







 超级会员免费看
超级会员免费看
在“04 讲和 05 讲”里,我们介绍了基于 Binlog 实现的全量缓存的读服务,以及如何实现一个低延迟、可扩展的同步架构。通过这两讲的学习,你可以构建出一个无毛刺且平均性能在 100ms 以内的读接口。对缓存进行分布式部署后,抗住秒级百万的 QPS 毫无压力。不管是在面试还是在实战中,关于“如何架构一个高性能的读服务”,我相信你都能够轻松应对。
但上述的“百万 QPS”有一个非常重要的限制条件,即这百万的 QPS 都是分属于不同用户的。我们先不讨论是否可能,试想一下如果这百万 QPS 都属于同一个用户,系统还扛得住吗?
如果采用前两讲的架构,必然抗扛不住的!因此本讲将站在一个全新的视角,带你分析此架构待改善的方向,并探寻新的架构优化方案来应对百万 QPS的流量。
为什么扛不住相同用户百万的流量
当百万的 QPS 属于不同用户时,因缓存是集群化的,所有到达业务后台的请求会根据一定路由规则(如 Hash),分散到请求缓存集群中的某一个节点,具体架构如下图 1 所示:
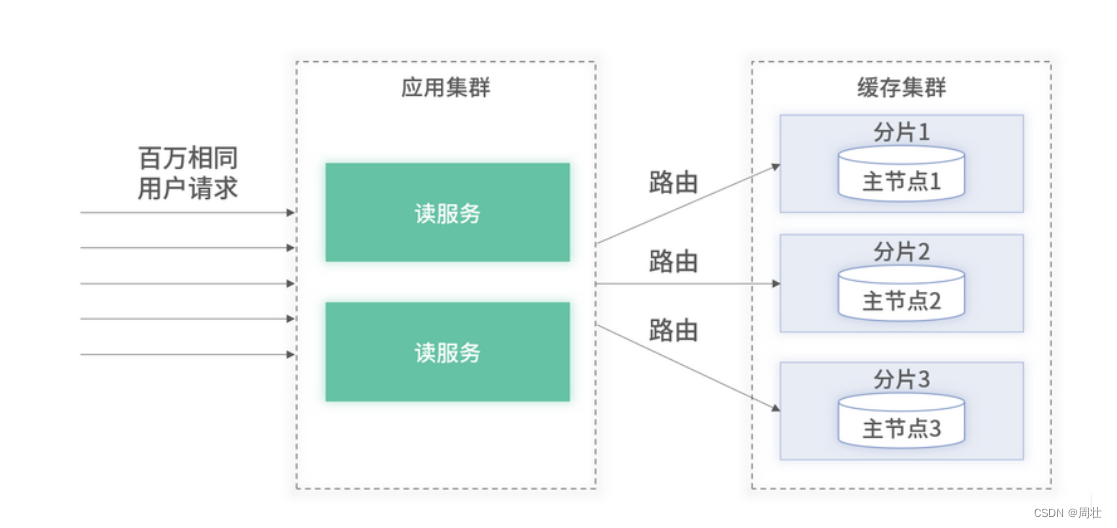
图 1:百万请求属于不同用户的架构图
假设一个节点最大能够支撑 10W QPS,我们只需要在集群中部署 10 台节点即可支持百万流量。但当百万 QPS 都属于同一用户时,即使缓存是集群化的,同一个用户的请求都会被路由至集群中的某一个节点,整体架构如图 2 所示:

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 132
132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











