






关联规则学习是数据挖掘中的一种方法,用于发现数据集中有趣的关系或相关性。这些关系通常表示为“如果-那么”形式的规则,表明某些事件的发生与另一些事件的发生有关联。例如,在超市购物篮分析中,一个典型的关联规则可能是“如果顾客购买了面包和牛奶,则他们也很可能购买黄油”。
基本概念
- 项集(Itemset):
项集是一组物品的集合。
例如:{牛奶, 面包}。
- 频繁项集(Frequent Itemset):
频繁项集是指在数据集中出现频率超过某个阈值(最小支持度)的项集。
例如:如果{牛奶, 黄油}在交易记录中至少出现了5%的次数,则它是一个频繁项集。
- 支持度(Support):
支持度是一个项集出现在数据库中的频率。
计算公式为:$ \text{support}(X) = \frac{\text{出现X的事务数量}}{\text{总事务数量}} $
- 置信度(Confidence):
置信度是关联规则的一个度量,表示在给定前提的情况下结论发生的概率。
计算公式为:$ \text{confidence}(X \rightarrow Y) = \frac{\text{support}(X \cup Y)}{\text{support}(X)} $
例如:$ \text{confidence}(面包 \rightarrow 牛奶) $ 表示已知顾客买了面包的情况下,买牛奶的概率。
- 提升度(Lift):
提升度衡量了规则X→Y的实际发生频率与期望发生频率之间的比率,可以用来评估规则的相关性是否仅仅是由于随机性的结果。
计算公式为:$ \text{lift}(X \rightarrow Y) = \frac{\text{support}(X \cup Y)}{\text{support}(X) \times \text{support}(Y)} $
如果提升度等于1,则说明X和Y独立;大于1则说明有正相关;小于1则说明负相关。
生成过程
- 频繁项集生成:
使用算法如Apriori或FP-growth来找出所有频繁项集。
这一步通常涉及多次扫描数据库。
- 规则生成:
从频繁项集中生成候选规则,并计算每条规则的置信度。
根据用户定义的最小置信度阈值过滤出最终的关联规则。
apriori算法根据支持度计算频繁项集
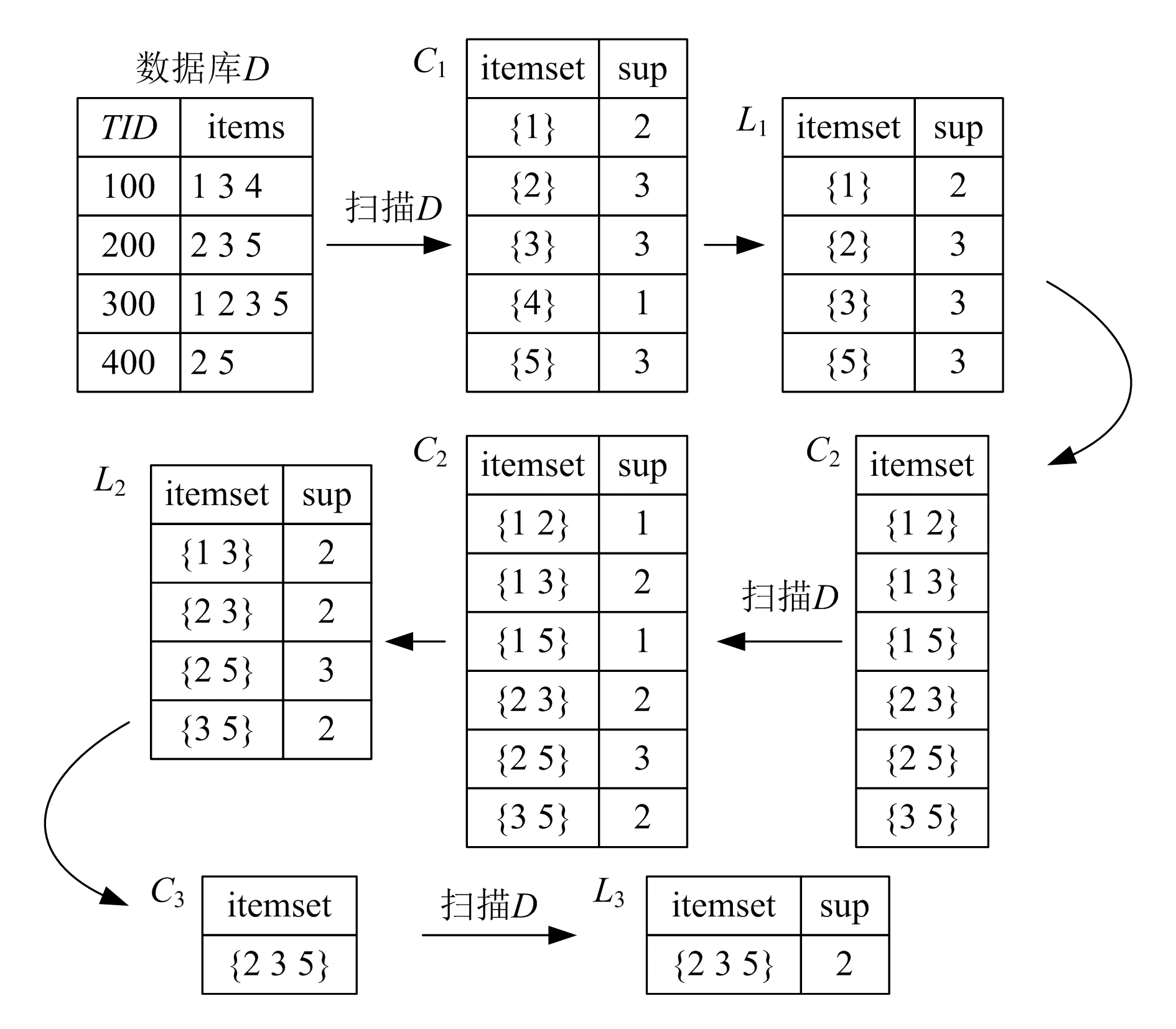
- 设置最小支持度 2
- 罗列所有物品,并计算支持度 $ C_1 $
- 过滤出 > 2,生成$ L_1 $
- 将$ L_1 两两组合,生成 两两组合,生成 两两组合,生成 C_2 $
- 计算$ C_2 $支持度
- 过滤出 > 2,生成$ L_2 $
- 将$ L_2 三三组合,生成 三三组合,生成 三三组合,生成 C_3 $
- 过滤出 > 2,生成$ L_3 $
应用场景
