







定义
一种分类算法,主要用于处理二分类问题
说白了就是 发生 or 不发生
比如:患病 没病;还钱 老赖
作用
将线性回归的结果映射到0和1之间,从而对分类问题进行建模(如果中间节点定义为0.5,那么大于0.5为1,小于为0)
那么,怎样分类呢?
Sigmoid函数
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)= \frac {1} {1+e^{-x}}
σ(x)=1+e−x1
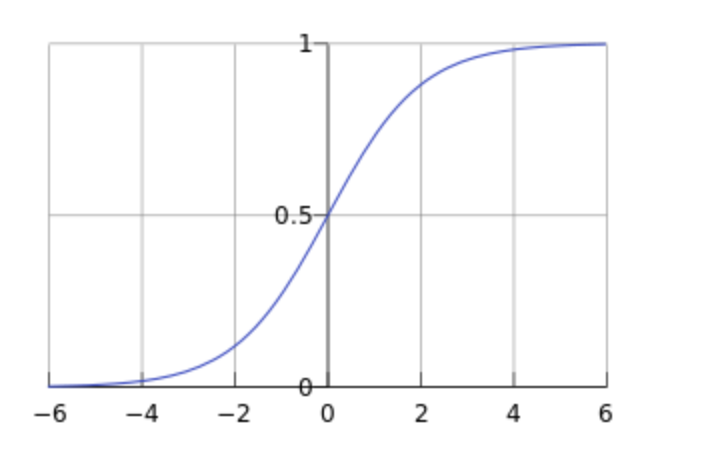
- 基本特性
- 取值范围:Sigmoid函数将任何输入映射到0和1之间。
- 单调性:函数是单调递增的,这意味着当输入值增加时,输出值也相应地增加。
- 平滑性:Sigmoid函数平滑且连续,这有助于在实践中有效地计算梯度。
- 优缺点
- 优点:由于其输出范围是0到1,适合用作二分类问题中的概率预测;函数是可微的,有利于梯度的计算和反向传播。
- 缺点:在输入值极大或极小的情况下,Sigmoid函数的梯度接近于零,这会导致在深度神经网络中的梯度消失问题,影响网络的训练效果。
- 应用案例
- 逻辑回归:在逻辑回归模型中,Sigmoid函数被用来将线性组合的结果映射为概率值,从而预测属于某一类的概率。
- 神经网络:在人工神经网络中,Sigmoid函数常作为隐藏层的激活函数,引入非线性,使网络能够解决复杂的问题。
- 数学性质
- 导数:Sigmoid函数的导数可以由其自身表示,即 σ ′ ( x ) = σ ( x ) ⋅ ( 1 − σ ( x ) ) \sigma^{\prime}(x) = \sigma(x) \cdot (1 - \sigma(x)) σ′(x)=σ(x)⋅(1−σ(x)),这使得在计算反向传播时的梯度变得简单。
- 对称性:函数在0.5处对称,这符合二分类问题的需求,其中0.5可以作为事件发生与否的分界点。
原理
- 线性回归方程
w 0 + w 1 x 1 + . . . + w n x n = ∑ i = 1 n w i x i = w T x w_0 + w_1x_1 + ... + w_nx_n = \sum_{i=1}^{n}w_ix_i = w^Tx w0+w1x1+...+wnxn=∑i=1nwixi=wTx
- Sigmoid函数
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x)= \frac {1} {1+e^{-x}}
σ(x)=1+e−x1
将线性回归方程带入Sigmoid函数
σ
(
x
)
=
1
1
+
e
−
w
T
x
\sigma(x)= \frac {1} {1+e^{-w^Tx}}
σ(x)=1+e−wTx1
- 决策边界
在二分类问题中,如果预测的概率大于某个阈值(通常为0.5),则预测结果为正类(例如1),否则为负类(例如0)。这个阈值决定了分类的决策边界。
损失函数与优化
为了训练模型,我们需要定义一个损失函数来衡量预测值与实际值之间的差距。逻辑回归常用的是对数似然损失函数,也称为交叉熵损失(Cross-Entropy Loss)。对于二分类问题,损失函数可以表示为:
L
(
y
,
y
^
)
=
−
[
y
log
(
y
^
)
+
(
1
−
y
)
log
(
1
−
y
^
)
]
L(y,\hat y) = -[y\log(\hat y) + (1-y)\log (1-\hat y)]
L(y,y^)=−[ylog(y^)+(1−y)log(1−y^)]
其中,y 是真实标签,
y
^
\hat y
y^ 是预测概率。目标是最小化整个数据集上的平均损失,这通常通过梯度下降等优化算法来实现。
梯度下降参考 第一章 线性回归
代码
import numpy as np
# 数据生成
np.random.seed(0)
X = 2 * np.random.rand(100, 2) - 1 # 100个样本,每个样本2个特征
y = (np.dot(X, np.array([0.5, 0.3])) + -0.2 + 0.1 * np.random.randn(100)) > 0 # 真实逻辑回归模型为y = 0.5x1 + 0.3x2 - 0.2 + 噪声
# 参数初始化
theta = np.zeros(X.shape[1]) # 初始参数设置为0
# 定义Sigmoid函数
def sigmoid(z):
return 1 / (1 + np.exp(-z))
# 定义损失函数及其梯度
def loss_function(theta, X, y):
predictions = sigmoid(np.dot(X, theta))
errors = predictions - y
gradient = np.dot(X.T, errors) / len(X)
return np.sum(errors ** 2) / len(errors), gradient
# 梯度上升优化
learning_rate = 0.1
iterations = 1000
for i in range(iterations):
loss, gradient = loss_function(theta, X, y)
theta -= learning_rate * gradient # 参数更新
if i % 100 == 0:
print(f"Iteration {i}, Loss: {loss}, Theta: {theta}")
# 模型预测
predictions = sigmoid(np.dot(X, theta)) > 0.5
accuracy = np.mean(predictions == y)
print(f"Accuracy: {accuracy}")
完整代码
https://github.com/zz-wenzb/ai-study/tree/master/%E9%80%BB%E8%BE%91%E5%9B%9E%E5%BD%92
















 801
801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









