Train Accuracy: 0.9967, Val Loss: 0.0934, Val Accuracy: 0.9740
Epoch: 23, Train Loss: 0.0042, Train Accuracy: 1.0000, Val Loss: 0.0544, Val Accuracy: 0.9740
Epoch: 24, Train Loss: 0.0060, Train Accuracy: 0.9984, Val Loss: 0.0703, Val Accuracy: 0.9740
Epoch: 25, Train Loss: 0.0042, Train Accuracy: 1.0000, Val Loss: 0.0642, Val Accuracy: 0.9740
Epoch: 26, Train Loss: 0.0155, Train Accuracy: 0.9951, Val Loss: 0.0637, Val Accuracy: 0.9740
Epoch: 27, Train Loss: 0.0070, Train Accuracy: 0.9984, Val Loss: 0.0669, Val Accuracy: 0.9740
Epoch: 28, Train Loss: 0.0188, Train Accuracy: 0.9886, Val Loss: 0.0803, Val Accuracy: 0.9740
Epoch: 29, Train Loss: 0.0127, Train Accuracy: 0.9967, Val Loss: 0.0681, Val Accuracy: 0.9740
Epoch: 30, Train Loss: 0.0136, Train Accuracy: 0.9935, Val Loss: 0.0605, Val Accuracy: 0.9740
Epoch: 31, Train Loss: 0.0048, Train Accuracy: 0.9984, Val Loss: 0.0886, Val Accuracy: 0.9740
Epoch: 32, Train Loss: 0.0082, Train Accuracy: 0.9984, Val Loss: 0.0679, Val Accuracy: 0.9740
Epoch: 33, Train Loss: 0.0043, Train Accuracy: 1.0000, Val Loss: 0.0704, Val Accuracy: 0.9740
Epoch: 34, Train Loss: 0.0237, Train Accuracy: 0.9967, Val Loss: 0.0525, Val Accuracy: 0.9740
Epoch: 35, Train Loss: 0.0211, Train Accuracy: 0.9935, Val Loss: 0.0540, Val Accuracy: 0.9740
Epoch: 36, Train Loss: 0.0063, Train Accuracy: 0.9984, Val Loss: 0.0579, Val Accuracy: 0.9740
Epoch: 37, Train Loss: 0.0042, Train Accuracy: 1.0000, Val Loss: 0.0609, Val Accuracy: 0.9740
Epoch: 38, Train Loss: 0.0107, Train Accuracy: 0.9951, Val Loss: 0.0619, Val Accuracy: 0.9740
Epoch: 39, Train Loss: 0.0077, Train Accuracy: 0.9984, Val Loss: 0.0836, Val Accuracy: 0.9740
Epoch: 40, Train Loss: 0.0216, Train Accuracy: 0.9935, Val Loss: 0.1064, Val Accuracy: 0.9740
Finished Training. Best model saved from epoch 13 as best_model_CNN_1D_2L.pth.
CPU times: total: 1.8 s
Wall time: 8.4 s
1D卷积可视化
# 选择要可视化的样本
sample_data, _ = next(iter(train_dl))
# 定义一个hook函数来捕获第一层Conv1d的输出
def hook_fn(module, input, output):
# 选择第一个样本
activation = output.detach().cpu().numpy()
# 可视化中间层的输出
plt.figure(figsize=(18, 2))
plt.imshow(activation[0], cmap='viridis', aspect='auto')
plt.title('Output of Conv1d Layer')
plt.xlabel('Channel')
plt.ylabel('Time')
plt.colorbar()
plt.show()
# 移除之前可能存在的hook
if hasattr(model_CNN_1D_2L.layer1[0], '_forward_hooks'):
model_CNN_1D_2L.layer1[0]._forward_hooks.clear()
# 注册hook到第一层Conv1d
model_CNN_1D_2L.layer1[0].register_forward_hook(hook_fn)
# 将样本传递到模型中,触发hook
with torch.no_grad():
model_CNN_1D_2L(sample_data.to(device))
# 移除hook以防止对后续forward调用的影响
if hasattr(model_CNN_1D_2L.layer1[0], '_forward_hooks'):
model_CNN_1D_2L.layer1[0]._forward_hooks.clear()

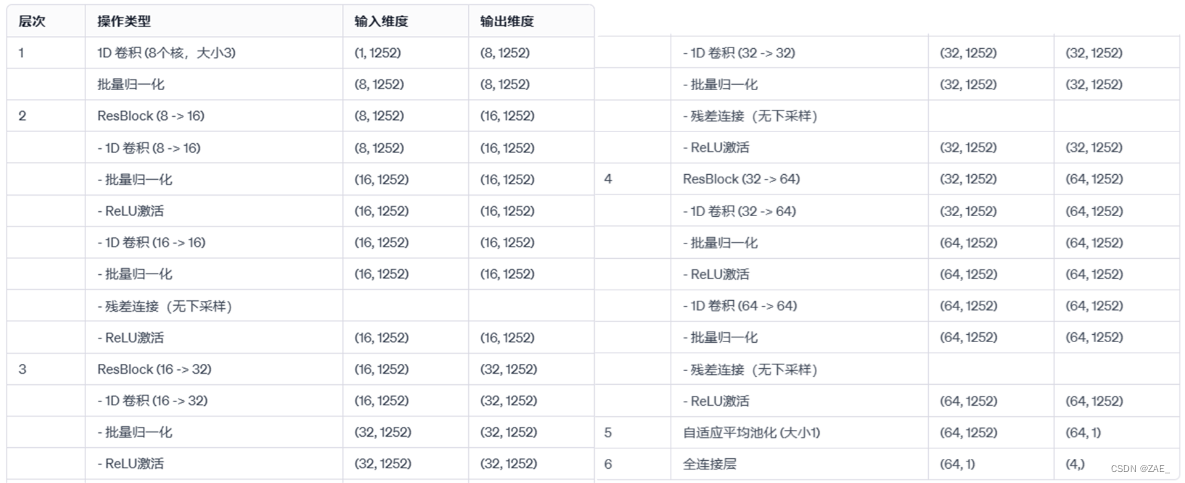
