






定义
自然语言处理(NLP)中的一种关键技术,它将词语表示为多维空间中的向量形式。这种表示方法允许计算机理解和处理文本数据,并捕捉到词语之间的语义和语法关系。
静态词向量
Word2Vec
Word2Vec 是一种流行的词向量模型,它被设计用来从文本数据中学习高质量的词向量。Word2Vec 可以捕捉到词语之间的语义关系,并且在很多自然语言处理任务中取得了非常好的效果。
基本概念
Word2Vec 主要有两种模型架构:CBOW(Continuous Bag of Words)和 Skip-gram。
- CBOW:该模型的目标是从给定的上下文预测中心词。
- Skip-gram:该模型的目标是从中心词预测其上下文。
CBOW 架构
- 输入层:将上下文词语转换为独热编码(one-hot encoding)形式。
- 隐藏层:通过矩阵乘法将独热编码转换为词向量。
- 输出层:再次通过矩阵乘法,从词向量预测中心词的概率分布。
Skip-gram 架构
- 输入层:将中心词转换为独热编码。
- 隐藏层:通过矩阵乘法将独热编码转换为词向量。
- 输出层:多次通过矩阵乘法,从词向量预测上下文词语的概率分布。
训练目标
- CBOW 的目标是最小化中心词与上下文词语之间的差异。
- Skip-gram 的目标是最小化上下文词语与中心词之间的差异。
训练过程
- 初始化参数:随机初始化词向量。
- 前向传播:根据输入数据进行前向传播,计算预测概率。
- 损失函数:计算预测概率与实际概率之间的差距(使用交叉熵损失)。
- 反向传播:根据损失函数的梯度更新词向量。
- 迭代训练:重复上述过程直到收敛。
优化技巧
- 负采样:在训练过程中,只选取一部分非目标词语作为负样本参与训练,以减少计算复杂度。
- 层次softmax:另一种减少计算复杂度的方法,通过构建一棵层次化的输出树来替代传统的 softmax 分类器。
使用 Gensim 实现 Word2Vec
from gensim.models import Word2Vec
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
import nltk
nltk.download('punkt') # 下载NLTK的分词器数据
from nltk.tokenize import word_tokenize
# 示例文本
text_data = [
"The quick brown fox jumps over the lazy dog.",
"A journey of a thousand miles begins with a single step.",
"The best time to plant a tree was twenty years ago.",
"Success is not final, failure is not fatal: it is the courage to continue that counts."
]
# 预处理函数
def preprocess(text):
return [token for token in simple_preprocess(text) if token not in STOPWORDS and len(token) > 3]
# 将文本数据预处理
processed_data = [preprocess(doc) for doc in text_data]
# 创建Word2Vec模型
model = Word2Vec(
sentences=processed_data,
vector_size=100, # 词向量的维度
window=5, # 上下文窗口大小
min_count=1, # 忽略所有出现次数少于该值的词
workers=4, # 使用的线程数
sg=1 # 使用 Skip-gram 模型(sg=0 表示使用 CBOW)
)
# 训练模型
model.train(processed_data, total_examples=len(processed_data), epochs=100)
# 保存模型
model.save("word2vec.model")
# 加载模型
# model = Word2Vec.load("word2vec.model")
# 获取词向量
word_vector = model.wv["success"]
print(word_vector)
# 计算相似度
similarity = model.wv.similarity("success", "failure")
print(f"Similarity between 'success' and 'failure': {similarity}")