- 市场篮子分析:了解顾客的购买行为,帮助零售商优化商品布局、促销活动等。
- 推荐系统:根据用户的过往行为预测其可能感兴趣的商品或服务。
- 医疗领域:分析患者的疾病症状与药物之间的关联。
- 网页点击流分析:理解用户在网站上的浏览行为模式。
代码
# 分析MovieLens 电影分类中的频繁项集和关联规则
import pandas as pd
from mlxtend.frequent_patterns import apriori
from mlxtend.frequent_patterns import association_rules
# 数据加载
movies = pd.read_csv('ml-latest-small/movies.csv')
# 将genres进行one-hot编码(离散特征有多少取值,就用多少维来表示这个特征)
genres = movies.drop(labels='genres', axis=1)
movies_hot_encoded = genres.join(movies.genres.str.get_dummies(sep='|'))
pd.options.display.max_columns = 100
# print(movies_hot_encoded.head())
# 将movieId, title设置为index
movies_hot_encoded.set_index(['movieId', 'title'], inplace=True)
# 挖掘频繁项集,最小支持度为0.02
item_sets = apriori(movies_hot_encoded, use_colnames=True, min_support=0.02)
# # 按照支持度从大到小
item_sets = item_sets.sort_values(by="support", ascending=False)
# print(item_sets)
# 根据频繁项集计算关联规则,设置最小提升度为2
rules = association_rules(item_sets, metric='lift', min_threshold=2)
# 按照提升度从大到小进行排序
rules = rules.sort_values(by="lift", ascending=False)
rules.to_csv('./rules.csv')
print(rules)
完整代码
https://github.com/zz-wenzb/ai-study/tree/master/%E5%85%B3%E8%81%94%E8%A7%84%E5%88%99

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