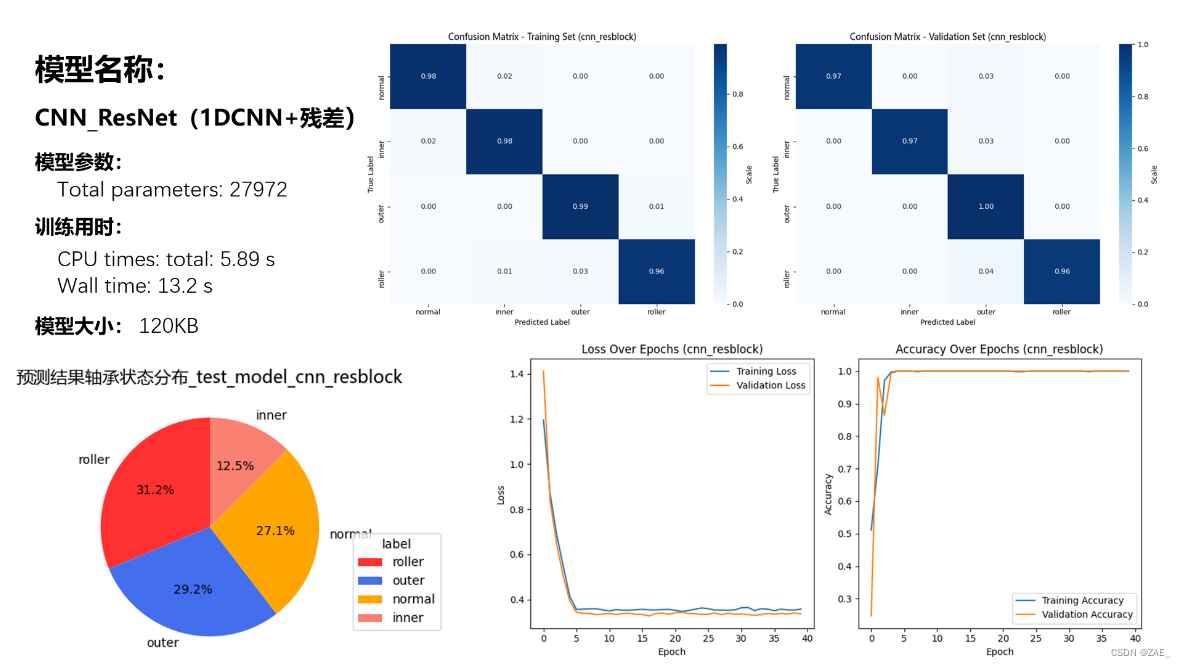
6.2 CNN_Resblock模型
# 初始化模型和优化器
input_size = 1252 # 输入数据长度
num_inchannel = 1 # 输入数据通道数
num_classes = 4 # 四分类任务
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
class ResBlock(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride, padding):
super(ResBlock, self).__init__()
self.conv1 = nn.Conv1d(in_channels, out_channels, kernel_size, stride, padding) # 第1个卷积层
self.bn1 = nn.BatchNorm1d(out_channels) # 第1个卷积层的BatchNorm
self.conv2 = nn.Conv1d(out_channels, out_channels, kernel_size, stride, padding) # 第2个卷积层
self.bn2 = nn.BatchNorm1d(out_channels) # 第2个卷积层的BatchNorm
self.downsample = nn.Conv1d(in_channels, out_channels, kernel_size=1, stride=stride) #下采样,当输入输出通道数不同时使用
def forward(self, x):
identity = x # 残差连接的identity
out = F.relu(self.bn1(self.conv1(x))) # 第1个卷积和BatchNorm
out = self.bn2(self.conv2(out)) # 第2个卷积和BatchNorm
if self.downsample is not None:
identity = self.downsample(identity) # 如果通道数不同,对identity进行下采样
out += identity # 残差连接
out = F.relu(out) # ReLU激活
return out
class CNN_ResNet_model(nn.Module):
def __init__(self, num_classes, input_size, num_inchannel):
super(CNN_ResNet_model, self).__init__()
self.conv1 = nn.Conv1d(num_inchannel, 8, kernel_size=3, stride=1, padding=1) # 输入层卷积
self.bn1 = nn.BatchNorm1d(8) # 输入层BatchNorm
self.resblock1 = ResBlock(8, 16, kernel_size=3, stride=1, padding=1) # 第1个残差块
self.resblock2 = ResBlock(16, 32, kernel_size=3, stride=1, padding=1) # 第2个残差块
self.resblock3 = ResBlock(32, 64, kernel_size=3, stride=1, padding=1) # 第3个残差块
self.ap = nn.AdaptiveAvgPool1d(output_size=1) # 自适应平均池化层
self.fc = nn.Linear(64, num_classes) # 全连接层
self.apply(self.init_weights) # 添加初始化权重
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x))) # 输入层
x = self.resblock1(x) # 第1个残差块
x = self.resblock2(x) # 第2个残差块
x = self.resblock3(x) # 第3个残差块
x = self.ap(x) # 平均池化
x = x.view(x.size(0), -1) # 拉直
x = self.fc(x) # 全连接层
# x = F.softmax(x, dim=1) # Softmax转换
return x
def init_weights(self, m):
if isinstance(m, nn.Conv1d) or isinstance(m, nn.Linear):
init.kaiming_normal_(m.weight)
# 实例化模型
model_cnn_resblock = CNN_ResNet_model(num_classes, input_size, num_inchannel)
model_cnn_resblock.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_cnn_resblock.parameters(), lr=0.001)
# scheduler = lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1)
# 打印模型结构
print(model_cnn_resblock)
total_params = sum(p.numel() for p in model_cnn_resblock.parameters())
print(f"Total parameters: {total_params}")
CNN_ResNet_model(
(conv1): Conv1d(1, 8, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(8, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(resblock1): ResBlock(