# 类比推理
result = model.wv.most_similar(positive=["journey"], negative=["thousand"])
print(result)
解释:
- 数据预处理:
- 使用
simple_preprocess进行简单的文本清理,并移除停用词。 - 将文本数据组织成一个句子列表。
- 使用
- 创建Word2Vec模型:
- 设置模型参数,如词向量维度、窗口大小等。
- 使用 Skip-gram 模型(通过设置
sg=1)。
- 训练模型:
- 使用训练数据调用
train方法。
- 使用训练数据调用
- 使用模型:
- 保存训练好的模型。
- 加载模型并使用它来获取词向量、计算相似度以及进行类比推理。
总结
Word2Vec 是一种强大的工具,用于从文本数据中学习词向量。它能够捕捉词语之间的复杂关系,并在多种自然语言处理任务中发挥重要作用。
GloVe
基本概念
GloVe 的核心思想是通过全局矩阵因子化来学习词向量。它基于词语共现矩阵(co-occurrence matrix),并试图最小化词语向量之间预测共现计数的误差。
共现矩阵
共现矩阵记录了词语对在文本中一起出现的频率。例如,对于词语 ( w i w_i wi ) 和 ( w j w_j wj ),共现矩阵中的元素 C i j C_{ij} Cij 表示词语 w i w_i wi 和词语 w j w_j wj 在一定范围内共同出现的次数。
目标函数
GloVe 的目标函数试图最小化预测共现矩阵
C
^
i
j
\hat{C}{ij}
C^ij_ 和实际共现矩阵 _
C
i
j
C{ij}
Cij 之间的差异。预测共现矩阵是通过词语向量
v
i
\mathbf{v}_i
vi 和
u
j
\mathbf{u}_j
uj 的点积计算得出的,其中
v
i
\mathbf{v}_i
vi 和
u
i
\mathbf{u}_i
ui 分别是词语 ( i ) 的输入向量和输出向量。
目标函数可以表示为:
minimize
∑
i
,
j
f
(
C
i
j
)
(
v
i
⊤
u
j
−
log
C
i
j
)
2
\text{minimize } \sum_{i,j} f(C_{ij}) \left(\mathbf{v}_i^\top \mathbf{u}_j - \log C_{ij}\right)^2
minimize ∑i,jf(Cij)(vi⊤uj−logCij)2__其中 ( _
f
(
C
i
j
)
f(C_{ij})
f(Cij)) 是一个权重函数,用于调节不同共现计数的影响。常用的权重函数是:
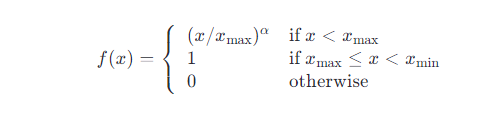
这里 x max x_{\text{max}} xmax 和 x min x_{\text{min}} xmin 分别是阈值 α \alpha α 是一个超参数,默认值通常为 0.75。
训练过程
- 初始化词向量:随机初始化词语的输入向量和输出向量。
- 计算共现矩阵:构建共现矩阵,记录词语之间的共现频率。
- 定义权重函数:根据共现矩阵的值定义权重函数 ( f(C_{ij}) )。
- 优化目标函数:使用梯度下降或其他优化算法最小化目标函数。
- 迭代训练:重复上述过程直到达到预定的迭代次数或满足收敛条件。
代码
from gensim.scripts.glove2word2vec import glove2word2vec
from gensim.models import KeyedVectors
from gensim.test.utils import datapath, get_tmpfile
from gensim.utils import simple_preprocess
from gensim.parsing.preprocessing import STOPWORDS
import nltk
nltk.download('punkt') # 下载NLTK的分词器数据
from nltk.tokenize import word_tokenize
# 示例文本
text_data = [
"The quick brown fox jumps over the lazy dog.",
"A journey of a thousand miles begins with a single step.",
"The best time to plant a tree was twenty years ago.",
"Success is not final, failure is not fatal: it is the courage to continue that counts."