(conv1): Conv1d(8, 16, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv1d(16, 16, kernel_size=(3,), stride=(1,), padding=(1,))
(bn2): BatchNorm1d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Conv1d(8, 16, kernel_size=(1,), stride=(1,))
)
(resblock2): ResBlock(
(conv1): Conv1d(16, 32, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv1d(32, 32, kernel_size=(3,), stride=(1,), padding=(1,))
(bn2): BatchNorm1d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Conv1d(16, 32, kernel_size=(1,), stride=(1,))
)
(resblock3): ResBlock(
(conv1): Conv1d(32, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(bn1): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv1d(64, 64, kernel_size=(3,), stride=(1,), padding=(1,))
(bn2): BatchNorm1d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(downsample): Conv1d(32, 64, kernel_size=(1,), stride=(1,))
)
(ap): AdaptiveAvgPool1d(output_size=1)
(fc): Linear(in_features=64, out_features=4, bias=True)
)
Total parameters: 27972
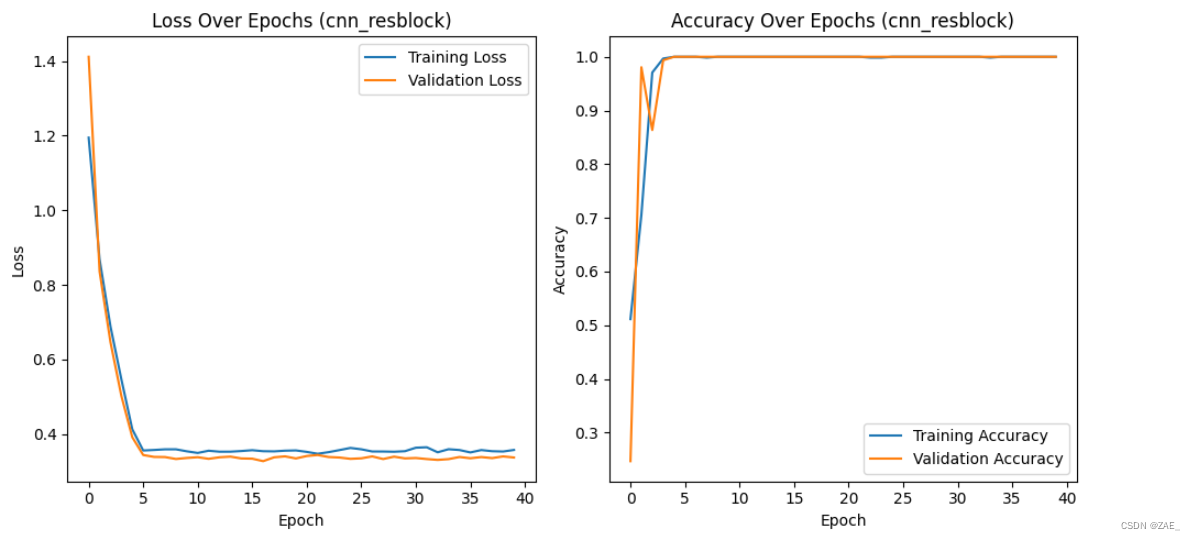
%%time
num_epochs = 40 # 练的epoch数
training(model_cnn_resblock, train_dl, val_dl, num_epochs,"cnn_resblock")
Epoch: 1, Train Loss: 1.1946, Train Accuracy: 0.5114, Val Loss: 1.4114, Val Accuracy: 0.2468
Epoch: 2, Train Loss: 0.8685, Train Accuracy: 0.7052, Val Loss: 0.8357, Val Accuracy: 0.9805
Epoch: 3, Train Loss: 0.6883, Train Accuracy: 0.9707, Val Loss: 0.6459, Val Accuracy: 0.8636
Epoch: 4, Train Loss: 0.5465, Train Accuracy: 0.9967, Val Loss: 0.5019, Val Accuracy: 0.9935
Epoch: 5, Train Loss: 0.4127, Train Accuracy: 1.0000, Val Loss: 0.3914, Val Accuracy: 1.0000
Epoch: 6, Train Loss: 0.3558, Train Accuracy: 1.0000, Val Loss: 0.3437, Val Accuracy: 1.0000
Epoch: 7, Train Loss: 0.3572, Train Accuracy: 1.0000, Val Loss: 0.3386, Val Accuracy: 1.0000
Epoch: 8, Train Loss: 0.3589, Train Accuracy: 0.9984, Val Loss: 0.3382, Val Accuracy: 1.0000
Epoch: 9, Train Loss: 0.3590, Train Accuracy: 1.0000, Val Loss: 0.3330, Val Accuracy: 1.0000
Epoch: 10, Train Loss: 0.3536, Train Accuracy: 1.0000, Val Loss: 0.3358, Val Accuracy: 1.0000
Epoch: 11, Train Loss: 0.3493, Train Accuracy: 1.0000, Val Loss: 0.3378, Val Accuracy: 1.0000
Epoch: 12, Train Loss: 0.3551, Train Accuracy: 1.0000, Val Loss: 0.3335, Val Accuracy: 1.0000
Epoch: 13, Train Loss: 0.3526, Train Accuracy: 1.0000, Val Loss: 0.3376, Val Accuracy: 1.0000
Epoch: 14, Train Loss: 0.3526, Train Accuracy: 1.0000, Val Loss: 0.3393, Val Accuracy: 1.0000
Epoch: 15, Train Loss: 0.3544, Train Accuracy: 1.0000, Val Loss: 0.3345, Val Accuracy: 1.0000
Epoch: 16, Train Loss: 0.3566, Train Accuracy: 1.0000, Val Loss: 0.3338, Val Accuracy: 1.0000
Epoch: 17, Train Loss: 0.3539, Train Accuracy: 1.0000, Val Loss: 0.3272, Val Accuracy: 1.0000
Epoch: 18, Train Loss: 0.3534, Train Accuracy: 1.0000, Val Loss: 0.3375, Val Accuracy: 1.0000
Epoch: 19, Train Loss: 0.3552, Train Accuracy: 1.0000, Val Loss: 0.3401, Val Accuracy: 1.0000
Epoch: 20, Train Loss: 0.3560, Train Accuracy: 1.0000, Val Loss: 0.3345, Val Accuracy: 1.0000
Epoch: 21, Train Loss: 0.3521, Train Accuracy: 1.0000, Val Loss: 0.3410, Val Accuracy: 1.0000
Epoch: 22, Train Loss: 0.3470, Train Accuracy: 1.0000, Val Loss: 0.3437, Val Accuracy: 1.0000
Epoch: 23, Train Loss: 0.3514, Train Accuracy: 0.9984, Val Loss: 0.3383, Val Accuracy: 1.0000
Epoch: 24, Train Loss: 0.3569, Train Accuracy: 0.9984, Val Loss: 0.3369, Val Accuracy: 1.0000
Epoch: 25, Train Loss: 0.3626, Train Accuracy: 1.0000, Val Loss: 0.3334, Val Accuracy: 1.0000
Epoch: 26, Train Loss: 0.3590, Train Accuracy: 1.0000, Val Loss: 0.3348, Val Accuracy: 1.0000
Epoch: 27, Train Loss: 0.3531, Train Accuracy: 1.0000, Val Loss: 0.3400, Val Accuracy: 1.0000
Epoch: 28, Train Loss: 0.3530, Train Accuracy: 1.0000, Val Loss: 0.3329, Val Accuracy: 1.0000
Epoch: 29, Train Loss: 0.3525, Train Accuracy: 1.0000, Val Loss: 0.3392, Val Accuracy: 1.0000
Epoch: 30, Train Loss: 0.3539, Train Accuracy: 1.0000, Val Loss: 0.3346, Val Accuracy: 1.0000
Epoch: 31, Train Loss: 0.3633, Train Accuracy: 1.0000, Val Loss: 0.3356, Val Accuracy: 1.0000
Epoch: 32, Train Loss: 0.3645, Train Accuracy: 1.0000, Val Loss: 0.3328, Val Accuracy: 1.0000
Epoch: 33, Train Loss: 0.3510, Train Accuracy: 1.0000, Val Loss: 0.3305, Val Accuracy: 1.0000
Epoch: 34, Train Loss: 0.3592, Train Accuracy: 0.9984, Val Loss: 0.3326, Val Accuracy: 1.0000
Epoch: 35, Train Loss: 0.3570, Train Accuracy: 1.0000, Val Loss: 0.3384, Val Accuracy: 1.0000
Epoch: 36, Train Loss: 0.3506, Train Accuracy: 1.0000, Val Loss: 0.3350, Val Accuracy: 1.0000
Epoch: 37, Train Loss: 0.3569, Train Accuracy: 1.0000, Val Loss: 0.3382, Val Accuracy: 1.0000
Epoch: 38, Train Loss: 0.3539, Train Accuracy: 1.0000, Val Loss: 0.3354, Val Accuracy: 1.0000
Epoch: 39, Train Loss: 0.3531, Train Accuracy: 1.0000, Val Loss: 0.3399, Val Accuracy: 1.0000
Epoch: 40, Train Loss: 0.3572, Train Accuracy: 1.0000, Val Loss: 0.3370, Val Accuracy: 1.0000
Finished Training. Best model saved from epoch 17 as best_model_cnn_resblock.pth.
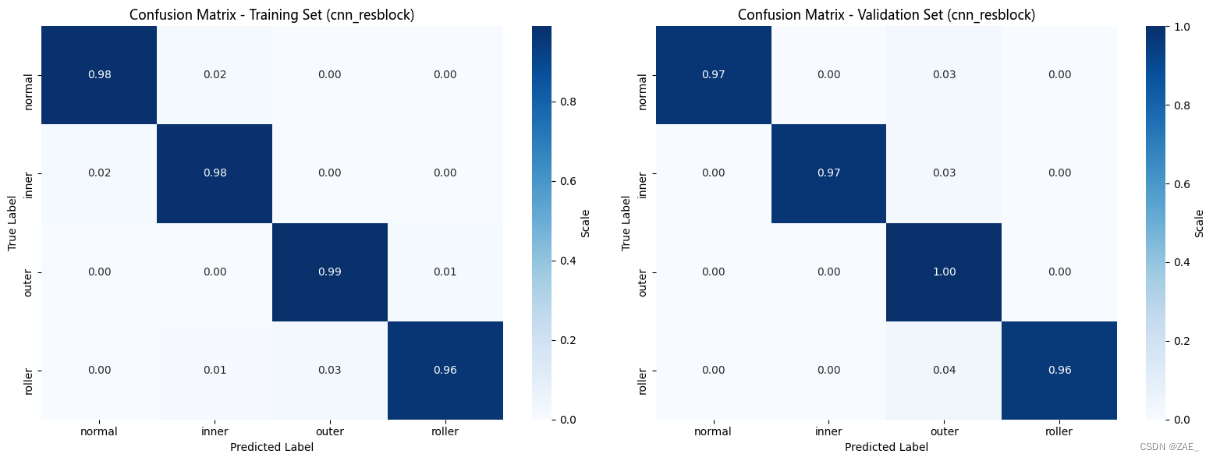
CPU times: total: 5.89 s
Wall time: 13.2 s
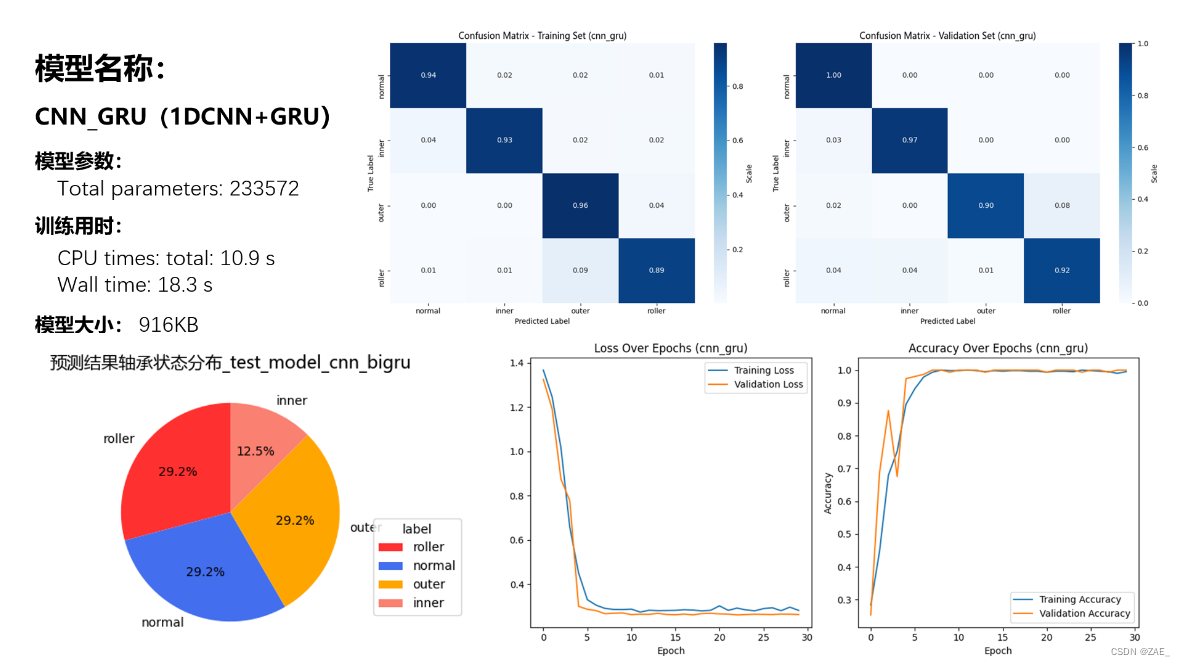
6.3 CNN_GRU模型
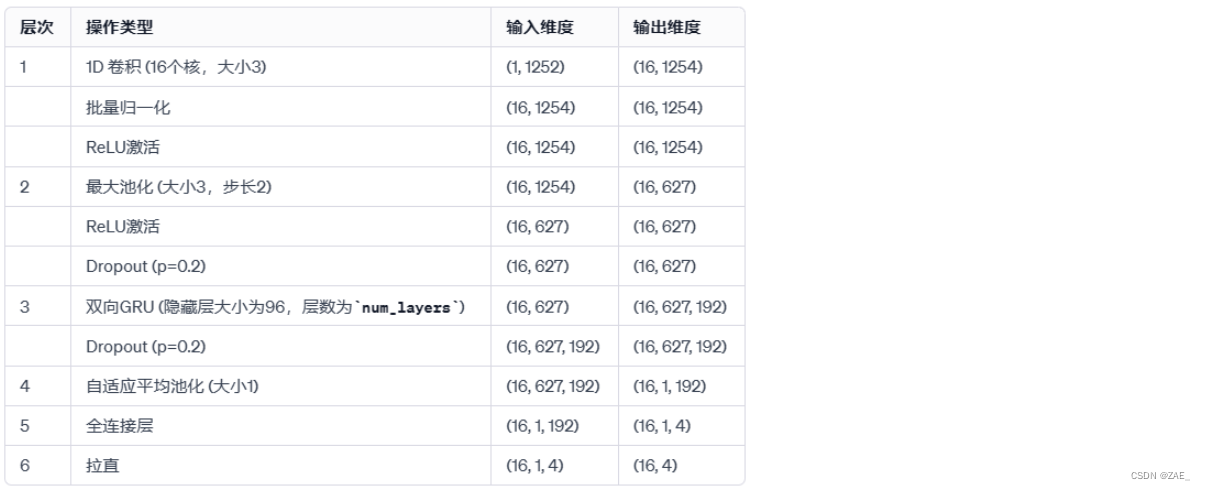
# Instantiate the model
num_classes = 4 # Change this to your actual number of classes
input_size = 1252
num_inchannel = 1
hidden_size = 96 # You can adjust this as needed
num_layers = 2 # You can adjust this as needed
class CNN_BiGRU_Model(nn.Module):
def __init__(self, num_classes, input_size, hidden_size, num_layers):