]
# 预处理函数
def preprocess(text):
return [token for token in simple_preprocess(text) if token not in STOPWORDS and len(token) > 3]
# 将文本数据预处理
processed_data = [preprocess(doc) for doc in text_data]
# 保存处理后的数据为 GloVe 输入格式
with open('glove_input.txt', 'w', encoding='utf-8') as file:
for sentence in processed_data:
file.write(' '.join(sentence) + '\n')
# 使用 GloVe 工具训练模型
glove_input_file = 'glove_input.txt'
glove_output_file = 'glove_output.txt'
# GloVe 命令行工具路径
glove_tool_path = '/path/to/glove/build/glove'
# 执行 GloVe 命令
!{glove_tool_path} -input-file {glove_input_file} -output-file {glove_output_file} \
-x-max 10 -iter 100 -vector-size 100 -binary 0 -threads 4 -min-count 5
# 将 GloVe 输出转换为 Gensim 可读格式
glove2word2vec(glove_output_file, 'glove_word2vec.txt')
# 加载转换后的模型
glove_w2v_model = KeyedVectors.load_word2vec_format('glove_word2vec.txt')
# 获取词向量
word_vector = glove_w2v_model["success"]
print(word_vector)
# 计算相似度
similarity = glove_w2v_model.similarity("success", "failure")
print(f"Similarity between 'success' and 'failure': {similarity}")
# 类比推理
result = glove_w2v_model.most_similar(positive=["journey"], negative=["thousand"])
print(result)
解释:
- 数据预处理:
- 使用
simple_preprocess进行简单的文本清理,并移除停用词。 - 将文本数据组织成一个句子列表,并保存为文本文件。
- 使用
- 训练 GloVe 模型:
- 使用 GloVe 的命令行工具训练模型。
- 设置模型参数,如向量尺寸、迭代次数等。
- 使用模型:
- 将训练好的 GloVe 模型转换为 Gensim 可读的格式。
- 加载模型并使用它来获取词向量、计算相似度以及进行类比推理。
总结
GloVe 是一种有效的词向量学习方法,它通过全局矩阵因子化来捕捉词语之间的统计关系。
动态词向量(了解)
ELMo
ELMo(Embeddings from Language Models)是一种上下文相关的词嵌入方法,由Allen Institute for AI在2018年提出。ELMo通过双向语言模型(biLM)来学习词嵌入,这些嵌入能够根据词在句子中的具体上下文而变化。这与传统的词嵌入方法如Word2Vec或GloVe不同,后者为每个词提供一个固定不变的向量表示。
工作原理
- 双向语言模型 (biLM):
- ELMo 使用两个独立的LSTM(长短时记忆网络)层来处理输入文本序列,一个正向LSTM从左到右读取文本,另一个反向LSTM从右到左读取文本。这样可以捕捉到词在句子中的前向和后向上下文信息。
- 多层表示:
- 每个LSTM层都会产生一系列的隐藏状态,这些状态可以看作是在不同抽象层次上的词表示。ELMo 通常会使用这些不同层的隐藏状态的加权平均作为最终的词嵌入。
- 任务特定的微调:
- 在具体的NLP任务中,ELMo 的词嵌入可以进一步微调以适应特定的任务。这意味着ELMo嵌入不仅基于原始训练数据,还会考虑特定任务的数据和上下文。
- 特征提取器:
- ELMo 通常作为其他NLP系统的特征提取器使用,而不是单独作为一个模型。ELMo 产生的词嵌入可以被下游任务所使用,比如情感分析、问答系统等。
优点
- 上下文敏感性:
- ELMo 的词嵌入能够考虑到词的具体上下文,这对于处理一词多义等问题非常有效。
- 动态词向量:
- 与静态词嵌入相比,ELMo 的动态词嵌入能够更好地反映词义的变化。
- 灵活性:
- ELMo 可以很容易地集成到现有的NLP系统中,不需要对这些系统进行重大修改。
示例代码
import torch
from allennlp.modules.elmo import Elmo, batch_to_ids
# 初始化ELMo模型
options_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_options.json"
weight_file = "https://s3-us-west-2.amazonaws.com/allennlp/models/elmo/2x4096_512_2048cnn_2xhighway/elmo_2x4096_512_2048cnn_2xhighway_weights.hdf5"
elmo = Elmo(options_file, weight_file, 1, dropout=0)
# 准备输入数据
sentences = ["The cat is on the mat.", "There is a mat under the cat."]