super(CNN_BiGRU_Model, self).__init__()
self.conv1 = nn.Conv1d(1, 16, kernel_size=3, stride=1, padding=4)
self.bn1 = nn.BatchNorm1d(16)
self.relu1 = nn.ReLU()
self.maxpool = nn.MaxPool1d(kernel_size=3, stride=2)
self.relu2 = nn.ReLU()
self.dropout1 = nn.Dropout(0.2)
self.bi_gru = nn.GRU(16, hidden_size=hidden_size, num_layers=num_layers, batch_first=True, bidirectional=True)
self.dropout2 = nn.Dropout(0.2)
self.ap = nn.AdaptiveAvgPool1d(output_size=1)
self.fc = nn.Linear(hidden_size * 2, num_classes)
self.apply(self.init_weights)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x) # Added ReLU after Batch Normalization
x = self.maxpool(x)
x = self.relu2(x) # Added ReLU after MaxPooling
x = self.dropout1(x)
x = x.permute(0, 2, 1)
x, _ = self.bi_gru(x)
x = self.dropout2(x)
x = self.ap(x.permute(0, 2, 1))
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def init_weights(self, m):
if isinstance(m, nn.Conv1d) or isinstance(m, nn.Linear):
init.kaiming_normal_(m.weight)
model_cnn_bigru = CNN_BiGRU_Model(num_classes, input_size, hidden_size, num_layers)
model_cnn_bigru.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_cnn_bigru.parameters(), lr=0.001)
# Print the modified model structure
print(model_cnn_bigru)
total_params = sum(p.numel() for p in model_cnn_bigru.parameters())
print(f"Total parameters: {total_params}")
CNN_BiGRU_Model(
(conv1): Conv1d(1, 16, kernel_size=(3,), stride=(1,), padding=(4,))
(bn1): BatchNorm1d(16, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu1): ReLU()
(maxpool): MaxPool1d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
(relu2): ReLU()
(dropout1): Dropout(p=0.2, inplace=False)
(bi_gru): GRU(16, 96, num_layers=2, batch_first=True, bidirectional=True)
(dropout2): Dropout(p=0.2, inplace=False)
(ap): AdaptiveAvgPool1d(output_size=1)
(fc): Linear(in_features=192, out_features=4, bias=True)
)
Total parameters: 233572
%%time
# 调用训练函数
num_epochs = 30 # 练的epoch数
training(model_cnn_bigru, train_dl, val_dl, num_epochs,"cnn_gru")
Epoch: 1, Train Loss: 1.3670, Train Accuracy: 0.2834, Val Loss: 1.3249, Val Accuracy: 0.2532
Epoch: 2, Train Loss: 1.2459, Train Accuracy: 0.4479, Val Loss: 1.1914, Val Accuracy: 0.6883
Epoch: 3, Train Loss: 1.0152, Train Accuracy: 0.6792, Val Loss: 0.8742, Val Accuracy: 0.8766
Epoch: 4, Train Loss: 0.6580, Train Accuracy: 0.7524, Val Loss: 0.7777, Val Accuracy: 0.6753
Epoch: 5, Train Loss: 0.4505, Train Accuracy: 0.8958, Val Loss: 0.2994, Val Accuracy: 0.9740
Epoch: 6, Train Loss: 0.3295, Train Accuracy: 0.9430, Val Loss: 0.2863, Val Accuracy: 0.9805
Epoch: 7, Train Loss: 0.3047, Train Accuracy: 0.9788, Val Loss: 0.2800, Val Accuracy: 0.9870
Epoch: 8, Train Loss: 0.2902, Train Accuracy: 0.9935, Val Loss: 0.2661, Val Accuracy: 1.0000
Epoch: 9, Train Loss: 0.2856, Train Accuracy: 1.0000, Val Loss: 0.2685, Val Accuracy: 1.0000
Epoch: 10, Train Loss: 0.2851, Train Accuracy: 0.9984, Val Loss: 0.2696, Val Accuracy: 0.9935
Epoch: 11, Train Loss: 0.2869, Train Accuracy: 0.9984, Val Loss: 0.2622, Val Accuracy: 1.0000
Epoch: 12, Train Loss: 0.2736, Train Accuracy: 1.0000, Val Loss: 0.2641, Val Accuracy: 1.0000
Epoch: 13, Train Loss: 0.2818, Train Accuracy: 0.9984, Val Loss: 0.2633, Val Accuracy: 1.0000
Epoch: 14, Train Loss: 0.2801, Train Accuracy: 0.9951, Val Loss: 0.2680, Val Accuracy: 0.9935
Epoch: 15, Train Loss: 0.2806, Train Accuracy: 0.9984, Val Loss: 0.2628, Val Accuracy: 1.0000
Epoch: 16, Train Loss: 0.2813, Train Accuracy: 0.9967, Val Loss: 0.2612, Val Accuracy: 1.0000
Epoch: 17, Train Loss: 0.2841, Train Accuracy: 0.9984, Val Loss: 0.2645, Val Accuracy: 1.0000
Epoch: 18, Train Loss: 0.2825, Train Accuracy: 0.9984, Val Loss: 0.2608, Val Accuracy: 1.0000
Epoch: 19, Train Loss: 0.2791, Train Accuracy: 0.9967, Val Loss: 0.2668, Val Accuracy: 1.0000
Epoch: 20, Train Loss: 0.2814, Train Accuracy: 0.9967, Val Loss: 0.2681, Val Accuracy: 1.0000
Epoch: 21, Train Loss: 0.3017, Train Accuracy: 0.9935, Val Loss: 0.2656, Val Accuracy: 0.9935
Epoch: 22, Train Loss: 0.2814, Train Accuracy: 0.9967, Val Loss: 0.2644, Val Accuracy: 1.0000
Epoch: 23, Train Loss: 0.2915, Train Accuracy: 0.9967, Val Loss: 0.2606, Val Accuracy: 1.0000
Epoch: 24, Train Loss: 0.2835, Train Accuracy: 0.9951, Val Loss: 0.2622, Val Accuracy: 1.0000
Epoch: 25, Train Loss: 0.2792, Train Accuracy: 1.0000, Val Loss: 0.2639, Val Accuracy: 0.9935
Epoch: 26, Train Loss: 0.2891, Train Accuracy: 0.9984, Val Loss: 0.2632, Val Accuracy: 1.0000
Epoch: 27, Train Loss: 0.2932, Train Accuracy: 0.9967, Val Loss: 0.2624, Val Accuracy: 1.0000
Epoch: 28, Train Loss: 0.2798, Train Accuracy: 0.9951, Val Loss: 0.2644, Val Accuracy: 0.9935
Epoch: 29, Train Loss: 0.2960, Train Accuracy: 0.9902, Val Loss: 0.2640, Val Accuracy: 1.0000
Epoch: 30, Train Loss: 0.2810, Train Accuracy: 0.9951, Val Loss: 0.2624, Val Accuracy: 1.0000
Finished Training. Best model saved from epoch 23 as best_model_cnn_gru.pth.
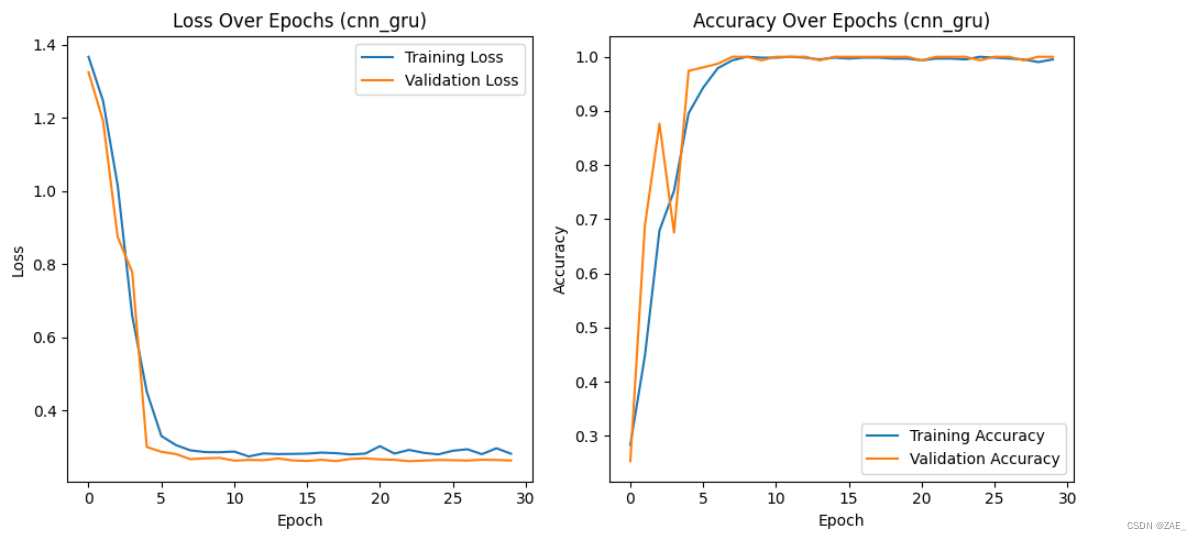
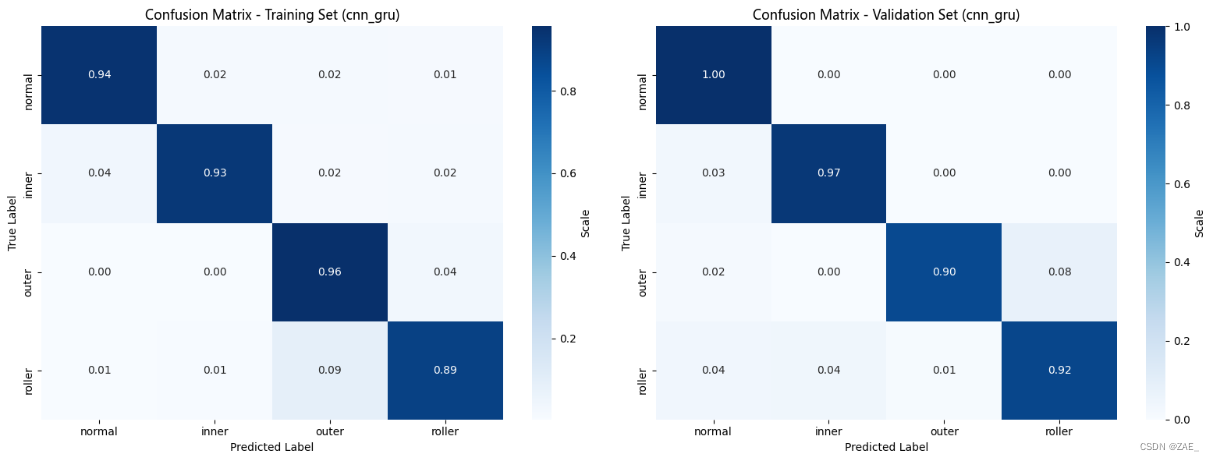
CPU times: total: 10.9 s
Wall time: 18.3 s
七、模型推理测试
测试数据预处理
将测试数据test.csv转为npy文件方便读取(只需运行一次)
# test_df = pd.read_csv('test_data.csv')
# data_test = test_df.values
# print(data_test.shape)
# np.save('data_test.npy', data_test)
data_test = np.load('data_test.npy')
print(data_test.shape)
(48, 40960)
数据截取
%%time
# 截取测试集序列
data_test_del = data_test[:, :5000]
print(data_test_del.shape)
(48, 5000)