character_ids = batch_to_ids(sentences)
# 使用ELMo得到词嵌入
embeddings = elmo(character_ids)
# 提取词嵌入
word_embeddings = embeddings['elmo_representations'][0]
mask = embeddings['mask']
# 输出词嵌入的形状
print(word_embeddings.shape)
结论
ELMo 是一种创新的词嵌入方法,它能够捕捉词的上下文信息,从而在多种NLP任务中表现出色。通过使用预训练的ELMo模型,研究者和开发者可以轻松地将其集成到他们的项目中,以提高模型的性能
BERT
BERT(Bidirectional Encoder Representations from Transformers)是由Google在2018年提出的一种预训练语言模型,它在自然语言处理领域产生了革命性的影响。BERT 的主要特点是它能够生成上下文相关的词嵌入,并且能够双向地处理文本数据。下面详细介绍 BERT 的原理和使用方法。
工作原理
双向编码:
- BERT 使用 Transformer 架构的编码器部分来处理输入文本。与传统的语言模型(如 LSTM)不同,Transformer 编码器能够同时访问文本序列的所有部分,因此能够双向地处理上下文信息。
Masked Language Model (MLM):
- BERT 使用 Masked Language Model 作为一种预训练策略。在预训练阶段,BERT 随机遮掩(mask)输入文本中的某些词,并尝试预测这些被遮掩的词。这种方法使模型能够学习到词语在其上下文中的含义。
Next Sentence Prediction (NSP):
- BERT 还使用 Next Sentence Prediction 任务来帮助模型学习句子级别的关系。在预训练过程中,BERT 接收两个连续的句子,并尝试预测第二个句子是否真的是第一个句子的下一个句子。
Transformer 编码器:
- BERT 使用多层 Transformer 编码器,每个编码器层都包含自注意力机制(self-attention)和前馈神经网络(feed-forward network)。自注意力机制使得模型能够在处理每个词时考虑文本序列中的所有其他词。
多层表示:
- BERT 的每一层都会产生词的表示,这些表示可以单独使用,也可以组合起来使用。通常,最后一层的输出被视为最完整的词表示。
微调:
- 在特定任务中,BERT 模型可以进一步微调以适应特定任务的需求。微调阶段通常是在预训练的基础上进行的,这意味着模型已经学习到了丰富的语言知识。
优点
- 上下文敏感性:
- BERT 的词嵌入能够根据词在句子中的具体上下文而变化,这对于处理一词多义等问题非常有效。
- 双向处理:
- BERT 能够同时考虑词的前后上下文信息,这有助于更好地理解文本的含义。
- 灵活性:
- BERT 可以很容易地适应多种NLP任务,如文本分类、命名实体识别、问答系统等。
示例代码
from transformers import BertTokenizer, BertModel
import torch
# 初始化 BERT 模型和分词器
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# 准备输入数据
text = "Here is some text to encode."
inputs = tokenizer(text, return_tensors="pt") # 使用分词器对文本进行编码
# 使用 BERT 得到词嵌入
with torch.no_grad():
outputs = model(**inputs)
# 提取词嵌入
last_hidden_states = outputs.last_hidden_state
# 输出词嵌入的形状
print(last_hidden_states.shape)
结论
BERT 是一种非常强大的语言模型,它能够生成高质量的上下文敏感词嵌入,并且在多种自然语言处理任务中表现出色。通过使用预训练的 BERT 模型,研究者和开发者可以轻松地将其集成到他们的项目中,以提高模型的性能。
步骤
1. 数据预处理
- 文本清洗:去除无关的字符(如标点符号)、数字等,保留纯文本内容。
- 分词:将文本分割成单独的词语或标记。
- 标准化:转换为小写、去除停用词(如“the”, “is”, “at”, “which”等)、词干提取或词形还原等。
2. 训练词向量模型
- 选择模型:根据任务需求选择合适的词向量模型,如 Word2Vec、GloVe 或者 BERT 等。
- 设置参数:
- 窗口大小:确定用于构建词语上下文的范围。
- 维度:决定生成的词向量的长度。
- 最小频率:忽略低频词语。
- 其他特定于模型的参数:如 Word2Vec 中的
negative(负采样数量)和iter(迭代次数)等。
3. 训练过程
- 加载或创建语料库:如果使用预训练模型,则直接加载;如果是自己训练,则需要构建自己的语料库。
- 训练:让模型根据语料库中的词语上下文进行学习,不断调整词向量的值以优化损失函数。
4. 评估与优化
- 评估词向量质量:可以通过内在评价(如词汇相似度任务)和外在评价(如在下游任务上的性能)来评估。
- 调整参数:根据评估结果调整模型参数,以提高词向量的质量。
5. 应用词向量
- 查询词向量:使用训练好的模型查询单个词语的向量表示。
- 计算相似性:使用词向量计算词语间的相似度(如余弦相似度)。
- 词类比推理:利用词向量做类比推理任务,如“国王 - 男人 + 女人 = 女王”。
- 应用到下游任务:将词向量应用于特定的自然语言处理任务中,如文本分类、情感分析等。
















 423
423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