CPU times: total: 0 ns
Wall time: 0 ns
与训练数据相同的预处理操作(替换异常值、去趋势化、小波变换、数据加载)
# 替换异常值
data_re = remove_outliers(data_test_del)
# 去趋势化
data_test_detrend = detrend_data(data_re, period=4)
# 小波变换
test_transformed_coeffs = wavelet_transform(data_test_detrend)
data_test_wave = extract_third_level_wavelet(test_transformed_coeffs)
print(data_test_wave.shape)
data_test_fin = data_test_wave.reshape(-1, 1, 1252)
print(data_test_fin.shape)
# 为测试数据集创建一个 DataLoader
test_dataset = [(torch.Tensor(data), -1) for data in data_test_fin] # 假设推断时所有标签都为 0
test_dl = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
# 查看输入数据格式
test_dl_batch_shape = next(iter(test_dl))[0].shape
test_dl_num_batches = len(test_dl)
print("Batch shape:", test_dl_batch_shape)
print("Number of batches:", test_dl_num_batches)
(48, 1252)
(48, 1, 1252)
Batch shape: torch.Size([48, 1, 1252])
Number of batches: 1
推理测试函数
# 定义推断函数
def inference(model, test_dl):
predictions = []
# 禁用梯度更新
with torch.no_grad():
for data in test_dl:
# 获取输入特征并将其放在GPU上
inputs = data[0].to(device)
# 标准化输入
inputs_m, inputs_s = inputs.mean(), inputs.std()
inputs = (inputs - inputs_m) / inputs_s
# 获取预测结果
outputs = model(inputs)
# 获取具有最高分数的预测类别
_, prediction = torch.max(outputs, 1)
# 将预测结果添加到列表中
predictions.extend(prediction.tolist())
print('Finished inference')
return predictions
三种模型创建实例、加载最佳模型、进行推理预测
# 载入已训练的best.model
test_model_CNN_1D_2L = CNN_1D_2L(input_size) # 创建实例
test_model_CNN_1D_2L.load_state_dict(torch.load('best_model_CNN_1D_2L.pth')) # 加载预训练模型参数
test_model_CNN_1D_2L = test_model_CNN_1D_2L.to(device) # 将模型移动到指定的设备上
# 载入已训练的best.model
test_model_cnn_resblock = CNN_ResNet_model(num_classes, input_size, num_inchannel) # 创建实例
test_model_cnn_resblock.load_state_dict(torch.load('best_model_cnn_resblock.pth')) # 加载预训练模型参数
test_model_cnn_resblock = test_model_cnn_resblock.to(device) # 将模型移动到指定的设备上
# 载入已训练的best.model
test_model_cnn_bigru = CNN_BiGRU_Model(num_classes, input_size, hidden_size, num_layers) # 创建实例
test_model_cnn_bigru.load_state_dict(torch.load('best_model_cnn_gru.pth')) # 加载预训练模型参数
test_model_cnn_bigru = test_model_cnn_bigru.to(device) # 将模型移动到指定的设备上
predictions1 = inference(test_model_CNN_1D_2L, test_dl)
predictions2 = inference(test_model_cnn_resblock, test_dl)
predictions3 = inference(test_model_cnn_bigru, test_dl)
Finished inference
Finished inference
Finished inference
推理测试结果展示
def save_and_plot_predictions(predictions, model_name):
colors = ['#FF3030', '#436EEE', '#FFA500', '#FA8072'] # 根据需要修改颜色
label_mapping = {'normal': 0, 'inner': 1, 'outer': 2, 'roller': 3}
# 使用label_mapping将预测结果映射到原始标签
reversed_label_mapping = {v: k for k, v in label_mapping.items()}
mapped_predictions = [reversed_label_mapping[prediction] for prediction in predictions]
# 创建包含结果的DataFrame
filename = f'test_result_{model_name}.csv'
results = pd.DataFrame({'name': [f'sample {i}' for i in range(len(predictions))],
'type': mapped_predictions})
# 计算预测类型的分布
predicted_counts = results['type'].value_counts()
# 绘制饼状图
plt.figure(figsize=(8, 4))
plt.pie(predicted_counts, labels=predicted_counts.index, autopct='%1.1f%%', startangle=90, colors=colors)
# 添加图例
plt.legend(title='label', loc='upper left', bbox_to_anchor=(1, 0.5))
# 添加标题
plt.title(f'预测结果轴承状态分布_{model_name}', fontproperties=font_prop, fontsize=14)
# 保存图表为图片
plt.savefig(f'预测结果轴承状态分布_{model_name}.png')
# 显示图表(可选)
plt.show()
return predicted_counts
save_and_plot_predictions(predictions1, model_name="test_model_CNN_1D_2L")
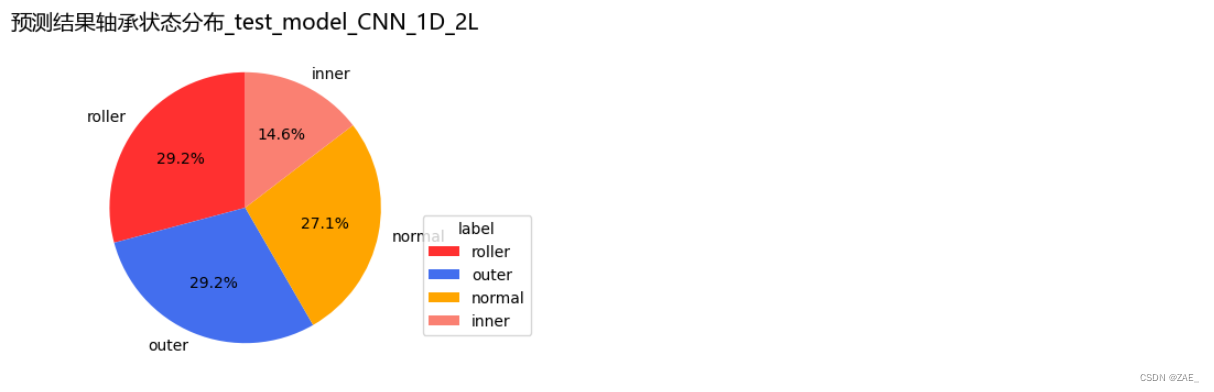
type
roller 14
outer 14
normal 13
inner 7
Name: count, dtype: int64
save_and_plot_predictions(predictions2, model_name="test_model_cnn_resblock")

type
roller 15
outer 14
normal 13
inner 6
Name: count, dtype: int64
save_and_plot_predictions(predictions3, model_name="test_model_cnn_bigru")

type
roller 14
normal 14
outer 14
inner 6
Name: count, dtype: int64
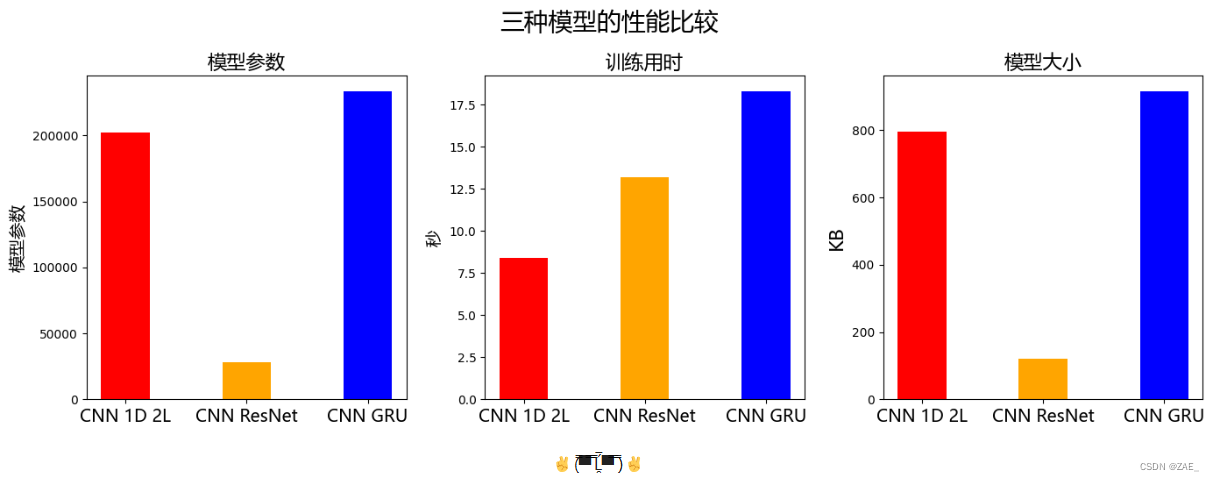
八、三种模型对比
# 模型信息
model_names = ['CNN 1D 2L', 'CNN ResNet', 'CNN GRU']
model_params = [202372, 27972, 233572]
model_times = [8.4, 13.2, 18.3]
model_sizes = [795, 120, 916]
bar_width = 0.4
bar_color = ['red', 'orange', 'blue']
# 创建一个画布,设置大小和标题
fig, axes = plt.subplots(1, 3, figsize=(14, 5))
fig.suptitle('三种模型的性能比较', fontproperties=font_prop, fontsize=20)
# 绘制模型参数的子图
axes[0].bar(np.arange(len(model_names)), model_params, width=bar_width, color=bar_color)
axes[0].set_xticks(np.arange(len(model_names)))
axes[0].set_xticklabels(model_names, fontproperties=font_prop)
axes[0].set_ylabel('模型参数', fontproperties=font_prop, fontsize=14)
axes[0].set_title('模型参数', fontproperties=font_prop, fontsize=16)
# 绘制训练用时的子图
axes[1].bar(np.arange(len(model_names)), model_times, width=bar_width, color=bar_color)
axes[1].set_xticks(np.arange(len(model_names)))
axes[1].set_xticklabels(model_names, fontproperties=font_prop)
axes[1].set_ylabel('秒', fontproperties=font_prop, fontsize=14)
axes[1].set_title('训练用时', fontproperties=font_prop, fontsize=16)
# 绘制模型大小的子图
axes[2].bar(np.arange(len(model_names)), model_sizes, width=bar_width, color=bar_color)
axes[2].set_xticks(np.arange(len(model_names)))
axes[2].set_xticklabels(model_names, fontproperties=font_prop)
axes[2].set_ylabel('KB', fontproperties=font_prop, fontsize=16)
axes[2].set_title('模型大小', fontproperties=font_prop, fontsize=16)
# 调整子图之间的间距
fig.tight_layout()
# 显示图形
plt.show()















 5669
5669











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









